Citation: Aurelie Akossi, Gerardo Chowell-Puente, Alexandra Smirnova. Numerical study of discretization algorithms for stable estimation of disease parameters and epidemic forecasting[J]. Mathematical Biosciences and Engineering, 2019, 16(5): 3674-3693. doi: 10.3934/mbe.2019182

| [1] | N. Tuncer, C. Mohanakumar, S. Swanson, et al., E cacy of control measures in the control of Ebola, Liberia 2014–2015, J. Biol. Dynam., 12 (2018), 913–937. |
| [2] | N. Tuncer, M. Marctheva, B. LaBarre, et al., Structural and practical identifiability analysis of ZIKA epidemiological models, B. Math. Biol., 80 (2018), 2209–2241. |
| [3] | G. Chowell, L. Sattenspiel, S. Bansal, et al., Mathematical models to characterize early epidemic growth: a review, Phys. life rev., 18 (2016), 66–97. |
| [4] | A. B. Bakunshinsky and M. Yu. Kokurin, Iterative methods for Ill-Posed Operator Equations with Smooth Operators, Springer, Dordrecht, Great Britain, 2004. |
| [5] | H. Engl, M. Hanke and A. Neubauer, Regularization of Inverse Problems, Kluwer Academic Pub-lisher, Dordecht, Boston, London, 1996. |
| [6] | J. E. Dennis and R. B. Schnabel, Numerical Methods for Unconstrained Optimization and Nonlin-ear Equations, Prentice-Hall, Englewood Cli s, New Jersey, 1983. |
| [7] | J. Nocedal and S. J. Wright, Numerical Optimization, Springer-Verlag, New York, 1999. |
| [8] | A. Smirnova, R. Renaut and T. Khan, Convergence and applications of a modified iteratively regularized Gauss-Newton algorithm, Inverse Probl., 23 (2007), 1546–1563. |
| [9] | R. M. Anderson and R. M. May, Infectious Diseases of Humans: Dynamics and Control, Oxford University Press Inc, New York, 1992. |
| [10] | C. de Boor, A Practical Guide to Splines, Springer-Verlag, 1978. |
| [11] | B. Efron and R. Tibshirani, Bootstrap methods for standard errors, confidence intervals, and other measures of statistical accuracy, Stat. Sci., 1 (1986), 54–75. |
| [12] | G. Chowell, C. E. Ammon, N.W. Hengartner, et. al., Transmission dynamics of the great influenza pandemic of 1918 in Geneva, Switzerland: Assessing the e ects of hypothetical interventions, J. Theor. Biol, 241 (2006), 193–204. |
| [13] | B. Kaltenbacher, A. Neubauer and O. Scherzer, Iterative regularization methods for nonlinear illposed problems, Radon Series on Computational and Applied Mathematics, 6, Walter de Gruyter, Berlin, 2008. |
| [14] | A. Sirmnova, B. Sirb and G. Chowell, On stable parameter estimation and forecasting in epidemi-ology by the Levenberg-Marquardt Algorithm with Broyden's rank-one updates for the Jacobian operator, B. Math. Biol., 2019. |
| [15] | G. Chowell, M. MacLachan and E. P. Fenichel, Accounting for behavioral responses during a flu epidemic using home television viewing, BMC Infect. Dis., 15 (2015), 21. |
| [16] | P. Guo, Q. Zhang, Y. Chen, et al., An ensemble forecast model of dengue in Guangzhou, China using climate and social media surveillance data, Sci. Total Environ., 647 (2019), 752–762. |
| [17] | L. Kim, S. M. Fast and N. Markuzon, Incorporating media data into a model of infectious disease transmission, PLoS One 14 (2019), e0197646. |
| [18] | C. A Marques-Toledo, C. M. Degener, L. Vinhal, et al., Dengue prediction by the web: Tweets are a useful tool for estimating and forecasting Dengue at country and city level, PLoS Negl. Trop. Dis., 11 (2017), e0005729. |
| [19] | Y. Teng, D. Bi, G. Xie, et al., Dynamic forecasting of Zika epidemics using google trends, PLoS One, 12 (2017), e0165085. |

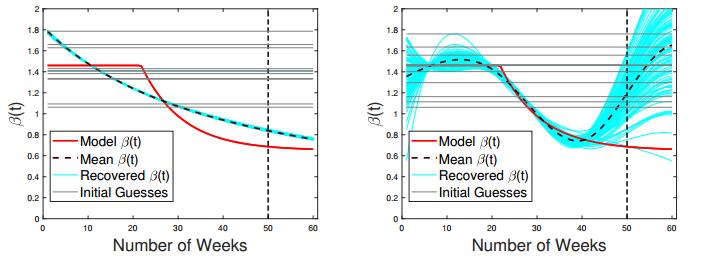
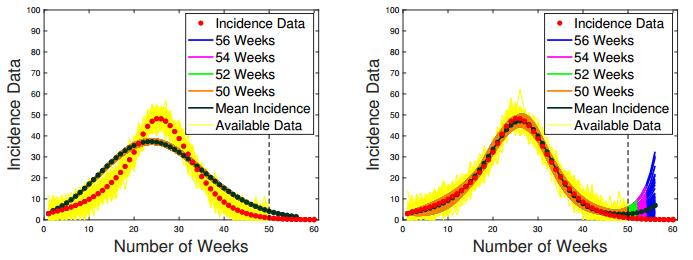
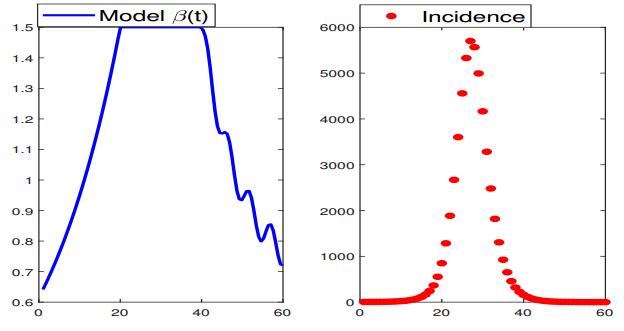
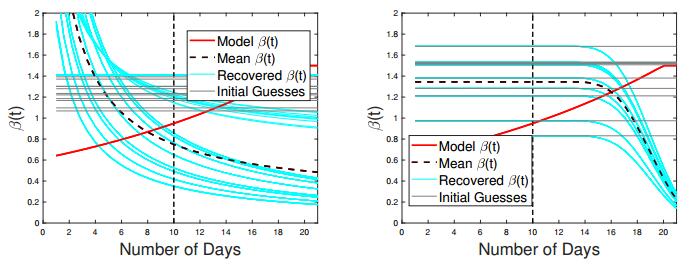
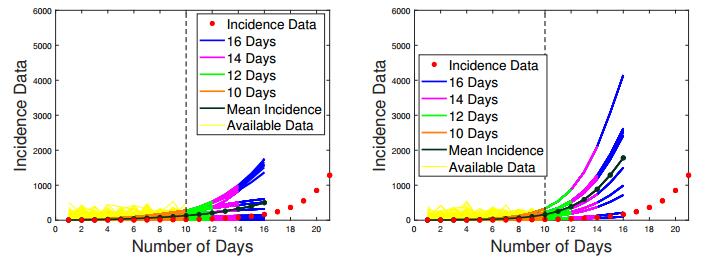
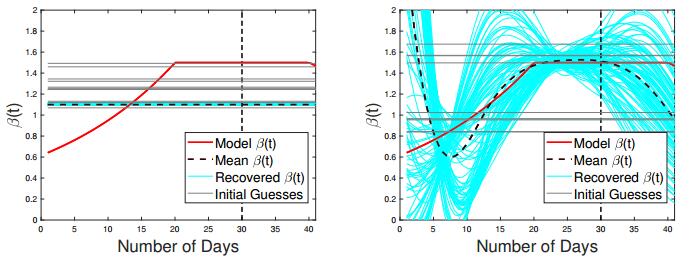
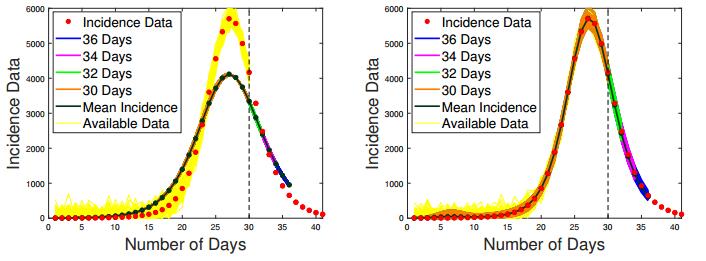
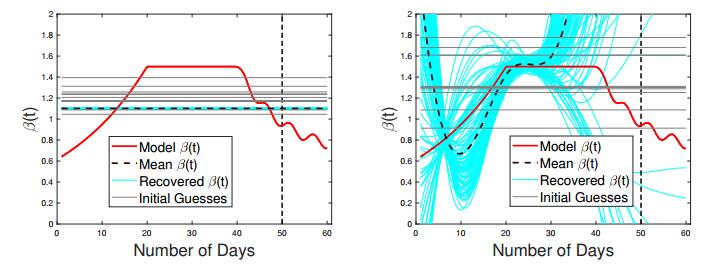
Figures(24) / Tables(3)

Aurelie Akossi, Gerardo Chowell-Puente, Alexandra Smirnova. Numerical study of discretization algorithms for stable estimation of disease parameters and epidemic forecasting[J]. Mathematical Biosciences and Engineering, 2019, 16(5): 3674-3693. doi: 10.3934/mbe.2019182







 DownLoad:
DownLoad: