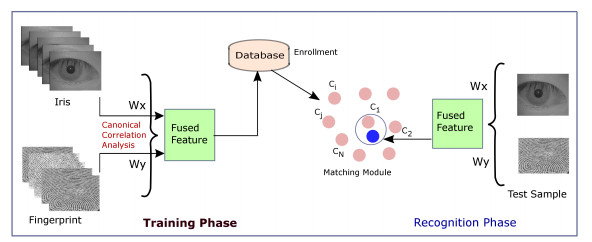
For reliable and accurate multimodal biometric based person verification, demands an effective discriminant feature representation and fusion of the extracted relevant information across multiple biometric modalities. In this paper, we propose feature level fusion by adopting the concept of canonical correlation analysis (CCA) to fuse Iris and Fingerprint feature sets of the same person. The uniqueness of this approach is that it extracts maximized correlated features from feature sets of both modalities as effective discriminant information within the features sets. CCA is, therefore, suitable to analyze the underlying relationship between two feature spaces and generates more powerful feature vectors by removing redundant information. We demonstrate that an efficient multimodal recognition can be achieved with a significant reduction in feature dimensions with less computational complexity and recognition time less than one second by exploiting CCA based joint feature fusion and optimization. To evaluate the performance of the proposed system, Left and Right Iris, and thumb Fingerprints from both hands of the SDUMLA-HMT multimodal dataset are considered in this experiment. We show that our proposed approach significantly outperforms in terms of equal error rate (EER) than unimodal system recognition performance. We also demonstrate that CCA based feature fusion excels than the match score level fusion. Further, an exploration of the correlation between Right Iris and Left Fingerprint images (EER of 0.1050%), and Left Iris and Right Fingerprint images (EER of 1.4286%) are also presented to consider the effect of feature dominance and laterality of the selected modalities for the robust multimodal biometric system.
Citation: Chetana Kamlaskar, Aditya Abhyankar. Iris-Fingerprint multimodal biometric system based on optimal feature level fusion model[J]. AIMS Electronics and Electrical Engineering, 2021, 5(4): 229-250. doi: 10.3934/electreng.2021013
For reliable and accurate multimodal biometric based person verification, demands an effective discriminant feature representation and fusion of the extracted relevant information across multiple biometric modalities. In this paper, we propose feature level fusion by adopting the concept of canonical correlation analysis (CCA) to fuse Iris and Fingerprint feature sets of the same person. The uniqueness of this approach is that it extracts maximized correlated features from feature sets of both modalities as effective discriminant information within the features sets. CCA is, therefore, suitable to analyze the underlying relationship between two feature spaces and generates more powerful feature vectors by removing redundant information. We demonstrate that an efficient multimodal recognition can be achieved with a significant reduction in feature dimensions with less computational complexity and recognition time less than one second by exploiting CCA based joint feature fusion and optimization. To evaluate the performance of the proposed system, Left and Right Iris, and thumb Fingerprints from both hands of the SDUMLA-HMT multimodal dataset are considered in this experiment. We show that our proposed approach significantly outperforms in terms of equal error rate (EER) than unimodal system recognition performance. We also demonstrate that CCA based feature fusion excels than the match score level fusion. Further, an exploration of the correlation between Right Iris and Left Fingerprint images (EER of 0.1050%), and Left Iris and Right Fingerprint images (EER of 1.4286%) are also presented to consider the effect of feature dominance and laterality of the selected modalities for the robust multimodal biometric system.

| [1] | Ross AA, Nandakumar K, Jain A (2006) Handbook of multibiometrics, vol. 6, Springer Science & Business Media. |
| [2] | Maltoni D, Maio D, Jain A, et al. (2009) Handbook of fingerprint recognition, 2 Eds., Springer Science & Business Media. |
| [3] | Jain AK, Ross A, Prabhakar S (2004) An introduction to biometric recognition. IEEE T Circ Syst Vid 14: 4–20. |
| [4] | Nandakumar K, Chen Y, Dass SC, et al. (2008) Likelihood ratio-based biometric score fusion. IEEE T Pattern Anal 30: 342–347. |
| [5] | He M, Horng SJ, Fan P, et al. (2010) Performance evaluation of score level fusion in multimodal biometric systems. Pattern Recogn 43: 1789–1800. |
| [6] | Cui J, Li JP, Lu XJ (2008) Study on multi-biometric feature fusion and recognition model, in Apperceiving Computing and Intelligence Analysis, 2008. ICACIA 2008. International Conference on, 66–69. |
| [7] | Singh M, Singh R, Ross A (2019) A comprehensive overview of biometric fusion. Inform Fusion 52: 187–205. |
| [8] | Ross AA, Govindarajan R (2005) Feature level fusion of hand and face biometrics, in Defense and Security, International Society for Optics and Photonics, 196–204. |
| [9] | Rattani A, Kisku DR, Bicego M, et al. (2007) Feature level fusion of face and fingerprint biometrics, in Biometrics: Theory, Applications, and Systems, 2007. BTAS 2007. First IEEE International Conference on, IEEE, 1–6. |
| [10] | Shekhar S, Patel VM, Nasrabadi NM, et al. (2014) Joint sparse representation for robust multimodal biometrics recognition. IEEE T Pattern Anal 36: 113–126. |
| [11] | Conti V, Militello C, Sorbello F, et al. (2010) A frequency-based approach for features fusion in fingerprint and iris multimodal biometric identification systems. IEEE T Syst Man Cy C 40: 384–395. |
| [12] | Nagar A, Nandakumar K, Jain AK (2012) Multibiometric cryptosystems based on feature-level fusion. IEEE T Inf Foren Sec 7: 255–268. |
| [13] | Xing X, Wang K, Lv Z (2015) Fusion of gait and facial features using coupled projections for people identification at a distance. IEEE Signal Proc Let 22: 2349–2353. |
| [14] | Goswami G, Mittal P, Majumdar A, et al. (2016) Group sparse representation based classification for multi-feature multimodal biometrics. Inform. Fusion 32: 3–12. |
| [15] | Walia GS, Singh T, Singh K, et al. (2019) Robust multimodal biometric system based on optimal score level fusion model. Expert Syst Appl 116: 364–376. |
| [16] | Ammour B, Boubchir L, Bouden T, et al. (2020) Face–iris multimodal biometric identification system. Electronics 9: 85. |
| [17] | Alay N, Al-Baity HH (2020) Deep learning approach for multimodal biometric recognition system based on fusion of iris, face, and finger vein traits. Sensors 20: 5523. |
| [18] | Sun QS, Zeng SG, Liu Y, et al. (2005) A new method of feature fusion and its application in image recognition. Pattern Recogn 38: 2437–2448. |
| [19] | Hotelling H (1936) Relations between two sets of variates. Biometrika 28: 321–377. |
| [20] | Hardoon DR, Szedmak S, Shawe-Taylor J (2004) Canonical correlation analysis: An overview with application to learning methods. Neural Comput 16: 2639–2664. |
| [21] | Yu P, Xu D, Zhou H (2010) Feature level fusion using palmprint and finger geometry based on canonical correlation analysis, in Advanced computer theory and engineering (ICACTE), 2010 3rd international conference on, IEEE, 5–260. |
| [22] | Xu X, Mu Z (2007) Feature fusion method based on KCCA for ear and profile face based multimodal recognition, in Automation and Logistics, IEEE International Conference on, IEEE, 620–623. |
| [23] | Yang J, Zhang X (2012) Feature-level fusion of fingerprint and finger-vein for personal identification. Pattern Recogn Lett 33: 623–628. |
| [24] | Haghighat M, Abdel-Mottaleb M, Alhalabi W (2016) Discriminant correlation analysis: Real-time feature level fusion for multimodal biometric recognition. IEEE T Inf Foren Sec 11: 1984–1996. |
| [25] | Xin M, Xiaojun J (2017) Correlation-based identification approach for multimodal biometric fusion. The Journal of China Universities of Posts and Telecommunications 24: 34–50. |
| [26] | Kamlaskar C, Deshmukh S, Gosavi S, et al. (2019) Novel canonical correlation analysis based feature level fusion algorithm for multimodal recognition in biometric sensor systems. Sensor Lett 17: 75–86. |
| [27] | Wang S, Haishun D, Zhang G, et al. (2020) Robust canonical correlation analysis based on L1-norm minimization for feature learning and image recognition. J Electron Imag 29: 1–19. |
| [28] | Gao, X, Sun Q, Xu H (2017) Multiple-rank supervised canonical correlation analysis for feature extraction, fusion and recognition. Expert Syst Appl 84: 171–185. |
| [29] | Gao X, Sun Q, Yang J (2018) MRCCA: A novel CCA based method and its application in feature extraction and fusion for matrix data. Appl Soft Comput 62: 5–56. |
| [30] | Gao X, Sun Q, Xu H, et al. (2018) 2D-LPCCA and 2D-SPCCA: Two new canonical correlation methods for feature extraction, fusion and recognition. Neurocomputing 284: 148–159. |
| [31] | Wildes RP (1997) Iris recognition: an emerging biometric technology. P IEEE 85: 1348–1363. |
| [32] | Negin M, Chmielewski TA, Salganicoff M, et al. (2000) An iris biometric system for public and personal use. Computer 33: 70–75. |
| [33] | Borga M (2001) Canonical correlation: a tutorial. Available from: http://www.cs.cmu.edu/~tom/10701_sp11/slides/CCA_tutorial.pdf. |
| [34] | Tan P, Steinbach M, Kumar V (2006) Introduction to data mining, Pearson International Edition, Pearson Addison Wesley. |
| [35] | Yin Y, Liu L, Sun X (2011) SDUMLA-HMT: a multimodal biometric database. In: Sun Z., Lai J., Chen X., Tan T. (eds) Biometric Recognition, CCBR'11, Lecture Notes in Computer Science, Springer-Verlag, Berlin, Heidelberg, 7098: 260–268. |
| [36] | Abhyankar A, Schuckers S (2009) Iris quality assessment and bi-orthogonal wavelet based encoding for recognition. Pattern Recog 42: 1878–1894. |
| [37] | Lee Y, Micheals RJ, Filliben JJ (2013) Vasir: an open-source research platform for advanced iris recognition technologies. J Res Natl Inst Stan 118: 218. |
| [38] | Video-based automated system for iris recognition (VASIR). Available from: http://www.nist.gov/itl/iad/ig/vasir.cfm. |
| [39] | NIST biometric image software, NBIS release 4.2.0, 2014. Available from: http://nigos.nist.gov:8080/nist/nbis/nbis_v4_2_0.zip. |
| [40] | Watson CI, Garris MD, Tabassi E, et al. (2007) User's guide to nist biometric image software (nbis). |
| [41] | Masek L, Kovesi P (2003) Matlab source code for a biometric identification system based on iris patterns. The School of Computer Science and Software Engineering, The University of Western Australia, 2(4). |
| [42] | Daugman J (2004) How iris recognition works. IEEE T Circ Syst Vid 14: 21–30. |
| [43] | Jain AK, Prabhakar S, Hong L, et al. (2000) Filterbank-based fingerprint matching. IEEE T Image Process 9: 846–859. |
| [44] | Kevenaar TAM, Schrijen GJ, Veen MV, et al. (2005) Face recognition with renewable and privacy preserving binary templates, in Automatic Identification Advanced Technologies, 2005. Fourth IEEE Workshop on, IEEE, 21–26. |
| [45] | Lumini A, Nanni L (2017) Overview of the combination of biometric matchers. Inform Fusion 33: 71–85. |
| [46] | Raghavendra R, Dorizzi B, Rao A, et al. (2011) Designing efficient fusion schemes for multimodal biometric systems using face and palmprint. Pattern Recog 44: 1076–1088. |
| [47] | Sgroi A, Bowyer KW, Flynn P (2012) Effects of dominance and laterality on iris recognition, in 2012 IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops, 52–58. |
| [48] | Wang L, Chen B, Xu P, et al. (2020) Geometry consistency aware confidence evaluation for feature matching, in Image and Vision Computing 103: 103984. |
| [49] | Zhao Yu, Hongwei Li, Shaohua W, et al. (2019) Knowledge-Aided Convolutional Neural Network for Small Organ Segmentation, in IEEE Journal of Biomedical and Health Informatics 23: 1363–1373. |








Figures(9) / Tables(6)

Chetana Kamlaskar, Aditya Abhyankar. Iris-Fingerprint multimodal biometric system based on optimal feature level fusion model[J]. AIMS Electronics and Electrical Engineering, 2021, 5(4): 229-250. doi: 10.3934/electreng.2021013







 DownLoad:
DownLoad: