Citation: Xin Liang, Xingfa Zhang, Yuan Li, Chunliang Deng. Daily nonparametric ARCH(1) model estimation using intraday high frequency data[J]. AIMS Mathematics, 2021, 6(4): 3455-3464. doi: 10.3934/math.2021206

| [1] | R. F. Engle, Autoregressive conditional heteroskedasticity with estimates of the variance of UK inflation, Economics, 50 (1982), 987–1008. |
| [2] |
T. Bollerslev, Generalized autoregressive conditional heteroskedasticity, J. Econometrics, 31 (1986), 307–327. doi: 10.1016/0304-4076(86)90063-1

|
| [3] |
D. B. Nelson, Conditional heteroskedasticity in asset returns: A new approach, Econometrica: J. Econometric Soc., 59 (1991), 347–370. doi: 10.2307/2938260
|
| [4] |
L. Hentschel, All in the family Nesting symmetric and asymmetric GARCH models, J. Financ. Econ., 39 (1995), 71–104. doi: 10.1016/0304-405X(94)00821-H
|
| [5] |
C. Kl$\ddot{u}$ppelberg, A. Lindner, R. Maller, A continuous-time GARCH process driven by a L$\acute{e}v$y process: Stationarity and second-order behaviour, J. Appl. Probab., 41 (2004), 601–622. doi: 10.1239/jap/1091543413
|
| [6] |
J. Pan, H. Wang, H. Tong, Estimation and tests for power-transformed and threshold GARCH models, J. Econometrics, 142 (2008), 352–378. doi: 10.1016/j.jeconom.2007.06.004
|
| [7] |
Y. Zou, L. Yu, K. He, Estimating portfolio value at risk in the electricity markets using an entropy optimized BEMD approach, Entropy, 17 (2015), 4519–4532. doi: 10.3390/e17074519
|
| [8] |
T. Tetsuya, Volatility estimation using a rational GARCH model, Quant. Finance Econ., 2 (2018), 127–136. doi: 10.3934/QFE.2018.1.127
|
| [9] |
D. G. Davide, Forecasting volatility using combination across estimation windows: An application to S&P500 stock market index, Math. Biosci. Eng., 16 (2019), 7195–7216. doi: 10.3934/mbe.2019361
|
| [10] |
A. G. Samuel, Modelling the volatility of Bitcoin returns using GARCH models, Quant. Finance Econ., 3 (2019), 739–753. doi: 10.3934/QFE.2019.4.739
|
| [11] | X. Zhang, R. Zhang, Y. Li, S. Q. Ling, LADE-based inferences for autoregressive models with heavy-tailed G-GARCH(1, 1) noise, J. Econometrics, 2020. Available from: https://doi.org/10.1016/j.jeconom.2020.06.011. |
| [12] |
O. Linton, J. Wu, A coupled component DCS-EGARCH model for intraday and overnight volatility, J. Econometrics, 217 (2020), 176–201. doi: 10.1016/j.jeconom.2019.12.015
|
| [13] |
R. F. Engle, V. K. Ng, Measuring and testing the impact of news on volatility, J. Finance., 48 (1993), 1749–1778. doi: 10.1111/j.1540-6261.1993.tb05127.x
|
| [14] |
W. Härdle, A. Tsybakov, Local polynomial estimation of the volatility function in nonparametric autoregression, J. Econometrics, 81 (1997), 223–242. doi: 10.1016/S0304-4076(97)00044-4
|
| [15] |
P. Bühlmann, A. J. McNeil, An algorithm for nonparametric GARCH modelling, Comput. Stat. Data Anal., 40 (2002), 665–683. doi: 10.1016/S0167-9473(02)00080-4
|
| [16] |
L. J. Yang, A semiparametric GARCH model for foreign exchange volatility, J. Econometrics, 130 (2006), 365–384. doi: 10.1016/j.jeconom.2005.03.006
|
| [17] |
F. Giordano, L. M. Parrella, Efficient nonparametric estimation and inference for the volatility function, Statistics, 53 (2019), 770–791. doi: 10.1080/02331888.2019.1615066
|
| [18] | X. Chen, Z. Huang, Y. Yi, Efficient estimation of multivariate semi-nonparametric GARCH filtered copula models, J. Econometrics, 2020. Available from: https://doi.org/10.1016/j.jeconom.2020.07.012. |
| [19] |
M. P. Visser, Garch parameter estimation using high-frequencydata, J. Financ. Econometrics, 9 (2011), 162–197. doi: 10.1093/jjfinec/nbq017
|
| [20] |
J. S. Huang, W. Q. Wu, Z. Chen, J. J. Zhou, Robust M-estimate of GJR model with high frequency data, Acta Math. Appl. Sin., 31 (2015), 591–606. doi: 10.1007/s10255-015-0488-y
|
| [21] |
M. Wang, Z. Chen, C. D. Wang, Composite quantile regression for GARCH models using high-frequency data, Econometrics Stat., 7 (2018), 115–133. doi: 10.1016/j.ecosta.2016.11.004
|
| [22] |
C. Deng, X. Zhang, Y. Li, Q. Xiong, Garch model test using high-frequency data, Mathematics, 8 (2020), 1922. doi: 10.3390/math8111922
|
| [23] | J. Q. Fan, Q. W. Yao, Nonlinear Time Series: Nonparametric and Parametric Methods, New York: Springer, 2005. |
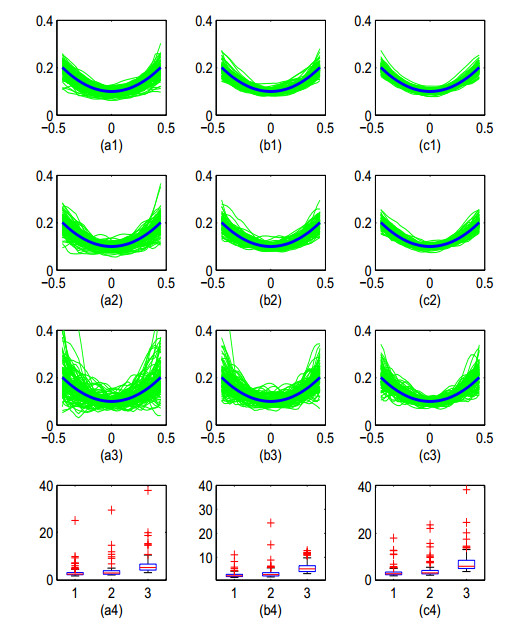
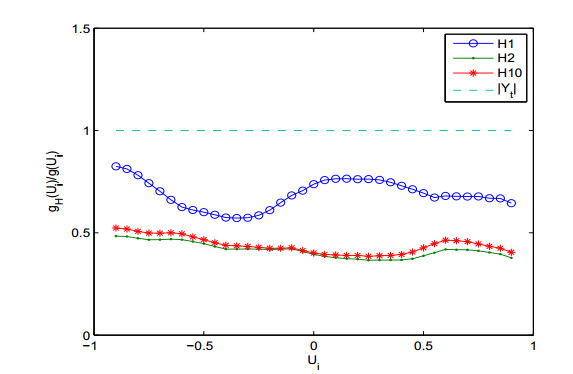
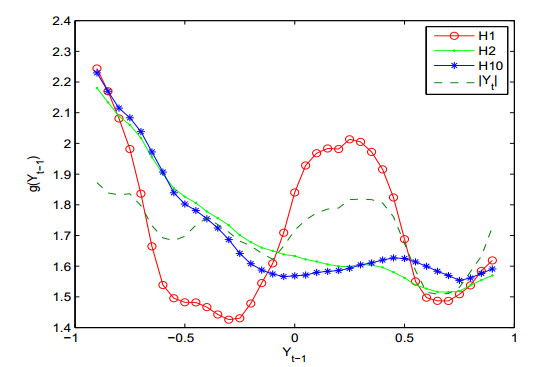
Figures(3)

Xin Liang, Xingfa Zhang, Yuan Li, Chunliang Deng. Daily nonparametric ARCH(1) model estimation using intraday high frequency data[J]. AIMS Mathematics, 2021, 6(4): 3455-3464. doi: 10.3934/math.2021206







 DownLoad:
DownLoad: