Citation: Andreas Widder. On the usefulness of set-membership estimation in the epidemiology of infectious diseases[J]. Mathematical Biosciences and Engineering, 2018, 15(1): 141-152. doi: 10.3934/mbe.2018006

| [1] | [ C. L. Althaus, Estimating the reproduction number of Ebola virus (EBOV) during the 2014 outbreak in West Africa, PLOS Currents Outbreaks, (2014). |
| [2] | [ C. L. Althaus,N. Low,E. O. Musa,F. Shuaib,S. Gsteiger, Ebola virus disease outbreak in Nigeria: Transmission dynamics and rapid control, Epidemics, 11 (2015): 80-84. |
| [3] | [ H. Andersson and T. Britton, Stochastic Epidemic Models and Their Statistical Analysis, Lecture Notes in Statistics, 151. Springer-Verlag, New York, 2000. |
| [4] | [ R. Baier,M. Gerdts, A computational method for non-convex reachable sets using optimal control, in 2009 European Control Conference (ECC), IEEE, null (2009): 97-102. |
| [5] | [ D. P. Bertsekas, Dynamic Programming and Optimal Control, Athena Scientific, 1995. |
| [6] | [ A. Bhargava,F. Docquier, HIV pandemic, medical brain drain, and economic development in Sub-Saharan Africa, The World Bank Economic Review, 22 (2008): 345-366. |
| [7] | [ A. Blake,M. T. Sinclair,G. Sugiyarto, Quantifying the impact of foot and mouth disease on tourism and the UK economy, Tourism Economics, 9 (2003): 449-465. |
| [8] | [ A. Capaldi,S. Behrend,B. Berman,J. Smith,J. Wright,A. L. Lloyd, Parameter estimation and uncertainty quantication for an epidemic model, Mathematical Biosciences and Engineering, 9 (2012): 553-576. |
| [9] | [ O. Diekmann, H. Heesterbeek and T. Britton, Mathematical Tools for Understanding Infectious Disease Dynamics, Princeton University Press, 2013. |
| [10] | [ J. Hsu, Multiple Comparisons: Theory and Methods, CRC Press, 1996. |
| [11] | [ M. J. Keeling and P. Rohani, Modeling Infectious Diseases in Humans and Animals, Princeton University Press, 2008. |
| [12] | [ A. B. Kurzhanski and P. Varaiya, Dynamics and Control of Trajectory Tubes, Springer, 2014. |
| [13] | [ P. E. Lekone,B. F. Finkenstädt, Statistical inference in a stochastic epidemic SEIR model with control intervention: Ebola as a case study, Biometrics, 62 (2006): 1170-1177. |
| [14] | [ N.-A. M. Molinari,I. R. Ortega-Sanchez,M. L. Messonnier,W. W. Thompson,P. M. Wortley,E. Weintraub,C. B. Bridges, The annual impact of seasonal influenza in the US: measuring disease burden and costs, Vaccine, 25 (2007): 5086-5096. |
| [15] | [ E. Polak, Computational Methods in Optimization: A Unified Approach, vol. 77, Academic Press, New York-London, 1971. |
| [16] | [ E. D. Sontag, Mathematical Control Theory: Deterministic Finite Dimensional Systems, Second edition. Texts in Applied Mathematics, 6. Springer-Verlag, New York, 1998. |
| [17] | [ M. R. Thomas, G. Smith, F. H. Ferreira, D. Evans, M. Maliszewska, M. Cruz, K. Himelein and M. Over, The economic impact of Ebola on Sub-Saharan Africa: Updated estimates for 2015, World Bank Group. |
| [18] | [ T. Toni,D. Welch,N. Strelkowa,A. Ipsen,M. P. Stumpf, Approximate Bayesian computation scheme for parameter inference and model selection in dynamical systems, Journal of the Royal Society Interface, 6 (2009): 187-202. |
| [19] | [ T. Tsachev,V. M. Veliov,A. Widder, Set-membership estimation for the evolution of infectious diseases in heterogeneous populations, Journal of Mathematical Biology, 74 (2017): 1081-1106. |
| [20] | [ V. Veliov,A. Widder, Modelling and estimation of infectious diseases in a population with heterogeneous dynamic immunity, Journal of Biological Dynamics, 10 (2016): 457-476. |
| [21] | [ A. Widder, Matlab files for set-membership estimation, Zenodo, 2016. |
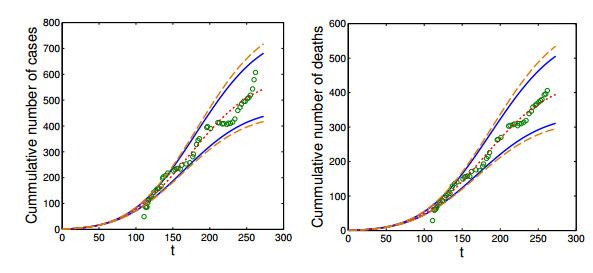
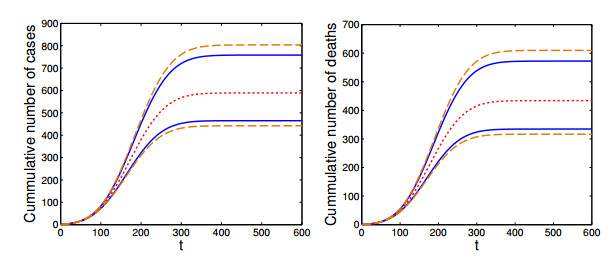
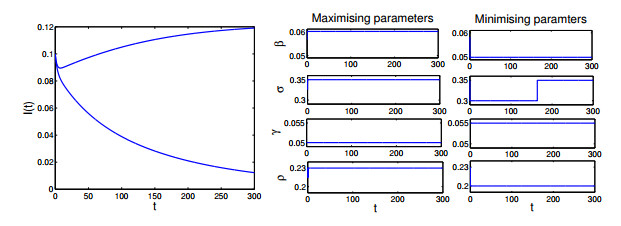
Figures(3)

Andreas Widder. On the usefulness of set-membership estimation in the epidemiology of infectious diseases[J]. Mathematical Biosciences and Engineering, 2018, 15(1): 141-152. doi: 10.3934/mbe.2018006







 DownLoad:
DownLoad: