Citation: Xuewei Wang, Xiaohu Zhao, Fei Li, Qiang Lin, Zhenghui Hu. Sample entropy and surrogate data analysis for Alzheimer’s disease[J]. Mathematical Biosciences and Engineering, 2019, 16(6): 6892-6906. doi: 10.3934/mbe.2019345

| [1] | J. E. Cooper, On the publication of the diagnostic and statistical manual of mental disorders: Fourth edition (dsm-iv), Br. J. Psychiat., 166 (1995), 4–8. |
| [2] | M. Basso, J. Yang, L. Warren, et al., Volumetry of amygdala and hippocampus and memory performance in alzheimer's disease, Psychiat. Res., 146 (2006), 251–261. |
| [3] | C. I. Wright, B. C. Dickerson, E. Feczko, et al., A functional magnetic resonance imaging study of amygdala responses to human faces in aging and mild alzheimers disease, Biol. Psychiat., 62 (2007), 1388–1395. |
| [4] | A. Drzezga, Diagnosis of alzheimer's disease with [18f] pet in mild and asymptomatic stages, Behav. Neurol., 21 (2009), 101–115. |
| [5] | P. H. Tsai, C. Lin, J. Tsao, et al., Empirical mode decomposition based detrended sample entropy in electroencephalography for alzheimer's disease, J. Neurosci. Methods, 210 (2012), 230–237. |
| [6] | H. Zhang, C. L. Wong and P. Shi, Estimation of cardiac electrical propagation from medical image sequence, 2006 9th International Conference on Medical Image Computing and Computer-assisted Intervention (Copenhagen), Springer, (2006), 528–535. |
| [7] | K. D. Tzimourta, N. Giannakeas, A. T. Tzallas, et al., Eeg window length evaluation for the detection of alzheimer's disease over different brain regions, Brain Sci., 9 (2019), Article 81. |
| [8] | C. Coronel, H. Garn, M. Waser, et al., Quantitative eeg markers of entropy and auto mutual information in relation to mmse scores of probable alzheimer's disease patients, Entropy, 19 (2017), 1099–4300. |
| [9] | J. Poza, C. Gmez, M. Garca, et al., Spatio-Temporal fluctuations of neural dynamics in mild cognitive impairment and alzheimer's disease, Curr. Alzheimer Res., 14 (2017), 924–936. |
| [10] | N. Emanuel, B. Felix, A. Harald, et al., Regularized linear discriminant analysis of eeg features in dementia patients, Front. Aging Neurosci., 8 (2016), Article 273. |
| [11] | M. Dottori, L. Sedeo, M. C. Martorell, et al., Towards affordable biomarkers of frontotemporal dementia: a classification study via networks information sharing, Sci. Rep., 7 (2017), Article 3822. |
| [12] | N. N. Kulkarni and V. K. Bairagi, Extracting salient features for eeg-based diagnosis of alzheimer's disease using support vector machine classifier, IETE J. Res., 63 (2016), 11–22. |
| [13] | T. H. Falk, F. J. Fraga, L. Trambaiolli, et al., Eeg amplitude modulation analysis for semi-automated diagnosis of alzheimers disease, EURASIP J. Adv. Signal Process., 2014 (2014), Arti-cle 192. |
| [14] | S. Nobukawa, T. Yamanishi, H. Nishimura, et al., Atypical temporal-scale-specific fractal changes in alzheimers disease eeg and their relevance to cognitive decline, Cogn. Neurodynamics, 13 (2019), 1–11. |
| [15] | Y. Chen, L. Cai, R. Wang, et al., Dcca cross-correlation coefficients reveals the change of both synchronization and oscillation in eeg of alzheimer disease patients, Physica A, 490 (2017), 171–184. |
| [16] | H. Zhang, Z. Gao, L. Xu, et al., A meshfree representation for cardiac medical image computing, IEEE J. Transl. Eng. Health. Med., 6 (2018), 1800212. |
| [17] | H. Zhang, H. Ye and W. Huang, A meshfree method for simulating myocardial electrical activity, Comput. Math. Methods. Med., 2012 (2012), 1–16. |
| [18] | A. I. Triggiani, V. Bevilacqua, A. Brunetti, et al.,Classification of healthy subjects and alzheimer's disease patients with dementia from cortical sources of resting state eeg rhythms: a study using artificial neural networks, Front. Neurosci., 10 (2016), Article 604. |
| [19] | W. He, J. Zhu and H. Yang, Contrastive analysis of correlation dimension of eeg signals between normal and pathological groups, 2008 World Automation Congress (Hawaii), IEEE, 2008. |
| [20] | Z. Hu and P. Shi, Regularity and complexity of human electroencephalogram dynamics: ap-plications to diagnosis of alzheimers disease, 2006 18th International Conference on Pattern Recognition, IEEE CS, 2006. |
| [21] | L. Tylov, J. Kukal, V. Hubata-Vacek, et al., Unbiased estimation of permutation entropy in eeg analysis for alzheimer's disease classification, Biomed. Signal Process. Control, 39 (2018), 424–430. |
| [22] | J. S. Richman and J. R. Moorman, Physiological time-series analysis using approximate entropy and sample entropy, AM. J. Physiol-Heart C., 278 (2000), H2039–H2049. |
| [23] | C. Gomez C, F. Vaquerizo-Villar, J. Poza, et al., Bispectral analysis of spontaneous eeg activity from patients with moderate dementia due to alzheimer's disease, 2017 39th Annual International Conference of the IEEE Engineering in Medicine and Biology Society, IEEE, (2017), 422–425. |
| [24] | D. Labate, F. L. Foresta, G. Morabito, et al., Entropic measures of eeg complexity in alzheimer's disease through a multivariate multiscale approach, IEEE Sens. J., 13 (2013), 3284–3292. |
| [25] | P. Espino, S. Simons and D. Absolo, Fuzzy Entropy analysis of the electroencephalogram in patients with alzheimer's disease: Is the method superior to Sample Entropy?, Entropy, 20 (2018). |
| [26] | C. Ying and T. D. Pham, Sample entropy and regularity dimension in complexity analysis of cortical surface structure in early alzheimer's disease and aging, J. Neurosci. Methods, 215 (2013), 210–217. |
| [27] | E. V. S. Luiz and L. M. Otavio, Evaluation of physiologic complexity in time series using gener-alized sample entropy and surrogate data analysis, Chaos, 22 (2012), 479–487. |
| [28] | F. Onorati, L. T. Mainardi, F. Sirca, et al., Nonlinear analysis of pupillary dynamics, Biomed. Eng., 61 (2016), 95–106. |
| [29] | J. Theiler, E. Stephen, A. Longtin, et al., Testing for nonlinearity in time series: The method of surrogate data, Physica D, 58 (1992), 77–94. |
| [30] | P. Shang, Y. Wu and Y. Li, Modified generalized multiscale sample entropy and surrogate data analysis for financial time series, Nonlinear Dyn., 92 (2018), 1335–1350. |
| [31] | P. Shang, M. Xu and J.Huang, Modified generalized sample entropy and surrogate data analysis for stock markets, Commun. Nonlinear Sci., 35 (2016), 17–24. |
| [32] | M. Xu, D. Shang and P.Shang, Generalized sample entropy analysis for traffic signals based on similarity measure, Physica A, 474 (2017), 1–7. |
| [33] | T. Schreiber and A. Schmitz,Surrogate time series, Physica D, 142 (1999), 346–382. |
| [34] | C. P. Pan, B. Zheng, Y. Wu, et al., Detrended fluctuation analysis of human brain electroen-cephalogram, Phys. Lett. A, 329 (2004), 130–135. |
| [35] | G. Liu, Y. Zhang, Z. Hu, et al.,Complexity analysis of electroencephalogram dynamics in patients with parkinson's disease, Parkinsons Dis., 2017 (2017), 1–9. |
| [36] | D. E. Lake, J. S. Richman, M. P. Griffin, et al., Sample entropy analysis of neonatal heart rate variability, Am. J. Physiol. Regul. Integr. Comp. Physiol., 283 (2002), Article R789. |
| [37] | X. J. Tang, S. Zhuo, Y. Zhuo, et al., Entropy measures of erp recordings for dual tasks in man, Acta. Biophysica. Sinica., 21 (2005), 371–376. |
| [38] | J. Theiler and P. E. Rapp, Re-examination of the evidence for low-dimensional, nonlinear structure in the human electroencephalogram, Electroencephalogr. Clin. Neurophysiol. Suppl. , 98 (1996), 213–222. |
| [39] | L. Gemma, I. Dmytro, P. Aleksandra, et al., Surrogate data for hypothesis testing of physical systems, Phys. Rep., 748 (2018), 1–72. |
| [40] | W. Chantarangsi, W. Liu, F. Bretz, et al., Normal probability plots with confidence, Biom. J., 57 (2015), 52–63. |
| [41] | D. Absolo, J. Escudero, R. Hornero, et al., Approximate entropy and auto mutual information analysis of the electroencephalogram in Alzheimers disease patients, Med. Biol. Eng. Comput., 46 (2008), 1019–1028. |
| [42] | D. Abasolo, R. Hornero, P. Espino, et al., Entropy analysis of the eeg background activity in alzheimer's disease patients, Physiol. Meas., 27 (2006), 241–253. |
| [43] | P. Alberto, G. R. Tomaso, E. Tobaldini, et al., Progressive decrease of heart period variability entropy-based complexity during graded head-up tilt, J. Appl. Physiol., 103 (2007), 1143–1149. |
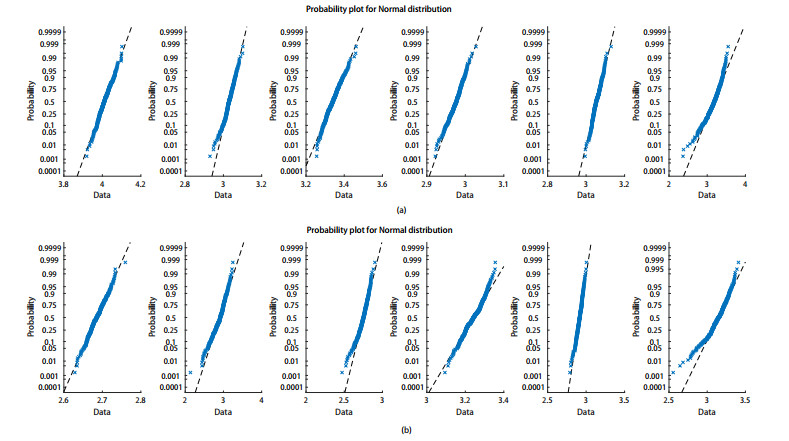
Figures(5) / Tables(4)

Xuewei Wang, Xiaohu Zhao, Fei Li, Qiang Lin, Zhenghui Hu. Sample entropy and surrogate data analysis for Alzheimer’s disease[J]. Mathematical Biosciences and Engineering, 2019, 16(6): 6892-6906. doi: 10.3934/mbe.2019345







 DownLoad:
DownLoad: