Citation: Shahid Latif, Firuza Mustafa. A nonparametric copula distribution framework for bivariate joint distribution analysis of flood characteristics for the Kelantan River basin in Malaysia[J]. AIMS Geosciences, 2020, 6(2): 171-198. doi: 10.3934/geosci.2020012

| [1] | Drainage and Irrigation Department Malaysia (2004) Annual flood report of DID for Peninsular Malaysia. DID: Kuala Lumpur. Available from: http://www.statistics.gov.my/eng/images/stories/files/journalDOSM/V104ArticleJamaliah.pdf. |
| [2] | Malaysian Meteorological Department (2007) Report on Heavy Rainfall that Caused Floods in Kelantan and Terengganu. MMD: Kuala Lumpur. Available from: https://reliefweb.int/sites/reliefweb.int/files/resources/EE19DAFDE99078B649257266001FED46-Full_Report.pdf. |
| [3] |
Adnan NA, Atkinson PM (2011) Exploring the impact of climate and land use changes on streamflow trends in a monsoon catchment. Int J Clim 31: 815-831. doi: 10.1002/joc.2112

|
| [4] |
Chan NW (1997) Institutional arrangement of flood hazard management in Malaysia: an evaluation using criteria approach. Disasters 21: 206-222. doi: 10.1111/1467-7717.00057
|
| [5] | Hussain STPR, Ismail H (2013) Flood frequency analysis of Kelantan River Basin, Malaysia. World Appl Sci J 28: 1989-1995. |
| [6] |
Nashwan MS, Ismail T, Ahmed K (2018) Flood susceptibility assessment in Kelantan river basin using copula. Int J Eng Technol 7: 584-590. doi: 10.14419/ijet.v7i2.10447
|
| [7] |
Zhang L, Singh VP (2006) Bivariate flood frequency analysis using copula method. J Hydrol Eng 11: 150-164. doi: 10.1061/(ASCE)1084-0699(2006)11:2(150)
|
| [8] | Zhang L (2005) Multivariate hydrological frequency analysis and risk mapping. Doctoral dissertation, Beijing Normal University. |
| [9] |
Reddy MJ, Ganguli P (2012) Bivariate Flood Frequency Analysis of Upper Godavari River Flows Using Archimedean Copulas. Water Resour Manage 26: 3995-4018. doi: 10.1007/s11269-012-0124-z
|
| [10] | Bobee B, Rasmussen PF (1994) Statistical analysis of annual flood series, In: Menon J (Ed.). Trend in Hydrology, 1. Council of Scientific Research Integration, India, 117-135. |
| [11] |
Krstanovic PF, Singh VP (1987) A multivariate stochastic flood analysis using entropy. In: Singh VP (Ed.). Hydrologic Frequency Modelling, Reidel, Dordrecht, 515-539. doi: 10.1007/978-94-009-3953-0_37
|
| [12] |
Yue S (2000) The bivariate lognormal distribution to model a multivariate flood episode. Hydrol Process 14: 2575-2588. doi: 10.1002/1099-1085(20001015)14:14<2575::AID-HYP115>3.0.CO;2-L
|
| [13] |
Sandoval CE, Raynal-Villasenor J (2008) Trivariate generalized extreme value distribution in flood frequency analysis. Hydrol Sci J 53: 550-567. doi: 10.1623/hysj.53.3.550
|
| [14] |
Song S, Singh VP (2010) Metaelliptical copulas for drought frequency analysis of periodic hydrologic data. Stoch Environ Res Risk Assess 24: 425-444. doi: 10.1007/s00477-009-0331-1
|
| [15] |
De Michele C, Salvadori G (2003) A generalized Pareto intensity-duration model of storm rainfall exploiting 2-copulas. J Geophys Res 108: 4067. doi: 10.1029/2002JD002534
|
| [16] | Saklar A (1959) Functions de repartition n dimensions et leurs marges. ublications de l'Institut Statistique de l'Université de Paris, 8: 229-231. |
| [17] | Nelsen RB (2006) An introduction to copulas. Springer, New York. |
| [18] |
Salvadori G (2004) Bivariate return periods via-2 copulas. Stat Methodol 1:129-144. doi: 10.1016/j.stamet.2004.07.002
|
| [19] |
Salvadori G, De Michele C (2004) Frequency analysis via copulas: theoretical aspects and applications to hydrological events. Water Resour Res 40: W12511. doi: 10.1029/2004WR003133
|
| [20] |
Salvadori G, De Michele C (2006) Statistical characterization of temporal structure of storms. Adv Water Resour 29: 827-842. doi: 10.1016/j.advwatres.2005.07.013
|
| [21] | Cong RG, Brady M (2011) The interdependence between Rainfall and Temperature: copula Analyses. Sci World J 2012: 405675. |
| [22] | Karmakar S, Simonovic SP (2008) Bivariate flood frequency analysis. Part 1: Determination of marginal by parametric and non-parametric techniques. J Flood Risk Manag 1: 190-200. |
| [23] |
Adamowski K (1989) A monte Carlo comparison of parametric and nonparametric estimations of flood frequencies. J Hydrol 108: 295-308. doi: 10.1016/0022-1694(89)90290-4
|
| [24] | Silverman BW (1986) Density Estimation for Statistics and Data Analysis, 1st edition. Chapman and Hall, London. |
| [25] |
Kim KD, Heo JH (2002) Comparative study of flood quantiles estimation by nonparametric models. J Hydrol 260: 176-193. doi: 10.1016/S0022-1694(01)00613-8
|
| [26] |
Botev ZI, Grotowski JF, Kroese DP (2010) Kernel Density Estimation via Diffusion. Ann Stat 38: 2916-2957. doi: 10.1214/10-AOS799
|
| [27] |
Dooge JCE (1986) Looking for hydrologic laws. Water Resour Res 22: 46-58. doi: 10.1029/WR022i09Sp0046S
|
| [28] |
Bardsley WE (1988) Toward a General Procedure for Analysis of Extreme Random Events in the Earth Sciences. Math Geol 20: 513-528. doi: 10.1007/BF00890334
|
| [29] |
Lall U, Moon YI, Bosworth K (1993) kernel flood frequency estimators: Bandwidth selection and kernel choice. Water Resour Res 29: 1003-1015. doi: 10.1029/92WR02466
|
| [30] |
Santhosh D, Srinivas V (2013) Bivariate frequency analysis of flood using a diffusion kernel density estimators. Water Resour Res 49: 8328-8343. doi: 10.1002/2011WR010777
|
| [31] |
Moon YI, Lall U (1994) Kernel function estimator for flood frequency analysis. Water Resour Res 30: 3095-3103. doi: 10.1029/94WR01217
|
| [32] | Lall U (1995) Nonparametric function estimation: recent hydrologic contributions, U.S. National Republic. International Union of Geodesy and Geophysics, 1991-1994. Rev Geophys 33: 1093-1099. |
| [33] | Karmakar S, Simonovic SP (2009) Bivariate flood frequency analysis. Part 2: A copula-based approach with mixed marginal distributions. J Flood Risk Manag 2: 32-44. |
| [34] |
Chen SX, Huang TM (2007) Nonparametric estimation of copula functions for dependence modelling. Can J Stat 35: 265-282. doi: 10.1002/cjs.5550350205
|
| [35] |
Latif S, Mustafa F (2020) Trivariate distribution modelling of flood characteristics using copula function-A case study for Kelantan River basin in Malaysia. AIMS Geosci 6: 92-130. doi: 10.3934/geosci.2020007
|
| [36] |
Hosking JRM, Walis JR (1987) Parameter and quantile estimations for the generalized Pareto distributions. Technometrics 29: 339-349. doi: 10.1080/00401706.1987.10488243
|
| [37] |
Yue S, Rasmussen P (2002) Bivariate frequency analysis: discussion of some useful concepts in hydrological applications. Hydrol Process 16: 2881-2898. doi: 10.1002/hyp.1185
|
| [38] | Rao AR, Hamed KH (2000) Flood frequency analysis. CRC Press, Boca Raton, Fla. |
| [39] |
Rosenblatt M (1956) Remarks on some nonparametric estimates of a density function. Ann Math Stat 27: 832-837. doi: 10.1214/aoms/1177728190
|
| [40] | Scott DW (1992) Multivariate Density estimation: Theory, Practice and Visualization. Wiley, New York. |
| [41] | Härdle W (1991) Smoothing Technique with Implementation in S. Springer, New York. |
| [42] |
Kim KD, Heo JH (2002) Comparative study of flood quantiles estimation by nonparametric models. J Hydrol 260: 176-193. doi: 10.1016/S0022-1694(01)00613-8
|
| [43] | Shabri A (2002) Nonparametric Kernel Estimation of Annual Maximum Stream Flow Quantiles, Matematika, 18: 99-107. |
| [44] | Miladinovic B (2008) Kernel density estimation of reliability with applications to extreme value distribution. Graduate Theses and Dissertations. Available from: https://scholarcommons.usf.edu/etd/408. |
| [45] |
Azzalini A (1981) A note on the estimation of a distribution function and quantiles by a kernel method. Biometrika 68: 326-328. doi: 10.1093/biomet/68.1.326
|
| [46] |
Shiau JT (2006) Fitting drought duration and severity with two dimensional copulas. Water Resour Manag 20: 795-815. doi: 10.1007/s11269-005-9008-9
|
| [47] |
Harrell FE, Davis CE (1982) A new distribution-free quantile estimator. Biometrika 69: 635-640. doi: 10.1093/biomet/69.3.635
|
| [48] |
Brown BM, Chen SX (1999) Beta-bernstein smoothing for regression curves with compact support. Scand J Stat 26: 47-59. doi: 10.1111/1467-9469.00136
|
| [49] |
Chen SX (2000) Beta kernel estimators for density functions. Comput Stat Data Anal 31: 131-145. doi: 10.1016/S0167-9473(99)00010-9
|
| [50] |
Bounezmarni T, Rombouts JVK (2009) Nonparametric density estimation for positive time series. Comput Stat Data Anal 54: 245-261. doi: 10.1016/j.csda.2009.08.016
|
| [51] | Charpentier A, Fermanian JD, Scaillet O (2006) The estimation of copulas: Theory and practice. In Rank J, editor. Copulas: From theory to application in finance. London: Risk Books, 35-64. |
| [52] |
Kim TW, Valdés JB, Yoo C (2006) Nonparametric approach for bivariate drought characterisation using Palmer drought index. J Hydrol Eng 11: 134-143. doi: 10.1061/(ASCE)1084-0699(2006)11:2(134)
|
| [53] |
Kullback S, Leibler RA (1951) On information and sufficiency. Ann Math Stat 22: 79-86. doi: 10.1214/aoms/1177729694
|
| [54] |
Akaike H (1974) A new look at the statistical model identification. IEEE Trans Autom Control 19: 716-723. doi: 10.1109/TAC.1974.1100705
|
| [55] |
Schwarz GE (1978) Estimating the dimension of a model. Ann Stat 6: 461-464. doi: 10.1214/aos/1176344136
|
| [56] | Hannan EJ, Quinn BG (1979) The Determination of the Order of an Autoregression. J R Stat Soc Ser B 41: 190-195. |
| [57] |
Shiau JT (2003) Return period of bivariate distributed extreme hydrological events. Stoch Environ Res Risk Assess 17: 42-57. doi: 10.1007/s00477-003-0125-9
|
| [58] |
Brunner MI, Seibert J, Favre AC (2016) Bivariate return periods and their importance for flood peak and volume estimations. WIREs Water 3: 819-833. doi: 10.1002/wat2.1173
|


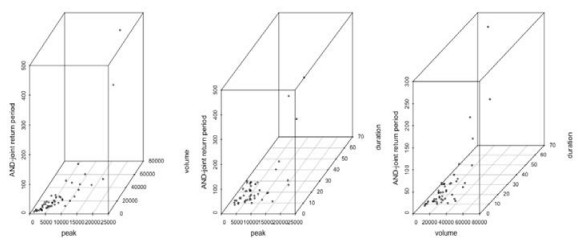
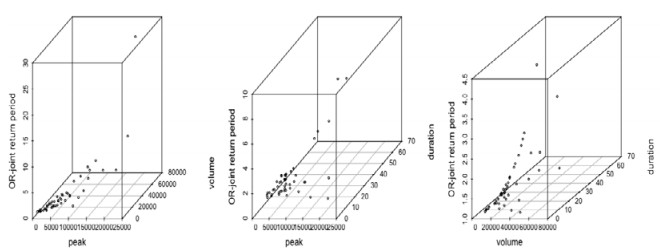
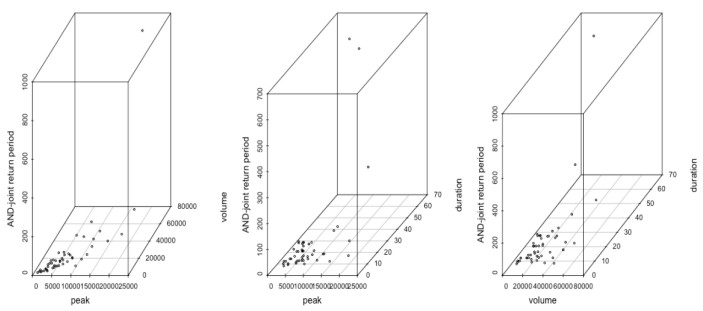
Figures(17) / Tables(11)

Shahid Latif, Firuza Mustafa. A nonparametric copula distribution framework for bivariate joint distribution analysis of flood characteristics for the Kelantan River basin in Malaysia[J]. AIMS Geosciences, 2020, 6(2): 171-198. doi: 10.3934/geosci.2020012







 DownLoad:
DownLoad: