The monotone variational inequalities are being widely used as mathematical tools for studying optimal control problems and convex programming. In this paper, we propose a new prediction-correction method for monotone variational inequalities with linear constraints. The method consists of two procedures. The first procedure (prediction) utilizes projections to generate a predictor. The second procedure (correction) produces the new iteration via some minor computations. The main advantage of the method is that its main computational effort only depends on evaluating the resolvent mapping of the monotone operator, and its primal and dual step sizes can be enlarged. We prove the global convergence of the method. Numerical results are provided to demonstrate the efficiency of the method.
Citation: Feng Ma, Bangjie Li, Zeyan Wang, Yaxiong Li, Lefei Pan. A prediction-correction based proximal method for monotone variational inequalities with linear constraints[J]. AIMS Mathematics, 2023, 8(8): 18295-18313. doi: 10.3934/math.2023930
The monotone variational inequalities are being widely used as mathematical tools for studying optimal control problems and convex programming. In this paper, we propose a new prediction-correction method for monotone variational inequalities with linear constraints. The method consists of two procedures. The first procedure (prediction) utilizes projections to generate a predictor. The second procedure (correction) produces the new iteration via some minor computations. The main advantage of the method is that its main computational effort only depends on evaluating the resolvent mapping of the monotone operator, and its primal and dual step sizes can be enlarged. We prove the global convergence of the method. Numerical results are provided to demonstrate the efficiency of the method.

| [1] |
R. Rockafellar, J. Sun, Solving monotone stochastic variational inequalities and complementarity problems by progressive hedging, Math. Program., 174 (2019), 453–471. https://doi.org/10.1007/s10107-018-1251-y doi: 10.1007/s10107-018-1251-y

|
| [2] | D. Bertsekas, E. Gafni, Projection methods for variational inequalities with application to the traffic assignment problem, In: Nondifferential and variational techniques in optimization, Berlin: Springer, 1982, 39–159. https://doi.org/10.1007/BFb0120965 |
| [3] |
S. Dafermos, Traffic equilibrium and variational inequalities, Transport. Sci., 14 (1980), 42–54. https://doi.org/10.1287/trsc.14.1.42 doi: 10.1287/trsc.14.1.42
|
| [4] | E. Gorbunov, N. Loizou, G. Gidel, Extragradient method: O (1/k) last-iterate convergence for monotone variational inequalities and connections with cocoercivity, Proceedings of The 25th International Conference on Artificial Intelligence and Statistics, 2022,366–402. |
| [5] | G. Gu, J. Yang, Tight ergodic sublinear convergence rate of the relaxed proximal point algorithm for monotone variational inequalities, J. Optim. Theory Appl., in press. https://doi.org/10.1007/s10957-022-02058-3 |
| [6] |
B. He, W. Xu, H. Yang, X. Yuan, Solving over-production and supply-guarantee problems in economic equilibria, Netw. Spat. Econ., 11 (2011), 127–138. https://doi.org/10.1007/s11067-008-9095-2 doi: 10.1007/s11067-008-9095-2
|
| [7] |
Y. Gao, W. Zhang, An alternative extrapolation scheme of PDHGM for saddle point problem with nonlinear function, Comput. Optim. Appl., 85 (2023), 263–291. https://doi.org/10.1007/s10589-023-00453-8 doi: 10.1007/s10589-023-00453-8
|
| [8] |
X. Zhao, J. Yao, Y. Yao, A nonmonotone gradient method for constrained multiobjective optimization problems, J. Nonlinear Var. Anal., 6 (2022), 693–706. https://doi.org/10.23952/jnva.6.2022.6.07 doi: 10.23952/jnva.6.2022.6.07
|
| [9] |
S. Bubeck, Convex optimization: algorithms and complexity, Found. Trends Mach. Le., 8 (2015), 231–357. https://doi.org/10.1561/2200000050 doi: 10.1561/2200000050
|
| [10] | T. Chan, S. Esedoglu, F. Park, A. Yip, Total variation image restoration: overview and recent developments, In: Handbook of mathematical models in computer vision, Boston: Springer, 2006, 17–31. https://doi.org/10.1007/0-387-28831-7_2 |
| [11] |
G. Kutyniok, Theory and applications of compressed sensing, GAMM-Mitteilungen, 36 (2013), 79–101. https://doi.org/abs/10.1002/gamm.201310005 doi: 10.1002/gamm.201310005
|
| [12] | E. Ryu, W. Yin, Large-scale convex optimization: algorithms & analyses via monotone operators, Cambridge: Cambridge University Press, 2022. https://doi.org/10.1017/9781009160865 |
| [13] |
N. Parikh, S. Boyd, Proximal algorithms, Foundations and Trends® in Optimization, 1 (2014), 127–239. https://doi.org/10.1561/2400000003 doi: 10.1561/2400000003
|
| [14] |
M. Hestenes, Multiplier and gradient methods, J. Optim. Theory Appl., 4 (1969), 303–320. https://doi.org/10.1007/BF00927673 doi: 10.1007/BF00927673
|
| [15] | M. Powell, A method for nonlinear constraints in minimization problems, In: Optimization, New York: Academic Press, 1969,283–298. |
| [16] |
B. He, H. Yang, S. Wang, Alternating direction method with self-adaptive penalty parameters for monotone variational inequalities, J. Optim. Theory Appl., 106 (2000), 337–356. https://doi.org/10.1023/A:1004603514434 doi: 10.1023/A:1004603514434
|
| [17] |
G. Qian, D. Han, L. Xu, H. Yang, Solving nonadditive traffic assignment problems: a self-adaptive projection-auxiliary problem method for variational inequalities, J. Ind. Manag. Optim., 9 (2013), 255–274. https://doi.org/10.3934/jimo.2013.9.255 doi: 10.3934/jimo.2013.9.255
|
| [18] |
X. Fu, B. He, Self-adaptive projection-based prediction-correction method for constrained variational inequalities, Front. Math. China, 5 (2010), 3–21. https://doi.org/10.1007/s11464-009-0045-1 doi: 10.1007/s11464-009-0045-1
|
| [19] |
X. Fu, A general self-adaptive relaxed-PPA method for convex programming with linear constraints, Abstr. Appl. Anal., 2013 (2013), 1–13. https://doi.org/10.1155/2013/492305 doi: 10.1155/2013/492305
|
| [20] |
F. Ma, M. Ni, W. Tong, X. Wu, Matrix completion via extended linearized augmented Lagrangian method of multipliers, Proceedings of International Conference on Informative and Cybernetics for Computational Social Systems, 2015, 45–49. https://doi.org/10.1109/ICCSS.2015.7281147 doi: 10.1109/ICCSS.2015.7281147
|
| [21] |
Y. Shen, H. Wang, New augmented Lagrangian-based proximal point algorithm for convex optimization with equality constraints, J. Optim. Theory Appl., 171 (2016), 251–261. https://doi.org/10.1007/s10957-016-0991-1 doi: 10.1007/s10957-016-0991-1
|
| [22] |
B. He, L. Liao, X. Wang, Proximal-like contraction methods for monotone variational inequalities in a unified framework Ⅱ: general methods and numerical experiments, Comput. Optim. Appl., 51 (2012), 681–708. https://doi.org/10.1007/s10589-010-9373-z doi: 10.1007/s10589-010-9373-z
|
| [23] |
B. He, F. Ma, X. Yuan, Optimal proximal augmented Lagrangian method and its application to full jacobian splitting for multi-block separable convex minimization problems, IMA J. Numer. Anal., 40 (2020), 1188–1216. https://doi.org/10.1093/imanum/dry092 doi: 10.1093/imanum/dry092
|
| [24] |
G. Gu, B. He, X. Yuan, Customized proximal point algorithms for linearly constrained convex minimization and saddle-point problems: a unified approach, Comput. Optim. Appl., 59 (2014), 135–161. https://doi.org/10.1007/s10589-013-9616-x doi: 10.1007/s10589-013-9616-x
|
| [25] |
B. He, X. Yuan, W. Zhang, A customized proximal point algorithm for convex minimization with linear constraints, Comput. Optim. Appl., 56 (2013), 559–572. https://doi.org/10.1007/s10589-013-9564-5 doi: 10.1007/s10589-013-9564-5
|
| [26] |
F. Ma, On relaxation of some customized proximal point algorithms for convex minimization: from variational inequality perspective, Comput. Optim. Appl., 73 (2019), 871–901. https://doi.org/10.1007/s10589-019-00091-z doi: 10.1007/s10589-019-00091-z
|
| [27] |
F. Ma, M. Ni, A class of customized proximal point algorithms for linearly constrained convex optimization, Comput. Appl. Math., 37 (2018), 896–911. https://doi.org/10.1007/s40314-016-0371-3 doi: 10.1007/s40314-016-0371-3
|
| [28] |
B. He, F. Ma, X. Yuan, Optimally linearizing the alternating direction method of multipliers for convex programming, Comput. Optim. Appl., 75 (2020), 361–388. https://doi.org/10.1007/s10589-019-00152-3 doi: 10.1007/s10589-019-00152-3
|
| [29] |
J. Liu, J. Chen, J. Zheng, X. Zhang, Z. Wan, A new accelerated positive-indefinite proximal ADMM for constrained separable convex optimization problems, J. Nonlinear Var. Anal., 6 (2022), 707–723. https://doi.org/10.23952/jnva.6.2022.6.08 doi: 10.23952/jnva.6.2022.6.08
|
| [30] |
B. He, F. Ma, S. Xu, X. Yuan, A generalized primal-dual algorithm with improved convergence condition for saddle point problems, SIAM J. Imaging Sci., 15 (2022), 1157–1183. https://doi.org/10.1137/21M1453463 doi: 10.1137/21M1453463
|
| [31] |
F. Ma, Y. Bi, B. Gao, A prediction-correction-based primal-dual hybrid gradient method for linearly constrained convex minimization, Numer. Algor., 82 (2019), 641–662 https://doi.org/10.1007/s11075-018-0618-8 doi: 10.1007/s11075-018-0618-8
|
| [32] |
S. Xu, A dual-primal balanced augmented Lagrangian method for linearly constrained convex programming, J. Appl. Math. Comput., 69 (2023), 1015–1035. https://doi.org/10.1007/s12190-022-01779-y doi: 10.1007/s12190-022-01779-y
|
| [33] | E. Blum, W. Oettli, Mathematische optimierung: grundlagen und verfahren, Berlin: Springer, 1975. |
| [34] |
P. Mahey, A. Lenoir, A survey on operator splitting and decomposition of convex programs, RAIRO-Oper. Res., 51 (2017), 17–41. https://doi.org/10.1051/ro/2015065 doi: 10.1051/ro/2015065
|
| [35] |
B. He, A uniform framework of contraction methods for convex optimization and monotone variational inequality, Scientia Sinica Mathematica, 48 (2018), 255. https://doi.org/10.1360/N012017-00034 doi: 10.1360/N012017-00034
|
| [36] |
J. Yang, X. Yuan, Linearized augmented Lagrangian and alternating direction methods for nuclear norm minimization, Math. Comput., 82 (2013), 301–329. https://doi.org/10.1090/S0025-5718-2012-02598-1 doi: 10.1090/S0025-5718-2012-02598-1
|
| [37] |
S. Boyd, N. Parikh, E. Chu, B. Peleato, J. Eckstein, Distributed optimization and statistical learning via the alternating direction method of multipliers, Found. Trends Mach. Le., 3 (2011), 1–122. https://doi.org/10.1561/2200000016 doi: 10.1561/2200000016
|
| [38] | G. Ye, Y. Chen, X. Xie, Efficient variable selection in support vector machines via the alternating direction method of multipliers, Proceedings of the 14th International Conference on Artificial Intelligence and Statistics, 2011,832–840. |

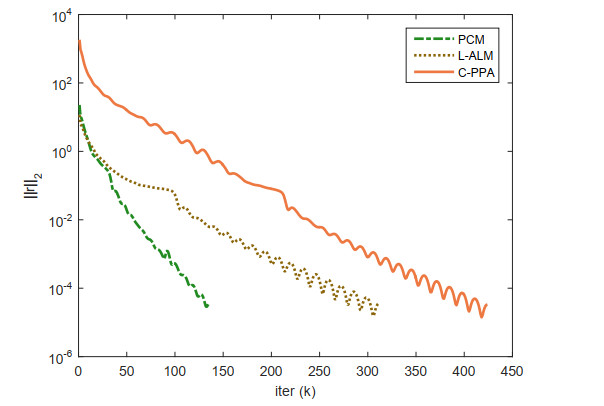
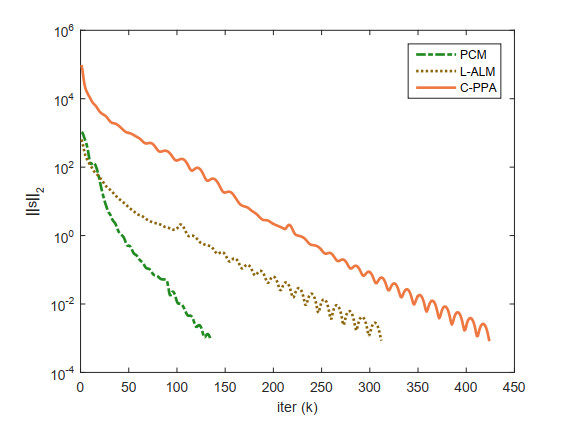
Figures(3) / Tables(6)

Feng Ma, Bangjie Li, Zeyan Wang, Yaxiong Li, Lefei Pan. A prediction-correction based proximal method for monotone variational inequalities with linear constraints[J]. AIMS Mathematics, 2023, 8(8): 18295-18313. doi: 10.3934/math.2023930







 DownLoad:
DownLoad: