The training of artificial neural networks (ANNs) with rectified linear unit (ReLU) activation via gradient descent (GD) type optimization schemes is nowadays a common industrially relevant procedure. GD type optimization schemes can be regarded as temporal discretization methods for the gradient flow (GF) differential equations associated to the considered optimization problem and, in view of this, it seems to be a natural direction of research to first aim to develop a mathematical convergence theory for time-continuous GF differential equations and, thereafter, to aim to extend such a time-continuous convergence theory to implementable time-discrete GD type optimization methods. In this article we establish two basic results for GF differential equations in the training of fully-connected feedforward ANNs with one hidden layer and ReLU activation. In the first main result of this article we establish in the training of such ANNs under the assumption that the probability distribution of the input data of the considered supervised learning problem is absolutely continuous with a bounded density function that every GF differential equation admits for every initial value a solution which is also unique among a suitable class of solutions. In the second main result of this article we prove in the training of such ANNs under the assumption that the target function and the density function of the probability distribution of the input data are piecewise polynomial that every non-divergent GF trajectory converges with an appropriate rate of convergence to a critical point and that the risk of the non-divergent GF trajectory converges with rate 1 to the risk of the critical point. We establish this result by proving that the considered risk function is semialgebraic and, consequently, satisfies the Kurdyka-Łojasiewicz inequality, which allows us to show convergence of every non-divergent GF trajectory.
Citation: Simon Eberle, Arnulf Jentzen, Adrian Riekert, Georg S. Weiss. Existence, uniqueness, and convergence rates for gradient flows in the training of artificial neural networks with ReLU activation[J]. Electronic Research Archive, 2023, 31(5): 2519-2554. doi: 10.3934/era.2023128
The training of artificial neural networks (ANNs) with rectified linear unit (ReLU) activation via gradient descent (GD) type optimization schemes is nowadays a common industrially relevant procedure. GD type optimization schemes can be regarded as temporal discretization methods for the gradient flow (GF) differential equations associated to the considered optimization problem and, in view of this, it seems to be a natural direction of research to first aim to develop a mathematical convergence theory for time-continuous GF differential equations and, thereafter, to aim to extend such a time-continuous convergence theory to implementable time-discrete GD type optimization methods. In this article we establish two basic results for GF differential equations in the training of fully-connected feedforward ANNs with one hidden layer and ReLU activation. In the first main result of this article we establish in the training of such ANNs under the assumption that the probability distribution of the input data of the considered supervised learning problem is absolutely continuous with a bounded density function that every GF differential equation admits for every initial value a solution which is also unique among a suitable class of solutions. In the second main result of this article we prove in the training of such ANNs under the assumption that the target function and the density function of the probability distribution of the input data are piecewise polynomial that every non-divergent GF trajectory converges with an appropriate rate of convergence to a critical point and that the risk of the non-divergent GF trajectory converges with rate 1 to the risk of the critical point. We establish this result by proving that the considered risk function is semialgebraic and, consequently, satisfies the Kurdyka-Łojasiewicz inequality, which allows us to show convergence of every non-divergent GF trajectory.

| [1] | F. Bach, E. Moulines, Non-strongly-convex smooth stochastic approximation with convergence rate $O(1/n)$, in Advances in Neural Information Processing Systems, 26 (2013), 773–781. Available from: https://proceedings.neurips.cc/paper/2013/file/7fe1f8abaad094e0b5cb1b01d712f708-Paper.pdf. |
| [2] |
A. Jentzen, B. Kuckuck, A. Neufeld, P. von Wurstemberger, Strong error analysis for stochastic gradient descent optimization algorithms, IMA J. Numer. Anal., 41 (2021), 455–492. https://doi.org/10.1093/imanum/drz055 doi: 10.1093/imanum/drz055

|
| [3] | E. Moulines, F. Bach. Non-asymptotic analysis of stochastic approximation algorithms for machine learning, in Advances in Neural Information Processing Systems, 24 (2011), 451–459. Available from: https://proceedings.neurips.cc/paper/2011/file/40008b9a5380fcacce3976bf7c08af5b-Paper.pdf. |
| [4] | Y. Nesterov, Introductory Lectures on Convex Optimization, 2004. https://doi.org/10.1007/978-1-4419-8853-9 |
| [5] | A. Rakhlin, O. Shamir, K. Sridharan, Making gradient descent optimal for strongly convex stochastic optimization, in Proceedings of the 29th International Conference on Machine Learning, Madison, WI, USA, (2012), 1571–1578. |
| [6] |
P. A. Absil, R. Mahony, B. Andrews, Convergence of the iterates of descent methods for analytic cost functions, SIAM J. Optim., 16 (2005), 531–547. https://doi.org/10.1137/040605266 doi: 10.1137/040605266
|
| [7] |
H. Attouch, J. Bolte, On the convergence of the proximal algorithm for nonsmooth functions involving analytic features, Math. Program., 116 (2009), 5–16. https://doi.org/10.1007/s10107-007-0133-5 doi: 10.1007/s10107-007-0133-5
|
| [8] |
H. Attouch, J. Bolte, B. F. Svaiter, Convergence of descent methods for semi-algebraic and tame problems: proximal algorithms, forward-backward splitting, and regularized Gauss-Seidel methods, Math. Program., 137 (2013), 91–129. https://doi.org/10.1007/s10107-011-0484-9 doi: 10.1007/s10107-011-0484-9
|
| [9] |
J. Bolte, A. Daniilidis, A. Lewis. The łojasiewicz inequality for nonsmooth subanalytic functions with applications to subgradient dynamical systems, SIAM J. Optim., 17 (2007), 1205–1223. https://doi.org/10.1137/050644641 doi: 10.1137/050644641
|
| [10] | S. Dereich, S. Kassing, Convergence of stochastic gradient descent schemes for Lojasiewicz-landscapes, preprint, arXiv: 2102.09385. |
| [11] | H. Karimi, J. Nutini, M. Schmidt, Linear convergence of gradient and proximal-gradient methods under the Polyak-Lojasiewicz condition, in Machine Learning and Knowledge Discovery in Databases, (2016), 795–811. https://doi.org/10.1007/978-3-319-46128-1_50 |
| [12] |
K. Kurdyka, T. Mostowski, A. Parusiński, Proof of the gradient conjecture of R. Thom, Ann. Math., 152 (2000), 763–792. https://doi.org/10.2307/2661354 doi: 10.2307/2661354
|
| [13] |
J. Lee, I. Panageas, G. Piliouras, M. Simchowitz, M. Jordan, B. Recht, First-order methods almost always avoid strict saddle points, Math. Program., 176 (2019), 311–337. https://doi.org/10.1007/s10107-019-01374-3 doi: 10.1007/s10107-019-01374-3
|
| [14] | J. D. Lee, M. Simchowitz, M. I. Jordan, B. Recht, Gradient descent only converges to minimizers, in 29th Annual Conference on Learning Theory, 49 (2016), 1246–1257. Available from: http://proceedings.mlr.press/v49/lee16.html. |
| [15] | S. Łojasiewicz, Sur les trajectoires du gradient d'une fonction analytique, in Geometry Seminars, (1983), 115–117. |
| [16] |
P. Ochs, Unifying abstract inexact convergence theorems and block coordinate variable metric iPiano, SIAM J. Optim., 29 (2019), 541–570. https://doi.org/10.1137/17M1124085 doi: 10.1137/17M1124085
|
| [17] |
D. P. Bertsekas, J. N. Tsitsiklis, Gradient convergence in gradient methods with errors, SIAM J. Optim., 10 (2000), 627–642. https://doi.org/10.1137/S105262349733106 doi: 10.1137/S105262349733106
|
| [18] | B. Fehrman, B. Gess, A. Jentzen, Convergence rates for the stochastic gradient descent method for non-convex objective functions, J. Mach. Learn. Res., 21 (2022), 5354–5401. Available from: https://dl.acm.org/doi/abs/10.5555/3455716.3455852. |
| [19] |
Y. Lei, T. Hu, G. Li, K. Tang, Stochastic gradient descent for nonconvex learning without bounded gradient assumptions, IEEE Trans. Neural Networks Learn. Syst., 31 (2019), 4394–4400. https://doi.org/10.1109/TNNLS.2019.2952219 doi: 10.1109/TNNLS.2019.2952219
|
| [20] |
V. Patel. Stopping criteria for, and strong convergence of, stochastic gradient descent on Bottou-Curtis-Nocedal functions, Math. Program., 195 (2022), 693–734. https://doi.org/10.1007/s10107-021-01710-6 doi: 10.1007/s10107-021-01710-6
|
| [21] |
F. Santambrogio, {Euclidean, metric, and Wasserstein} gradient flows: an overview, Bull. Math. Sci., 7 (2017), 87–154. https://doi.org/10.1007/s13373-017-0101-1 doi: 10.1007/s13373-017-0101-1
|
| [22] | S. Arora, S. Du, W. Hu, Z. Li, R. Wang, Fine-grained analysis of optimization and generalization for overparameterized two-layer neural networks, in Proceedings of the 36th International Conference on Machine Learning, 97 (2019), 322–332. Available from: http://proceedings.mlr.press/v97/arora19a.html. |
| [23] | L. Chizat, E. Oyallon, F. Bach, On lazy training in differentiable programming, in Advances in Neural Information Processing Systems, 32 (2019). Available from: https://proceedings.neurips.cc/paper/2019/file/ae614c557843b1df326cb29c57225459-Paper.pdf. |
| [24] | S. S. Du, X. Zhai, B. Póczos, A. Singh, Gradient descent provably optimizes over-parameterized neural networks, in International Conference on Learning Representations, 2019. Available from: https://openreview.net/forum?id = S1eK3i09YQ. |
| [25] |
W. E, C. Ma, L. Wu, A comparative analysis of optimization and generalization properties of two-layer neural network and random feature models under gradient descent dynamics, Sci. China Math., 63 (2020), 1235–1258. https://doi.org/10.1007/s11425-019-1628-5 doi: 10.1007/s11425-019-1628-5
|
| [26] | A. Jacot, F. Gabriel, C. Hongler, Neural tangent kernel: convergence and generalization in neural networks, in Advances in Neural Information Processing Systems, 31 (2018). Available from: https://proceedings.neurips.cc/paper/2018/file/5a4be1fa34e62bb8a6ec6b91d2462f5a-Paper.pdf. |
| [27] | A. Jentzen, T. Kröger, Convergence rates for gradient descent in the training of overparameterized artificial neural networks with biases, preprint, arXiv: 2102.11840. |
| [28] | G. Zhang, J. Martens, R. Grosse, Fast convergence of natural gradient descent for over-parameterized neural networks, in Advances in Neural Information Processing Systems, 32 (2019), 8082–8093. Available from: https://proceedings.neurips.cc/paper/2019/file/1da546f25222c1ee710cf7e2f7a3ff0c-Paper.pdf. |
| [29] | Z. Chen, G. Rotskoff, J. Bruna, E. Vanden-Eijnden, A dynamical central limit theorem for shallow neural networks, in Advances in Neural Information Processing Systems, 33 (2020), 22217–22230. Available from: https://proceedings.neurips.cc/paper/2020/file/fc5b3186f1cf0daece964f78259b7ba0-Paper.pdf. |
| [30] |
L. Chizat, Sparse optimization on measures with over-parameterized gradient descent, Math. Program., 194 (2022), 487–532. https://doi.org/10.1007/s10107-021-01636-z doi: 10.1007/s10107-021-01636-z
|
| [31] | L. Chizat, F. Bach, On the global convergence of gradient descent for over-parameterized models using optimal transport, in Advances in Neural Information Processing Systems, 31 (2018), 3036–3046. Available from: https://proceedings.neurips.cc/paper/2018/file/a1afc58c6ca9540d057299ec3016d726-Paper.pdf. |
| [32] | W. E, C. Ma, S. Wojtowytsch, L. Wu, Towards a mathematical understanding of neural network-based machine learning: what we know and what we don't, preprint, arXiv: 2009.10713. |
| [33] |
P. Cheridito, A. Jentzen, A. Riekert, F. Rossmannek, A proof of convergence for gradient descent in the training of artificial neural networks for constant target functions, J. Complexity, 72 (2022), 101646. https://doi.org/10.1016/j.jco.2022.101646 doi: 10.1016/j.jco.2022.101646
|
| [34] |
A. Jentzen, A. Riekert, A proof of convergence for stochastic gradient descent in the training of artificial neural networks with ReLU activation for constant target functions, Z. Angew. Math. Phys., 73 (2022), 188. https://doi.org/10.1007/s00033-022-01716-w doi: 10.1007/s00033-022-01716-w
|
| [35] | A. Jentzen, A. Riekert, A proof of convergence for the gradient descent optimization method with random initializations in the training of neural networks with ReLU activation for piecewise linear target functions, J. Mach. Learn. Res., 23 (2022), 1–50. Available from: https://www.jmlr.org/papers/volume23/21-0962/21-0962.pdf. |
| [36] |
P. Cheridito, A. Jentzen, F. Rossmannek, Landscape analysis for shallow neural networks: complete classification of critical points for affine target functions, J. Nonlinear Sci., 32 (2022), 64. https://doi.org/10.1007/s00332-022-09823-8 doi: 10.1007/s00332-022-09823-8
|
| [37] |
A. Jentzen, A. Riekert, Convergence analysis for gradient flows in the training of artificial neural networks with ReLU activation, J. Math. Anal. Appl., 517 (2023), 126601. https://doi.org/10.1016/j.jmaa.2022.126601 doi: 10.1016/j.jmaa.2022.126601
|
| [38] | D. Gallon, A. Jentzen, F. Lindner, Blow up phenomena for gradient descent optimization methods in the training of artificial neural networks, preprint, arXiv: 2211.15641. |
| [39] | R. T. Rockafellar, R. Wets, Variational Analysis, Springer-Verlag, Berlin, 1998. https://doi.org/10.1007/978-3-642-02431-3 |
| [40] | E. Bierstone, P. D. Milman, Semianalytic and subanalytic sets, Inst. Hautes Études Sci. Publ. Math., 67 (1998), 5–42. https://doi.org/10.1007/BF02699126 |
| [41] |
T. Kaiser, Integration of semialgebraic functions and integrated Nash functions, Math. Z., 275 (2013), 349–366. https://doi.org/10.1007/s00209-012-1138-1 doi: 10.1007/s00209-012-1138-1
|
| [42] | M. Coste, An introduction to semialgebraic geometry, 2000. Available from: http://blogs.mat.ucm.es/jesusr/wp-content/uploads/sites/52/2020/03/SAG.pdf. |
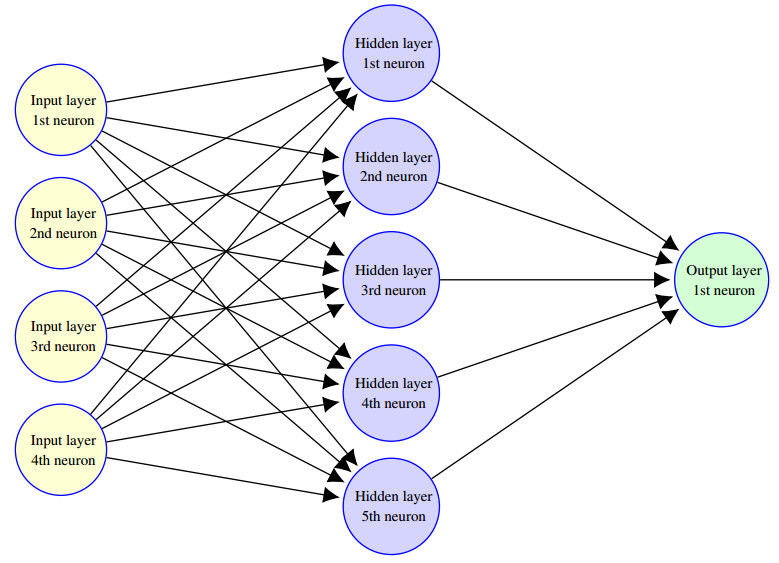
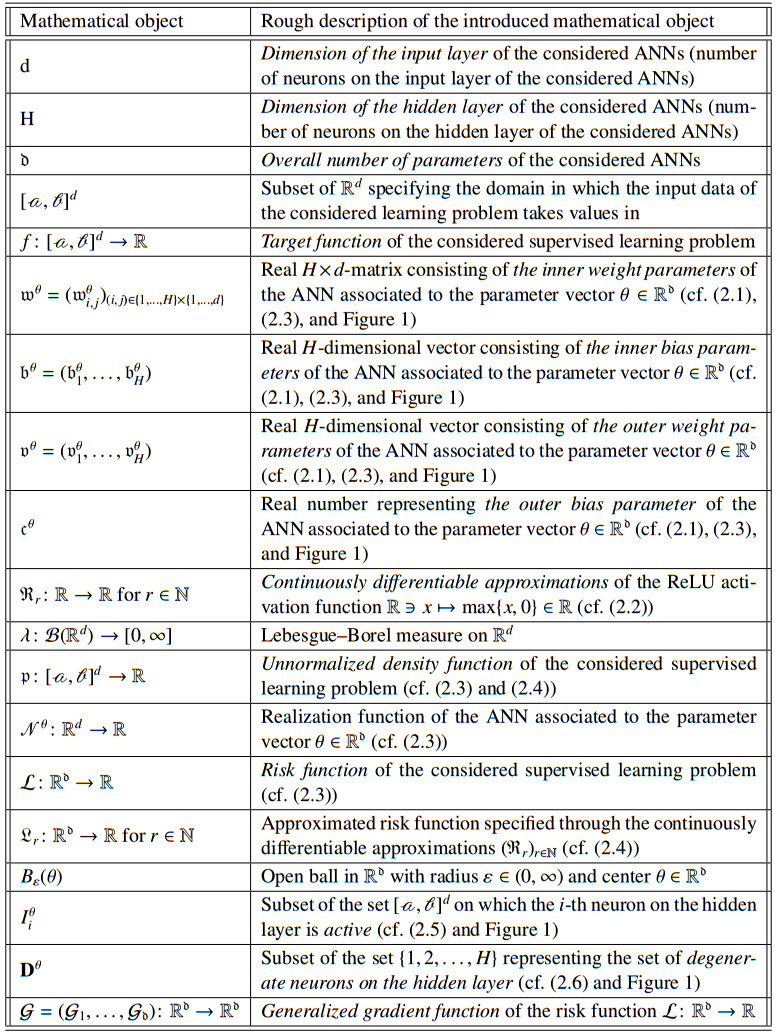
Figures(2)
Simon Eberle, Arnulf Jentzen, Adrian Riekert, Georg S. Weiss. Existence, uniqueness, and convergence rates for gradient flows in the training of artificial neural networks with ReLU activation[J]. Electronic Research Archive, 2023, 31(5): 2519-2554. doi: 10.3934/era.2023128







 DownLoad:
DownLoad: