Citation: Hui Sun, Zhongyang Sun, Ya Huang. Equilibrium investment and risk control for an insurer with non-Markovian regime-switching and no-shorting constraints[J]. AIMS Mathematics, 2020, 5(6): 6996-7013. doi: 10.3934/math.2020449

| [1] | T. Björk, A. Murgoci, A General Theory of Markovian Time Inconsistent Stochastic Control Problems, SSRN Electronic Journal, 2010. |
| [2] |
T. Björk, A. Murgoci, X. Y. Zhou, Mean-variance portfolio optimization with state-dependent risk aversion, Math. Financ., 24 (2014), 1-24. doi: 10.1111/j.1467-9965.2011.00515.x

|
| [3] |
P. Chen, H. Yang, Markowitz's mean-variance asset-liability management with regime switching: A multi-period model, Appl. Math. Finance, 18 (2011), 29-50. doi: 10.1080/13504861003703633
|
| [4] |
P. Chen, H. Yang, G. Yin, Markowitz's mean-variance asset-liability management with regime switching: A continuous-time model, Insur. Math. Econ., 43 (2008), 456-465. doi: 10.1016/j.insmatheco.2008.09.001
|
| [5] | R. J. Elliott, L. Aggoun, J. B. Moore, Hidden Markov Models: Estimation and Control, Springer Science & Business Media, 1995. |
| [6] | J. Grandell, Aspects of Risk Theory, New York : Springer, 1991. |
| [7] |
Y. Hu, H. Jin, X.Y. Zhou, Time-inconsistent stochastic linear-quadratic control, SIAM J. Control Optim., 50 (2012), 1548-1572. doi: 10.1137/110853960
|
| [8] | Y. Hu, J. Huang, X. Li, Equilibrium for time-inconsistent stochastic linear-quadratic control under constraint, arXiv preprint arXiv:1703.09415, 2017. |
| [9] |
Y. Hu, H. Jin, X.Y. Zhou, Time-inconsistent stochastic linear-quadratic control: Characterization and uniqueness of equilibrium, SIAM J. Control Optim., 55 (2017), 1261-1279. doi: 10.1137/15M1019040
|
| [10] | N. Kazamaki, Continuous Exponential Martingales and BMO, Berlin: Springer, 1994. |
| [11] | H. Markowitz, Portfolio selection, J. Finance, 7 (1952), 77-91. |
| [12] |
Y. Shen, J. Wei, Q. Zhao, Mean-variance asset-liability management problem under nonMarkovian regime-switching models, Appl. Math. Opt., 81 (2020), 859-897. doi: 10.1007/s00245-018-9523-8
|
| [13] |
Z. Sun, J. Guo, Optimal mean-variance investment and reinsurance problem for an insurer with stochastic volatility, Math. Method. Oper. Res., 88 (2018), 59-79. doi: 10.1007/s00186-017-0628-7
|
| [14] |
Z. Sun, X. Guo, Equilibrium for a time-inconsistent stochastic linear-quadratic control system with jumps and its application to the mean-variance problem, J. Optimiz. Theory App., 181 (2019), 383-410. doi: 10.1007/s10957-018-01471-x
|
| [15] | Z. Sun, K. C. Yuen, J. Guo, A BSDE approach to a class of dependent risk model of meanvariance insurers with stochastic volatility and no-short selling, J. Comput. Appl. Math., 366 (2020), 112413. |
| [16] |
Z. Sun, X. Zhang, K. C. Yuen, Mean-variance asset-liability management with affine diffusion factor process and a reinsurance option, Scand. Actuar. J., 2020 (2020), 218-244. doi: 10.1080/03461238.2019.1658619
|
| [17] | Y. Tian, J. Guo, Z. Sun, Optimal mean-variance reinsurance in a financial market with stochastic rate of return, J. Ind. Manag. Optim., doi: 10.3934/jimo.2020051, 2020. |
| [18] |
T. Wang, J. Wei, Mean-variance portfolio selection under a non-Markovian regime-switching model, J. Comput. Appl. Math., 350 (2019), 442-455. doi: 10.1016/j.cam.2018.10.040
|
| [19] |
T. Wang, Z. Jin, J. Wei, Mean-variance portfolio selection under a non-Markovian regimeswitching model: Time-consistent solutions, SIAM J. Control Optim., 57 (2019), 3249-3271. doi: 10.1137/18M1186423
|
| [20] |
J. Wei, K. C. Wong, S. C. P. Yam, et al. Markowitz's mean-variance asset-liability management with regime switching: A time-consistent approach, Insur. Math. Econ., 53 (2013), 281-291. doi: 10.1016/j.insmatheco.2013.05.008
|
| [21] |
J. Wei, T. Wang, Time-consistent mean-variance asset-liability management with random coefficients, Insur. Math. Econ., 77 (2017), 84-96. doi: 10.1016/j.insmatheco.2017.08.011
|
| [22] |
Y. Zeng, Z. Li, Optimal time-consistent investment and reinsurance policies for mean-variance insurers, Insur. Math. Econ., 49 (2011), 145-154. doi: 10.1016/j.insmatheco.2011.01.001
|
| [23] | L. Zhang, R. Wang, J. Wei, Optimal mean-variance reinsurance and investment strategy with constraints in a non-Markovian regime-switching model, Stat. Theory Related Fields., doi: 10.1080/24754269.2020.1719356, 2020. |
| [24] |
H. Zhao, Y. Shen, Y. Zeng, Time-consistent investment-reinsurance strategy for mean-variance insurers with a defaultable security, J. Math. Anal. Appl., 437 (2016), 1036-1057. doi: 10.1016/j.jmaa.2016.01.035
|
| [25] |
X. Y. Zhou, G. Yin, Markowitz's mean-variance portfolio selection with regime switching: A continuous-time model, SIAM J. Control Optim., 42 (2003), 1466-1482. doi: 10.1137/S0363012902405583
|
| [26] |
B. Zou, A. Cadenillas, Optimal investment and risk control policies for an insurer: Expected utility maximization, Insur. Math. Econ., 58 (2014), 57-67. doi: 10.1016/j.insmatheco.2014.06.006
|
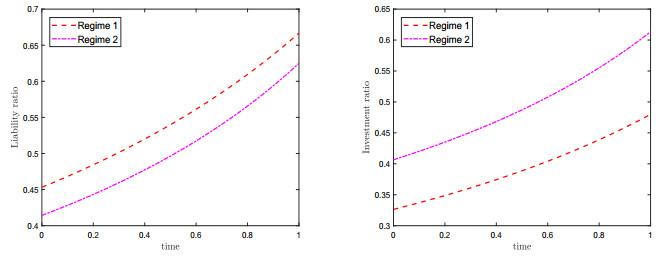
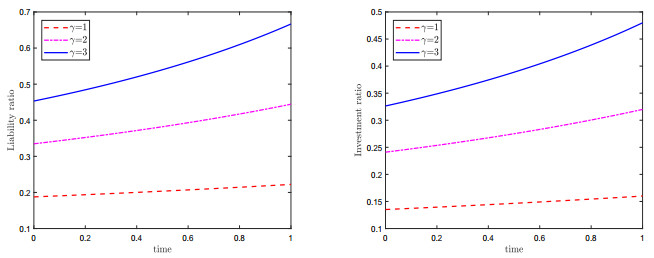
Figures(2)

Hui Sun, Zhongyang Sun, Ya Huang. Equilibrium investment and risk control for an insurer with non-Markovian regime-switching and no-shorting constraints[J]. AIMS Mathematics, 2020, 5(6): 6996-7013. doi: 10.3934/math.2020449







 DownLoad:
DownLoad: