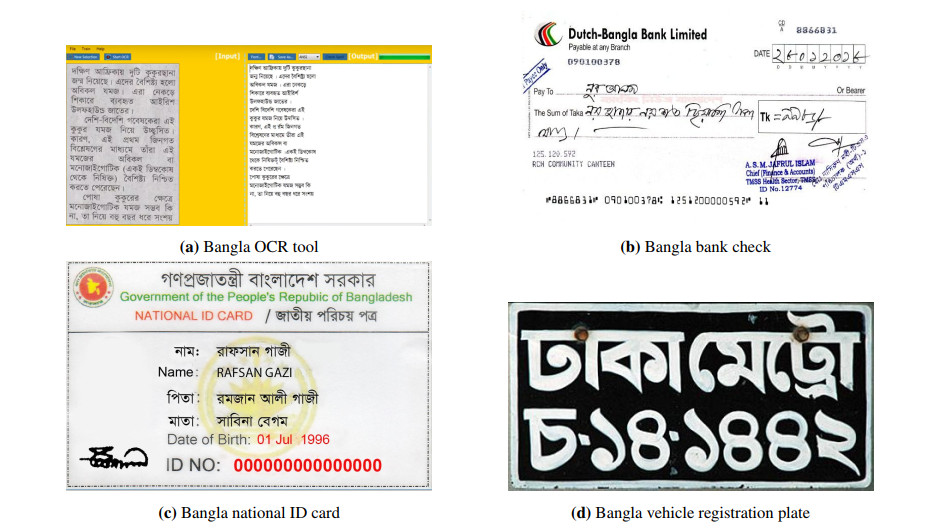
Figure 1.
Example application areas of Bangla handwritten letter classification in real-life.
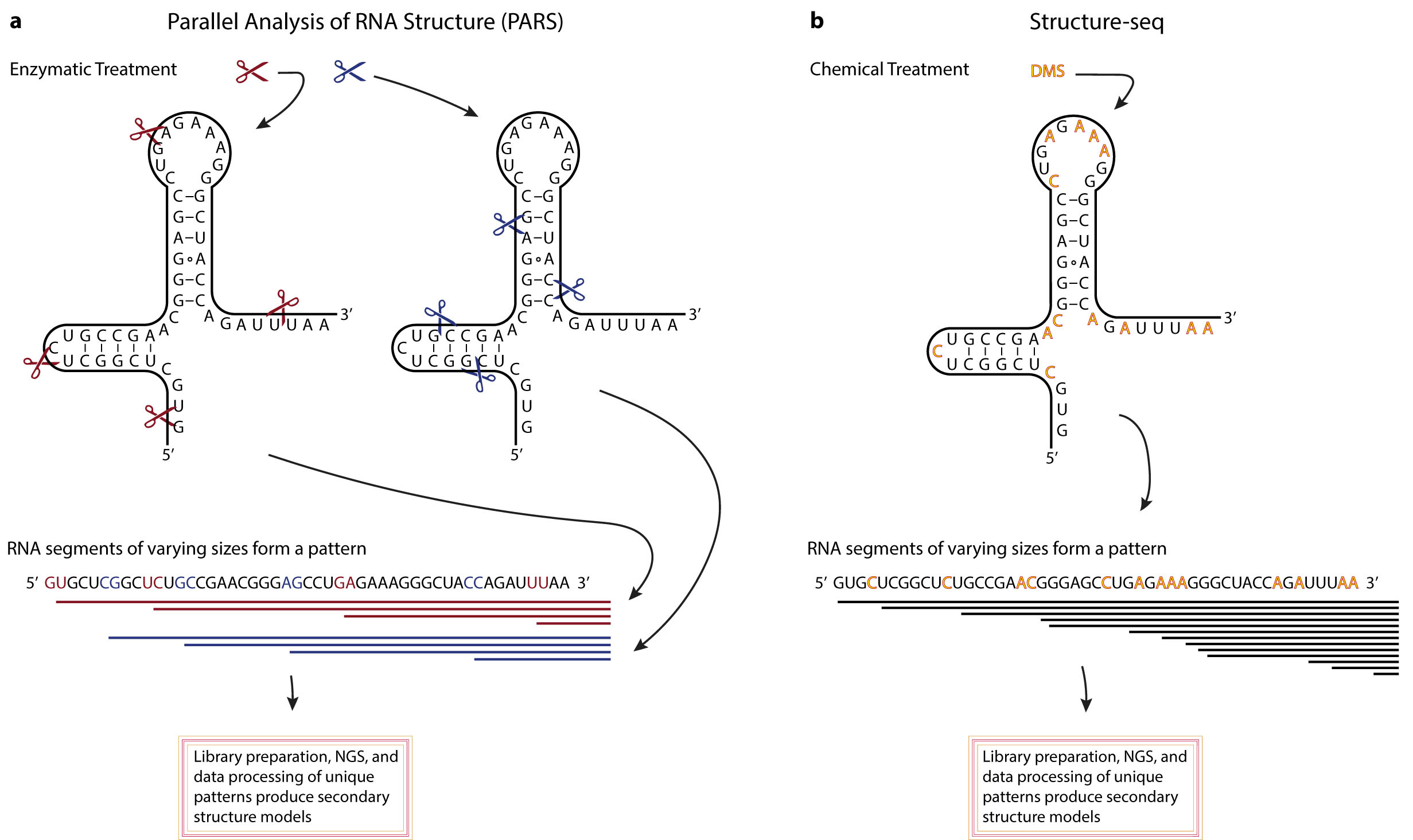
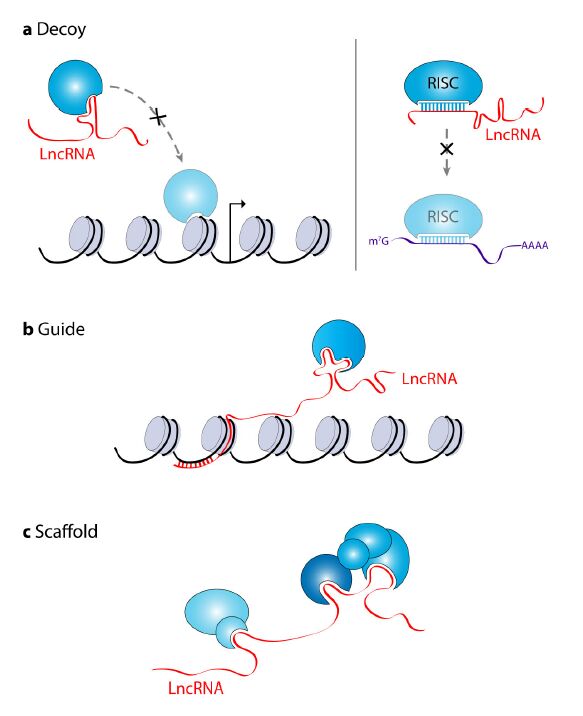
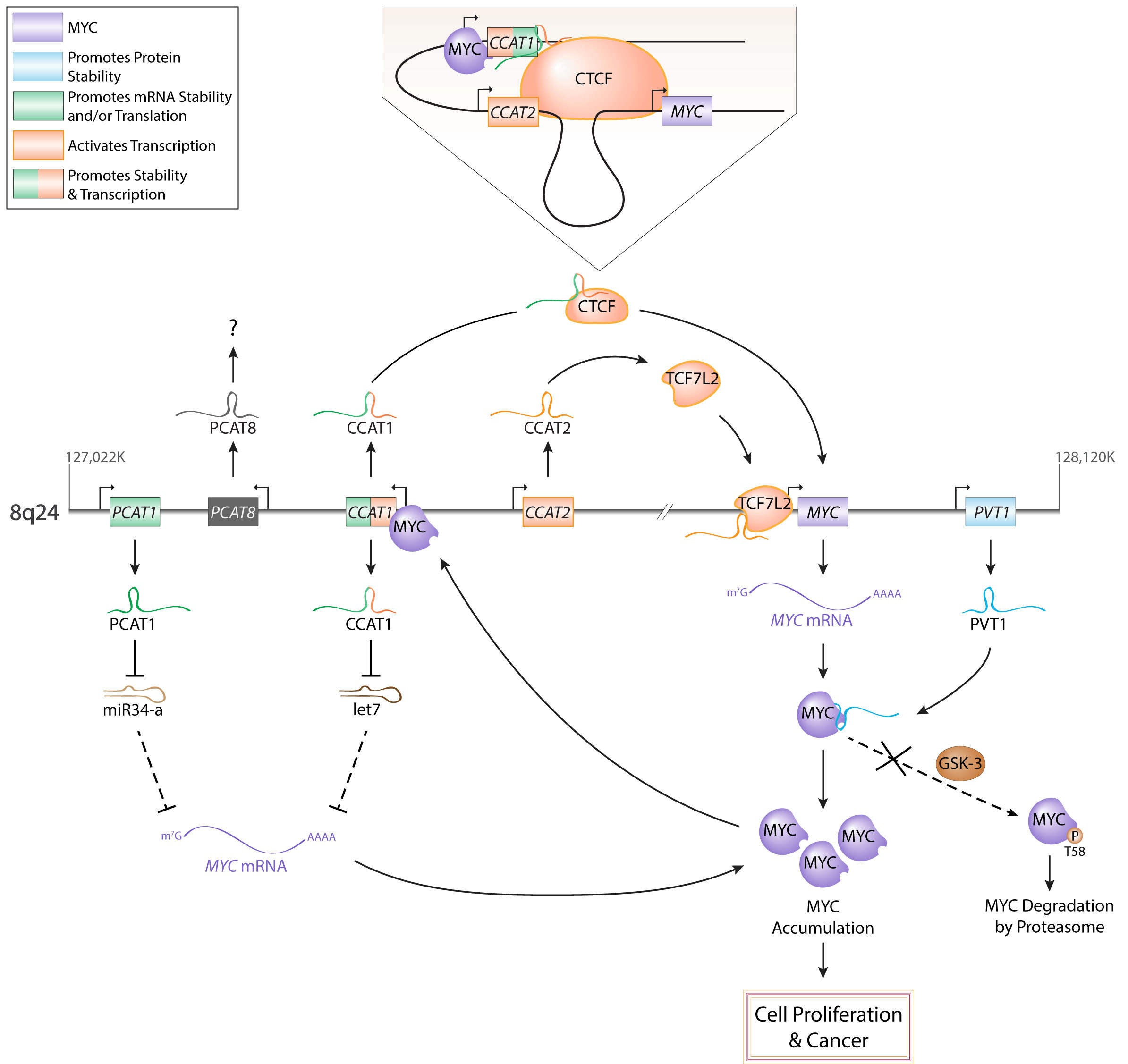
Citation: Michael J. Hamilton, Matthew D. Young, Silvia Sauer, Ernest Martinez. The interplay of long non-coding RNAs and MYC in cancer[J]. AIMS Biophysics, 2015, 2(4): 794-809. doi: 10.3934/biophy.2015.4.794
| [1] | Jason Adams, Yumou Qiu, Luis Posadas, Kent Eskridge, George Graef . Phenotypic trait extraction of soybean plants using deep convolutional neural networks with transfer learning. Big Data and Information Analytics, 2021, 6(0): 26-40. doi: 10.3934/bdia.2021003 |
| [2] | Nickson Golooba, Woldegebriel Assefa Woldegerima, Huaiping Zhu . Deep neural networks with application in predicting the spread of avian influenza through disease-informed neural networks. Big Data and Information Analytics, 2025, 9(0): 1-28. doi: 10.3934/bdia.2025001 |
| [3] | Xiaoxiang Guo, Zuolin Shi, Bin Li . Multivariate polynomial regression by an explainable sigma-pi neural network. Big Data and Information Analytics, 2024, 8(0): 65-79. doi: 10.3934/bdia.2024004 |
| [4] | Bill Huajian Yang . Modeling path-dependent state transitions by a recurrent neural network. Big Data and Information Analytics, 2022, 7(0): 1-12. doi: 10.3934/bdia.2022001 |
| [5] | David E. Bernholdt, Mark R. Cianciosa, David L. Green, Kody J.H. Law, Alexander Litvinenko, Jin M. Park . Comparing theory based and higher-order reduced models for fusion simulation data. Big Data and Information Analytics, 2018, 3(2): 41-53. doi: 10.3934/bdia.2018006 |
| [6] | Marco Tosato, Jianhong Wu . An application of PART to the Football Manager data for players clusters analyses to inform club team formation. Big Data and Information Analytics, 2018, 3(1): 43-54. doi: 10.3934/bdia.2018002 |
| [7] | Mingxing Zhou, Jing Liu, Shuai Wang, Shan He . A comparative study of robustness measures for cancer signaling networks. Big Data and Information Analytics, 2017, 2(1): 87-96. doi: 10.3934/bdia.2017011 |
| [8] | Xiangmin Zhang . User perceived learning from interactive searching on big medical literature data. Big Data and Information Analytics, 2017, 2(3): 239-254. doi: 10.3934/bdia.2017019 |
| [9] | Yiwen Tao, Zhenqiang Zhang, Bengbeng Wang, Jingli Ren . Motality prediction of ICU rheumatic heart disease with imbalanced data based on machine learning. Big Data and Information Analytics, 2024, 8(0): 43-64. doi: 10.3934/bdia.2024003 |
| [10] | Yaru Cheng, Yuanjie Zheng . Frequency filtering prompt tuning for medical image semantic segmentation with missing modalities. Big Data and Information Analytics, 2024, 8(0): 109-128. doi: 10.3934/bdia.2024006 |
Printed script letter classification has a tremendous commercial and pedagogical importance for book publishers, online Optical Character Recognition (OCR) tools, bank officers, postal officers, video makers, and so on [1,2,3]. Postal mail sorting according to zip code, the verification of signatures, and check processing are usually done with the application of grapheme classification [4,5,6]. Some sample images of its application are shown in Figure 1.
Statistically, the importance of printed script letter classification is enormous when a large population uses a specific language. For example, with nearly 230 million native speakers, Bengali (also called Bangla) ranks as the fifth most spoken language in the world [7]. It is the official language of Bangladesh and the second most spoken language in India [8] after Hindi.
Handwritten character classification or recognition is particularly challenging for the Bengali language, as it has 49 letters and 18 potential diacritics (or accents). Moreover, this language supports complex letter structures created from its basic letters and diacritics. In total, the Bangla letter variations are estimated to be around 13, 000, which is 52 times more than the English letter variations [9]. Although several language grapheme classifications have received much attention [10,11,12], Bangla is still a relatively unexplored field, with most works done in the detection of vowels and consonants. The limited progress in exploring the Bengali language has motivated us to classify the Bengali handwritten letters into three constituent elements: root, vowel, and constant.
Previously, several machine learning models have been used for different language grapheme recognition [13]. Several research using the deep convolutional neural network has been successful in the detection of handwritten characters in Latin, Chinese, and English language [14,15]. In other words, successful feature extraction became possible using different types of layers in neural networks. The convolutional neural network with the augmentation of the images of handwriting can generate a better model through training in deep learning [16,17]. Previous research in this area faced fewer challenges regarding variations, massive data usage, and model creation that deep learning needs most regarding the high number of label classification [19,20].
This paper proposes a deep convolutional neural network with an encoder-decoder to facilitate the accurate classification of Bangla handwritten letters from images. We use 200, 840 handwritten images to train and test the proposed deep learning model. We train in 4 steps with four subsets of images containing 50, 210 images each. In doing so, we create three different labels (roots, vowels, and consonants) from each handwritten image. The result shows that the proposed model can classify handwritten Bangla letters as follows: roots-93%, vowels-96%, and consonants-97%, which is much better than previous works done on Bangla grapheme variations and dataset size.
The paper is organized as follows: Section 2 discusses the brief background of existing research on this research area. Section 3 is devoted to present Bangla handwritten letter dataset details. This section discusses the dataset structure and format and augments the dataset to create many variations. Section 4 discusses the architecture of the models for Bangla handwritten grapheme classification, and in section 5, we discuss the experimental process, tools, and used programming language. Section 6 shows the detailed results of the training process and validation. Finally, section 7 concludes the research work by discussing the contributions and applicability in the classification of Bangla handwritten letters.
Optical Character Recognition is one of the favorite research topics in computer graphics and linguistic research. This section briefly discusses two areas first, how deep learning is used in character recognition, second, how deep learning is used in Bangla handwritten digit and letter classification.
In optical character recognition, many research works have been proposed. Théodore et al. showed that learning features with CNN is much better for handwritten word recognition [21]. However, the model needs a longer processing time when classifying a word compared to a letter. Zhuravlev et al. mentioned this issue in their research and experimented with a differential classification technique on grapheme images using multiple neural networks [22,23]. However, the model works better with that small dataset and will fail to detect when augmented images will be provided. Jiayue et al. discussed this issue and proved that proper augmentation before feeding into CNN could be more efficient in grapheme classification [24].
Regarding Bangla character and digit recognition, there are few kinds of research available. A study by Shopon et al. presented unsupervised learning using an auto-encoder with deep ConvNet to recognize Bangla digits [25]. A similar study by Akhand et al. proposed a simple CNN for Bangla handwritten numeral recognition [26,27]. These methods achieved 99% accuracy in detecting Bangla digits and faced fewer challenges in classifying only ten labels than more character recognition labels.
A study on Bangla character recognition by Rabby et al. used CMATERdb and BanglaLekha as datasets and CNN to recognize handwritten characters. The resulted accuracy of CNN was 98%, and 95.71% for each dataset [28]. Another study by Alif et al. showed ResNet-18 architecture is giving similar accuracy on CMATERdb3, which is a relatively large dataset than previous [29,30]. The limitation of these two research is their image variations and dataset size.
This paper addresses the limitations of previous research in image augmentation, dataset size, proper model creation, and a high number of label classification.
This section describes raw data and data augmentation to ensure better data preparation for our proposed model.
This study uses the dataset from the Bengali.AI community that works as an open-source dataset for research. The dataset was prepared from handwritten Bangla letters by a group of participants. The images of these letters are provided in parquet format. Each image is

The Bengali language has 49 letters with 11 vowels, 38 consonants, and 18 potential diacritics. The handwritten Bengali characters consist of three components: grapheme-root, vowel-diacritic, and consonant-diacritic. To simplify the data for ML, we organize 168 grapheme-root, 10 vowel-diacritic, and 6 consonant-diacritic as unique labels. All the labels are then introduced as a unique integer. Table 1 summarizes the metadata information of the training dataset.
| Features | Description |
| image_id | Sample ID number for each handwritten image |
| grapheme_root | Unique number of vowels, consonants, or conjuncts |
| vowel_diacritic | Nasalization of vowels, and suppression of the inherent vowels |
| consonant_diacritic | Nasalization of consonants, and suppression of the inherent consonants |
| grapheme | Target variable |
 DownLoad:
CSV
DownLoad:
CSV
The raw training dataset has a total of 200, 840 observations with almost 10, 000 possible handwritten image variations. The raw testing dataset is created separately to distinguish it from the training dataset. Table 2 summarizes the metadata information of the test data.
| Features | Description |
| image_id | An unique image ID for each testing image |
| row_id | Test id of grapheme root, consonant diacritic, vowel diacritic |
| component | Grapheme root, consonant diacritic, vowel diacritic |
DownLoad:
CSV
The raw dataset is a set of images in the parquet format, as discussed in the previous section. The images are generally created from a possible set of grapheme writing, but it does not cover all the aspects of writing variations. To create more variations (more than 10, 000), dataset augmentation becomes a necessary step. In reality, it has around 13, 000 possible letter variations that make the problem harder than any other language grapheme classification. Therefore, a pre-processing of the dataset is done to increase the more number of grapheme variations.
We apply the following data augmentation techniques: (1) shifting, (2) rotating, (3) changing brightness, and (4) applying zoom. In all cases, some precautions are taken so that augmented handwritten images are well generated. For example, too much shifting or too much brightness can lose the image pixels [31]. Applying random values to those operations is also prohibited during our pre-processing of the dataset.
In terms of shifting, we apply the following image augmentation: width shift, and height shift on our images. In rotation, an image was rotated to (1) 8 degree, (2) 16 degree, and (3) 24 degree in both positive and negative direction. In case of zoom, we apply (1) 0.15%, and (2) 0.3% zoom in. Some sample output of Bangla handwritten letter's augmentation is shown in Figure 3.

The augmenting was minimized to only four options due to minimizing the risk of false image creation. As our dataset is related to characters, we need to verify that augmentation may add false image augmentation. For example, there is a horizontal flip option for image augmentation. If we apply that to our dataset, some non-Bangla handwritten images and the proposed model may learn wrongly to classify the handwritten letters.
This section describes the architecture of the models that we build for Bangla grapheme image classification. We also discuss the neural networks and their necessary layers useful for fitting data into the model.
A neural network is a series of algorithms that process the data through several layers that mimic how the human brain operates. A neural network for any input
|
$ y=f(∑jwjxj+b) $
|
(4.1) |
where,
|
$ yi=f(∑jwi,jxj+bi) $
|
(4.2) |
To obtain the final output with higher accuracy, multiple hidden layers are used. The final output can be obtained as:
|
$ z=f(∑kw(z)kyk+b(z)) $
|
(4.3) |
For image processing, we flat the image and feed it through neural networks. A vital characteristic of the images is that images have high dimensional vectors and take many parameters to characterize the network. To solve this issue, convolutional neural networks were used to reduce the number of parameters and adapt the network architecture specifically to vision tasks. CNN's are usually composed of a set of layers that can be grouped by their functionalities.
In this study, we implemented the CNN architecture with an encoder-decoder system. The encoder-decoder classifier works at the pixel level to extract the features. A recent work by Jong et al. shows that how encode-decoder networks using convolutional neural networks work as an optimizer for complex image data sets [33]. The encoder and decoder are developed using convolution, activation, batch normalization, and pooling layers. The detailed picture of these layers is described in the following section and shown in Figure 4.
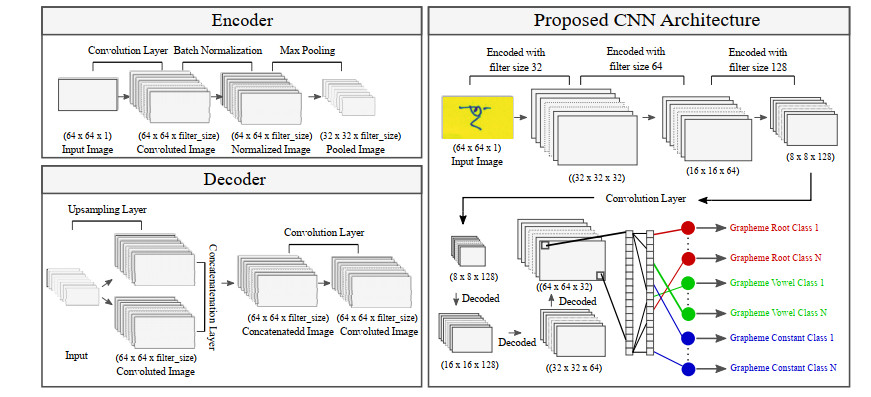
The convolution layer extracts feature maps from the input or previous layer. Each output layer is connected to some nodes from the previous layer [34,35] and valuable in the classification process. The convolutional layer is used to the sliding window through the image and convolves to create several sub-image, increasing the volume in terms of depth. The implementation view of the convolutional layer exists in both encoder and decoder, shown in Figure 4.
This section describes the activation function used in neural networks for proposed model training. We include the rectified Linear Unit (ReLU) function to add the non-linearity in the proposed network. The function is defined as
|
$ f(x)=max(0,x) $
|
(4.4) |
where it returns 0 for negative input and
There is some other nonlinearity function named as
|
$ σ(x)=11+e−x $
|
(4.5) |
which maps a real number x to a value between [0, 1]. Another nonlinear function
As the Bangla grapheme list contains more labels to detect than other language graphemes, we implement several non-linear layers as an encoder and a corresponding set of decoders to improve the recognition performance. However, we use ReLu due to its linear form, and this function improves the performance of classification compared to
In our model, we introduce such ReLu functionality after each non-pooling layer in the encoder to map the value of each neuron to an actual number. However, in some cases, such function can die during training. To solve this issue, leaky Relu has been added so that if there is any negative value, it will add a slight negative slope [38].
The batch normalization layer normalizes each input channel across a mini-batch [39,40]. Our study adjusts and scales the previously filtered sub-images and normalizes the output by subtracting the batch mean and diving by the standard deviation of the batch. Then, it shifts the image input by a learnable offset. Generally, using such a layer after a convolution layer and before non-linear layers is useful in speeding up the training and reducing sensitivity to network initialization [39].
We also implement a dropout layer during the final classification step. We use this layer to reduce the labels by setting zero, which has less probability in classification [41,42].
The pooling layer is mainly used to reduce the resolution of the feature maps. To be specific, this layer downsamples the volume along the image dimensions to reduce the size of representation and number of parameters to prevent overfitting. Our model uses a max-pooling layer in each encoder block, which downsamples the volume by taking max from each block.
The proposed model is trained with a configuration of the epoch, loss function, and batch size in the experiment. Also, the model contains trainable and non-trainable parameters. The trainable parameter size for the proposed model is 136, 048, 154, whereas the non-trainable parameter size is 448. There are thirteen convolution layers, three pooling layers, three normalization layers, and four dropout layers are used in our model. The experiment is implemented using the Python programming language with Keras [43], and Theano [44] library.
In terms of configuration, the proposed model uses 25 epochs with a batch training size of 128. To calculate the loss function, we use categorical cross-entropy for root, vowel, and constant classification. Mean Squared Error (MSE) is another metric to calculate loss function but categorical cross-entropy performance is better in classification tasks [45].
After developing the model in Python, we run it on an Intel (R) Core (TM) i7-7500U CPU @ 2.70 GHz machine with 16GB RAM. For both validation and training, the same batch size and epochs were used. The experimental results performance is calculated using accuracy and model performance evaluation metric. We also use a loss function to evaluate how well our deep learning model trains the given data. Both of these metrics are popular in classification tasks using deep learning [46,47,48].
In this section, we present the outcome of the model in terms of evaluation metrics. The proposed CNN method is applied in four different phases on four subsets of the grapheme dataset and produces the results. This way, we test how more Bangla handwritten letter images are helpful to produce better deep neural network models. However, conducting this research with more subsets of images will have computational and complexity challenges. In evaluation, the accuracy and loss of each epoch of training and validation are used.
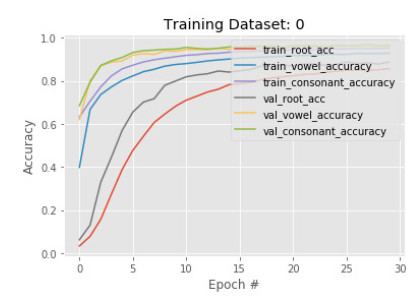
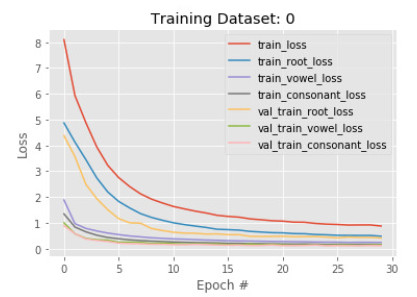
In the first phase, a subset of 50, 210 images is sent to training with 30 epoch. The results show that accuracy in detecting the root is less than the vowel and constant in both training and validation. The training and validation root accuracy are 85% and 88% respectively, where vowel accuracy is 92% and 95%, constant accuracy is 95% and 96%. This is because many root characters are needed to identify than the number of vowels, and constants are needed to identify. Figures 5 and 6 show the train and validation accuracy and cross-entropy loss over epochs. The results show that the model seems to have good converged behavior. It implies the model is well configured and no sign of over or underfitting.
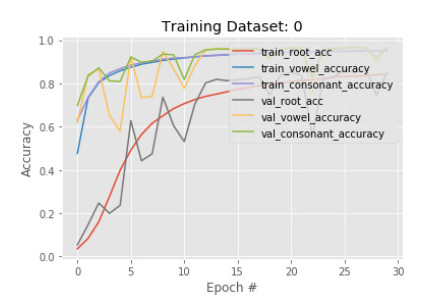
We also test how a CNN model with an encoder-decoder is compared to a traditional CNN that does not have an encoder and decoder concept. There are six convolution layers, three pooling layers, five normalization layers, and four dropout layers are used in the traditional CNN model. Figures 7 and 8 visualize the accuracy and loss of the simple CNN model for 30 epochs. The results we see from the figure that the loss and accuracy are fluctuating. The reason behind this, the simple CNN model is sensitive to noise and produces random classification results. This problem is also known as overfitting. The results show a better performance with an encoder and decoder concept than a traditional one.
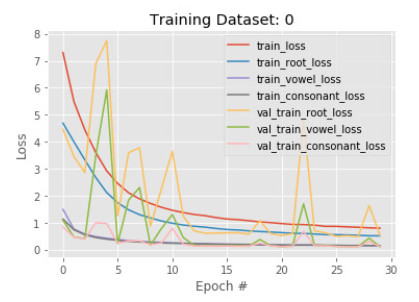
After getting a training accuracy of 85% in the first phase, we train another subset of images with the existing model. The hypothesis is that the more variations of images are trained, the more the model is learning when we have many root variations. We take a different 50, 210 images and train with the existing model with 30 epochs in this phase. Figures 9 and 10 visualize the accuracy and loss of the model in phase 2 respectively.
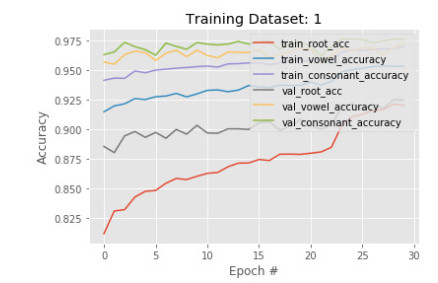
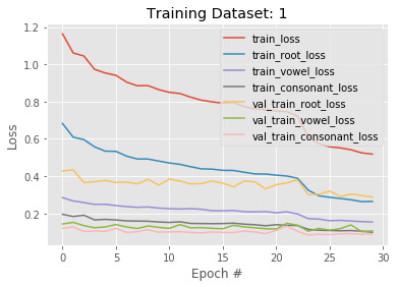
At the beginning of the training stage, we observe that train root accuracy drops from 85% to 80%. Not only train root accuracy, but all other categories' accuracy also drops after adding a new subset of images. The opposite behavior is observed in terms of the loss function. In epoch 0, loss functions of every category are increased. However, the final result of training 2 ends up with better train root, vowel, and constant accuracy of 92%, 95%, and 96%, respectively. In terms of the loss function, we observe the decrements over epochs in every case. These results imply that the model is appropriately converged and trained well due to more subset images used in the training process.
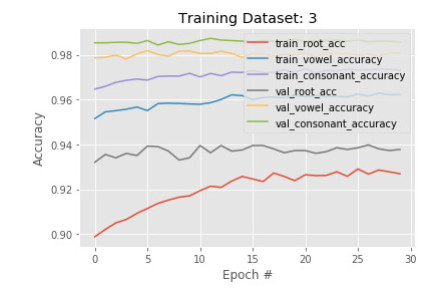
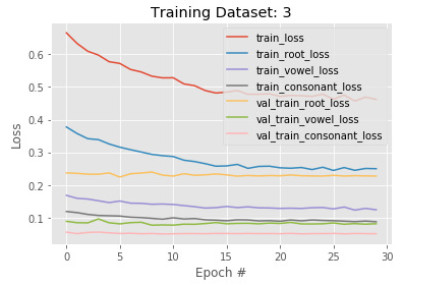
As a good result is maintained in our previous phases, we introduce another set of images with more variations in learning by our model. However, this time we observe little changes happen after the training. Figures 11 and 12 show the accuracy and loss of the model in phase 3. After another 30 epochs, training root, vowel, and constant accuracy are 94%, 96%, and 97%. The model root accuracy is increased by 2% and vowel, and constant accuracy are increased by 1%. The same behavior is found on the validation data also. It implies the model has converged very well and can be finalized by another training.
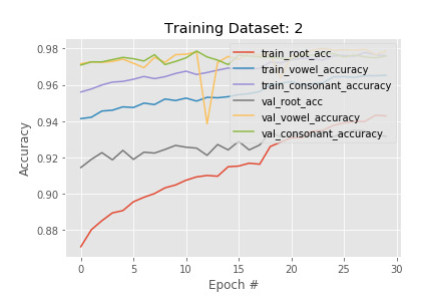
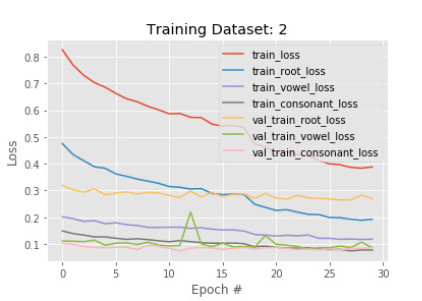
This final phase verifies the converge of accuracy and loss function by just doing another final training. Another set of 50, 210 images of Bangla handwritten letters are introduced. Figures 13 and 14 show the accuracy and loss function of the model in the final phase. The results show that root accuracy drops from 94% to 93% in the training stage, and the accuracy drops from 98% to 97% in the validation stage. Nevertheless, in all other cases, it seems improvement or no change. Also, the results start to create bumpy behavior in the accuracy metric, and loss functions are also converged. All the validation loss functions are 3% or below. These all results imply, our final model is converged and ready to report the final accuracy and loss.
Despite the advances in the classification of grapheme images in computer vision, Bengali grapheme classification has mainly remained unsolved due to confusing characters and many variations. Moreover, Bangla is one of the most spoken languages in Asia, and its grapheme classification has not been made, as there is no application as yet. However, many industries like banks, post offices, book publishers, and many more industries need the Bangla handwritten letters recognition.
In this paper, we implement a CNN architecture with encoder-decoder, classifying 168 grapheme roots, 11 vowel diacritics (or accents), and 7 consonant diacritics from handwritten Bangla letters. One of the challenges is to deal with 13, 000 grapheme variations, which are way more than English or Arabic grapheme variations. The performance results show that the proposed model achieves root accuracy of 93%, vowel accuracy of 96%, and consonant accuracy of 97%, which are significantly better in Bangla grapheme classification than in previous research. Finally, we report the detailed loss and accuracy in 4 phases of training and validation to show how our proposed model learns over time.
To illustrate the model performance, we compared our model with a traditional CNN applied to the same dataset. The results show that the accuracy and loss function fluctuate over time in the traditional CNN model, which means an over-fitted model. In comparison, we see that the proposed CNN model with encoder-decoder does much better in classifying Bangla handwritten grapheme images.
| [1] |
Volders PJ, Verheggen K, Menschaert G, et al. (2015) An update on LNCipedia: a database for annotated human lncRNA sequences. Nucleic Acids Res 43: D174-180. doi: 10.1093/nar/gku1060

|
| [2] | Amati B, Frank SR, Donjerkovic D, et al. (2001) Function of the c-Myc oncoprotein in chromatin remodeling and transcription. Biochim Biophys Acta 1471: M135-145. |
| [3] |
Bretones G, Delgado MD, Leon J (2015) Myc and cell cycle control. Biochim Biophys Acta 1849: 506-516. doi: 10.1016/j.bbagrm.2014.03.013
|
| [4] | Dang CV (2013) MYC, metabolism, cell growth, and tumorigenesis. Cold Spring Harb Perspect Med 3. |
| [5] |
McMahon SB (2014) MYC and the control of apoptosis. Cold Spring Harb Perspect Med 4: a014407. doi: 10.1101/cshperspect.a014407
|
| [6] | Vennstrom B, Sheiness D, Zabielski J, et al. (1982) Isolation and characterization of c-myc, a cellular homolog of the oncogene (v-myc) of avian myelocytomatosis virus strain 29. J Virol 42: 773-779. |
| [7] |
Zheng GX, Do BT, Webster DE, et al. (2014) Dicer-microRNA-Myc circuit promotes transcription of hundreds of long noncoding RNAs. Nat Struct Mol Biol 21: 585-590. doi: 10.1038/nsmb.2842
|
| [8] |
Winkle M, van den Berg A, Tayari M, et al. (2015) Long noncoding RNAs as a novel component of the Myc transcriptional network. FASEB J 29: 2338-2346. doi: 10.1096/fj.14-263889
|
| [9] |
Xiang JF, Yang L, Chen LL (2015) The long noncoding RNA regulation at the MYC locus. Curr Opin Genet Dev 33: 41-48. doi: 10.1016/j.gde.2015.07.001
|
| [10] |
Rinn JL, Chang HY (2012) Genome regulation by long noncoding RNAs. Annu Rev Biochem 81: 145-166. doi: 10.1146/annurev-biochem-051410-092902
|
| [11] |
Kapranov P, Cawley SE, Drenkow J, et al. (2002) Large-scale transcriptional activity in chromosomes 21 and 22. Science 296: 916-919. doi: 10.1126/science.1068597
|
| [12] |
Rinn JL, Euskirchen G, Bertone P, et al. (2003) The transcriptional activity of human Chromosome 22. Genes Dev 17: 529-540. doi: 10.1101/gad.1055203
|
| [13] |
Guttman M, Garber M, Levin JZ, et al. (2010) Ab initio reconstruction of cell type-specific transcriptomes in mouse reveals the conserved multi-exonic structure of lincRNAs. Nat Biotechnol 28: 503-510. doi: 10.1038/nbt.1633
|
| [14] |
Cabili MN, Trapnell C, Goff L, et al. (2011) Integrative annotation of human large intergenic noncoding RNAs reveals global properties and specific subclasses. Genes Dev 25: 1915-1927. doi: 10.1101/gad.17446611
|
| [15] |
Wu J, Okada T, Fukushima T, et al. (2012) A novel hypoxic stress-responsive long non-coding RNA transcribed by RNA polymerase III in Arabidopsis. RNA Biol 9: 302-313. doi: 10.4161/rna.19101
|
| [16] |
Derrien T, Johnson R, Bussotti G, et al. (2012) The GENCODE v7 catalog of human long noncoding RNAs: analysis of their gene structure, evolution, and expression. Genome Res 22: 1775-1789. doi: 10.1101/gr.132159.111
|
| [17] |
Gardini A, Shiekhattar R (2015) The many faces of long noncoding RNAs. FEBS J 282: 1647-1657. doi: 10.1111/febs.13101
|
| [18] |
Wilusz JE, Spector DL (2010) An unexpected ending: noncanonical 3' end processing mechanisms. RNA 16: 259-266. doi: 10.1261/rna.1907510
|
| [19] |
Zhang Y, Yang L, Chen LL (2014) Life without A tail: new formats of long noncoding RNAs. Int J Biochem Cell Biol 54: 338-349. doi: 10.1016/j.biocel.2013.10.009
|
| [20] |
Peart N, Sataluri A, Baillat D, et al. (2013) Non-mRNA 3' end formation: how the other half lives. Wiley Interdiscip Rev RNA 4: 491-506. doi: 10.1002/wrna.1174
|
| [21] | Ravasi T, Suzuki H, Pang KC, et al. (2006) Experimental validation of the regulated expression of large numbers of non-coding RNAs from the mouse genome. Genome Res 16: 11-19. |
| [22] |
Djebali S, Davis CA, Merkel A, et al. (2012) Landscape of transcription in human cells. Nature 489: 101-108. doi: 10.1038/nature11233
|
| [23] |
He S, Liu S, Zhu H (2011) The sequence, structure and evolutionary features of HOTAIR in mammals. BMC Evol Biol 11: 102. doi: 10.1186/1471-2148-11-102
|
| [24] |
Brown JA, Bulkley D, Wang J, et al. (2014) Structural insights into the stabilization of MALAT1 noncoding RNA by a bipartite triple helix. Nat Struct Mol Biol 21: 633-640. doi: 10.1038/nsmb.2844
|
| [25] |
Brown JA, Valenstein ML, Yario TA, et al. (2012) Formation of triple-helical structures by the 3'-end sequences of MALAT1 and MENbeta noncoding RNAs. Proc Natl Acad Sci U S A 109: 19202-19207. doi: 10.1073/pnas.1217338109
|
| [26] |
Smith MA, Gesell T, Stadler PF, et al. (2013) Widespread purifying selection on RNA structure in mammals. Nucleic Acids Res 41: 8220-8236. doi: 10.1093/nar/gkt596
|
| [27] |
Somarowthu S, Legiewicz M, Chillon I, et al. (2015) HOTAIR forms an intricate and modular secondary structure. Mol Cell 58: 353-361. doi: 10.1016/j.molcel.2015.03.006
|
| [28] |
Mortimer SA, Kidwell MA, Doudna JA (2014) Insights into RNA structure and function from genome-wide studies. Nat Rev Genet 15: 469-479. doi: 10.1038/nrg3681
|
| [29] | Ding Y, Tang Y, Kwok CK, et al. (2014) In vivo genome-wide profiling of RNA secondary structure reveals novel regulatory features. Nature 505: 696-700. |
| [30] |
Kertesz M, Wan Y, Mazor E, et al. (2010) Genome-wide measurement of RNA secondary structure in yeast. Nature 467: 103-107. doi: 10.1038/nature09322
|
| [31] |
Lucks JB, Mortimer SA, Trapnell C, et al. (2011) Multiplexed RNA structure characterization with selective 2'-hydroxyl acylation analyzed by primer extension sequencing (SHAPE-Seq). Proc Natl Acad Sci U S A 108: 11063-11068. doi: 10.1073/pnas.1106501108
|
| [32] |
Seetin MG, Kladwang W, Bida JP, et al. (2014) Massively parallel RNA chemical mapping with a reduced bias MAP-seq protocol. Methods Mol Biol 1086: 95-117. doi: 10.1007/978-1-62703-667-2_6
|
| [33] |
Underwood JG, Uzilov AV, Katzman S, et al. (2010) FragSeq: transcriptome-wide RNA structure probing using high-throughput sequencing. Nat Methods 7: 995-1001. doi: 10.1038/nmeth.1529
|
| [34] |
Aviran S, Trapnell C, Lucks JB, et al. (2011) Modeling and automation of sequencing-based characterization of RNA structure. Proc Natl Acad Sci U S A 108: 11069-11074. doi: 10.1073/pnas.1106541108
|
| [35] | Rouskin S, Zubradt M, Washietl S, et al. (2014) Genome-wide probing of RNA structure reveals active unfolding of mRNA structures in vivo. Nature 505: 701-705. |
| [36] |
Novikova IV, Hennelly SP, Sanbonmatsu KY (2013) Tackling structures of long noncoding RNAs. Int J Mol Sci 14: 23672-23684. doi: 10.3390/ijms141223672
|
| [37] |
Fatica A, Bozzoni I (2014) Long non-coding RNAs: new players in cell differentiation and development. Nat Rev Genet 15: 7-21. doi: 10.1038/nri3777
|
| [38] |
Batista PJ, Chang HY (2013) Long noncoding RNAs: cellular address codes in development and disease. Cell 152: 1298-1307. doi: 10.1016/j.cell.2013.02.012
|
| [39] |
Batista PJ, Chang HY (2013) Cytotopic localization by long noncoding RNAs. Curr Opin Cell Biol 25: 195-199. doi: 10.1016/j.ceb.2012.12.001
|
| [40] |
Han X, Yang F, Cao H, et al. (2015) Malat1 regulates serum response factor through miR-133 as a competing endogenous RNA in myogenesis. FASEB J 29: 3054-3064. doi: 10.1096/fj.14-259952
|
| [41] | Yoon JH, Abdelmohsen K, Kim J, et al. (2013) Scaffold function of long non-coding RNA HOTAIR in protein ubiquitination. Nat Commun 4: 2939. |
| [42] |
McHugh CA, Chen CK, Chow A, et al. (2015) The Xist lncRNA interacts directly with SHARP to silence transcription through HDAC3. Nature 521: 232-236. doi: 10.1038/nature14443
|
| [43] |
Deng K, Guo X, Wang H, et al. (2014) The lncRNA-MYC regulatory network in cancer. Tumour Biol 35: 9497-9503. doi: 10.1007/s13277-014-2511-y
|
| [44] |
Beroukhim R, Mermel CH, Porter D, et al. (2010) The landscape of somatic copy-number alteration across human cancers. Nature 463: 899-905. doi: 10.1038/nature08822
|
| [45] | Colombo T, Farina L, Macino G, et al. (2015) PVT1: a rising star among oncogenic long noncoding RNAs. Biomed Res Int 2015: 304208. |
| [46] |
Walz S, Lorenzin F, Morton J, et al. (2014) Activation and repression by oncogenic MYC shape tumour-specific gene expression profiles. Nature 511: 483-487. doi: 10.1038/nature13473
|
| [47] |
Carramusa L, Contino F, Ferro A, et al. (2007) The PVT-1 oncogene is a Myc protein target that is overexpressed in transformed cells. J Cell Physiol 213: 511-518. doi: 10.1002/jcp.21133
|
| [48] | Tseng YY, Moriarity BS, Gong W, et al. (2014) PVT1 dependence in cancer with MYC copy-number increase. Nature 512: 82-86. |
| [49] |
Zanke BW, Greenwood CM, Rangrej J, et al. (2007) Genome-wide association scan identifies a colorectal cancer susceptibility locus on chromosome 8q24. Nat Genet 39: 989-994. doi: 10.1038/ng2089
|
| [50] |
Tenesa A, Farrington SM, Prendergast JG, et al. (2008) Genome-wide association scan identifies a colorectal cancer susceptibility locus on 11q23 and replicates risk loci at 8q24 and 18q21. Nat Genet 40: 631-637. doi: 10.1038/ng.133
|
| [51] |
Tomlinson I, Webb E, Carvajal-Carmona L, et al. (2007) A genome-wide association scan of tag SNPs identifies a susceptibility variant for colorectal cancer at 8q24.21. Nat Genet 39: 984-988. doi: 10.1038/ng2085
|
| [52] |
Nissan A, Stojadinovic A, Mitrani-Rosenbaum S, et al. (2012) Colon cancer associated transcript-1: a novel RNA expressed in malignant and pre-malignant human tissues. Int J Cancer 130: 1598-1606. doi: 10.1002/ijc.26170
|
| [53] |
Ahmadiyeh N, Pomerantz MM, Grisanzio C, et al. (2010) 8q24 prostate, breast, and colon cancer risk loci show tissue-specific long-range interaction with MYC. Proc Natl Acad Sci U S A 107: 9742-9746. doi: 10.1073/pnas.0910668107
|
| [54] |
Kim T, Cui R, Jeon YJ, et al. (2014) Long-range interaction and correlation between MYC enhancer and oncogenic long noncoding RNA CARLo-5. Proc Natl Acad Sci U S A 111: 4173-4178. doi: 10.1073/pnas.1400350111
|
| [55] |
Pomerantz MM, Ahmadiyeh N, Jia L, et al. (2009) The 8q24 cancer risk variant rs6983267 shows long-range interaction with MYC in colorectal cancer. Nat Genet 41: 882-884. doi: 10.1038/ng.403
|
| [56] |
Sur IK, Hallikas O, Vaharautio A, et al. (2012) Mice lacking a Myc enhancer that includes human SNP rs6983267 are resistant to intestinal tumors. Science 338: 1360-1363. doi: 10.1126/science.1228606
|
| [57] |
Tuupanen S, Turunen M, Lehtonen R, et al. (2009) The common colorectal cancer predisposition SNP rs6983267 at chromosome 8q24 confers potential to enhanced Wnt signaling. Nat Genet 41: 885-890. doi: 10.1038/ng.406
|
| [58] |
Xiang JF, Yin QF, Chen T, et al. (2014) Human colorectal cancer-specific CCAT1-L lncRNA regulates long-range chromatin interactions at the MYC locus. Cell Res 24: 513-531. doi: 10.1038/cr.2014.35
|
| [59] |
Deng L, Yang SB, Xu FF, et al. (2015) Long noncoding RNA CCAT1 promotes hepatocellular carcinoma progression by functioning as let-7 sponge. J Exp Clin Cancer Res 34: 18. doi: 10.1186/s13046-015-0136-7
|
| [60] |
He X, Tan X, Wang X, et al. (2014) C-Myc-activated long noncoding RNA CCAT1 promotes colon cancer cell proliferation and invasion. Tumour Biol 35: 12181-12188. doi: 10.1007/s13277-014-2526-4
|
| [61] |
Yang F, Xue X, Bi J, et al. (2013) Long noncoding RNA CCAT1, which could be activated by c-Myc, promotes the progression of gastric carcinoma. J Cancer Res Clin Oncol 139: 437-445. doi: 10.1007/s00432-012-1324-x
|
| [62] |
Ling H, Spizzo R, Atlasi Y, et al. (2013) CCAT2, a novel noncoding RNA mapping to 8q24, underlies metastatic progression and chromosomal instability in colon cancer. Genome Res 23: 1446-1461. doi: 10.1101/gr.152942.112
|
| [63] | Kim T, Jeon YJ, Cui R, et al. (2015) Role of MYC-regulated long noncoding RNAs in cell cycle regulation and tumorigenesis. J Natl Cancer Inst 107. |
| [64] | Ye Z, Zhou M, Tian B, et al. (2015) Expression of lncRNA-CCAT1, E-cadherin and N-cadherin in colorectal cancer and its clinical significance. Int J Clin Exp Med 8: 3707-3715. |
| [65] |
Alaiyan B, Ilyayev N, Stojadinovic A, et al. (2013) Differential expression of colon cancer associated transcript1 (CCAT1) along the colonic adenoma-carcinoma sequence. BMC Cancer 13: 196. doi: 10.1186/1471-2407-13-196
|
| [66] | Kim T, Cui R, Jeon YJ, et al. (2015) MYC-repressed long noncoding RNAs antagonize MYC-induced cell proliferation and cell cycle progression. Oncotarget. |
| [67] |
Prensner JR, Chen W, Han S, et al. (2014) The long non-coding RNA PCAT-1 promotes prostate cancer cell proliferation through cMyc. Neoplasia 16: 900-908. doi: 10.1016/j.neo.2014.09.001
|
| [68] |
Yamamura S, Saini S, Majid S, et al. (2012) MicroRNA-34a modulates c-Myc transcriptional complexes to suppress malignancy in human prostate cancer cells. PLoS One 7: e29722. doi: 10.1371/journal.pone.0029722
|
| [69] |
Siemens H, Jackstadt R, Hunten S, et al. (2011) miR-34 and SNAIL form a double-negative feedback loop to regulate epithelial-mesenchymal transitions. Cell Cycle 10: 4256-4271. doi: 10.4161/cc.10.24.18552
|
| [70] |
Benassi B, Flavin R, Marchionni L, et al. (2012) MYC is activated by USP2a-mediated modulation of microRNAs in prostate cancer. Cancer Discov 2: 236-247. doi: 10.1158/2159-8290.CD-11-0219
|
| [71] |
Poliseno L, Salmena L, Zhang J, et al. (2010) A coding-independent function of gene and pseudogene mRNAs regulates tumour biology. Nature 465: 1033-1038. doi: 10.1038/nature09144
|
| [72] |
Salmena L, Poliseno L, Tay Y, et al. (2011) A ceRNA hypothesis: the Rosetta Stone of a hidden RNA language? Cell 146: 353-358. doi: 10.1016/j.cell.2011.07.014
|
| [73] |
Ge X, Chen Y, Liao X, et al. (2013) Overexpression of long noncoding RNA PCAT-1 is a novel biomarker of poor prognosis in patients with colorectal cancer. Med Oncol 30: 588. doi: 10.1007/s12032-013-0588-6
|
| [74] |
Chung S, Nakagawa H, Uemura M, et al. (2011) Association of a novel long non-coding RNA in 8q24 with prostate cancer susceptibility. Cancer Sci 102: 245-252. doi: 10.1111/j.1349-7006.2010.01737.x
|
| [75] |
Hung CL, Wang LY, Yu YL, et al. (2014) A long noncoding RNA connects c-Myc to tumor metabolism. Proc Natl Acad Sci U S A 111: 18697-18702. doi: 10.1073/pnas.1415669112
|
| [76] |
Chu C, Qu K, Zhong FL, et al. (2011) Genomic maps of long noncoding RNA occupancy reveal principles of RNA-chromatin interactions. Mol Cell 44: 667-678. doi: 10.1016/j.molcel.2011.08.027
|
| [77] | Pickard MR, Williams GT (2015) Molecular and Cellular Mechanisms of Action of Tumour Suppressor GAS5 LncRNA. Genes (Basel) 6: 484-499. |
| [78] |
Hu G, Lou Z, Gupta M (2014) The long non-coding RNA GAS5 cooperates with the eukaryotic translation initiation factor 4E to regulate c-Myc translation. PLoS One 9: e107016. doi: 10.1371/journal.pone.0107016
|
| [79] |
Mourtada-Maarabouni M, Pickard MR, Hedge VL, et al. (2009) GAS5, a non-protein-coding RNA, controls apoptosis and is downregulated in breast cancer. Oncogene 28: 195-208. doi: 10.1038/onc.2008.373
|
| [80] |
Pickard MR, Mourtada-Maarabouni M, Williams GT (2013) Long non-coding RNA GAS5 regulates apoptosis in prostate cancer cell lines. Biochim Biophys Acta 1832: 1613-1623. doi: 10.1016/j.bbadis.2013.05.005
|
| [81] |
Sun M, Jin FY, Xia R, et al. (2014) Decreased expression of long noncoding RNA GAS5 indicates a poor prognosis and promotes cell proliferation in gastric cancer. BMC Cancer 14: 319. doi: 10.1186/1471-2407-14-319
|
| [82] | Tu ZQ, Li RJ, Mei JZ, et al. (2014) Down-regulation of long non-coding RNA GAS5 is associated with the prognosis of hepatocellular carcinoma. Int J Clin Exp Pathol 7: 4303-4309. |
| [83] | Li LJ, Zhu JL, Bao WS, et al. (2014) Long noncoding RNA GHET1 promotes the development of bladder cancer. Int J Clin Exp Pathol 7: 7196-7205. |
| [84] |
Yang F, Xue X, Zheng L, et al. (2014) Long non-coding RNA GHET1 promotes gastric carcinoma cell proliferation by increasing c-Myc mRNA stability. FEBS J 281: 802-813. doi: 10.1111/febs.12625
|
| [85] |
Lemm I, Ross J (2002) Regulation of c-myc mRNA decay by translational pausing in a coding region instability determinant. Mol Cell Biol 22: 3959-3969. doi: 10.1128/MCB.22.12.3959-3969.2002
|
| [86] | Weidensdorfer D, Stohr N, Baude A, et al. (2009) Control of c-myc mRNA stability by IGF2BP1-associated cytoplasmic RNPs. RNA 15: 104-115. |
| [87] |
Matouk IJ, DeGroot N, Mezan S, et al. (2007) The H19 non-coding RNA is essential for human tumor growth. PLoS One 2: e845. doi: 10.1371/journal.pone.0000845
|
| [88] |
Matouk IJ, Raveh E, Abu-lail R, et al. (2014) Oncofetal H19 RNA promotes tumor metastasis. Biochim Biophys Acta 1843: 1414-1426. doi: 10.1016/j.bbamcr.2014.03.023
|
| [89] | Jiang X, Yan Y, Hu M, et al. (2015) Increased level of H19 long noncoding RNA promotes invasion, angiogenesis, and stemness of glioblastoma cells. J Neurosurg: 1-8. |
| [90] |
Lottin S, Adriaenssens E, Dupressoir T, et al. (2002) Overexpression of an ectopic H19 gene enhances the tumorigenic properties of breast cancer cells. Carcinogenesis 23: 1885-1895. doi: 10.1093/carcin/23.11.1885
|
| [91] |
Luo M, Li Z, Wang W, et al. (2013) Long non-coding RNA H19 increases bladder cancer metastasis by associating with EZH2 and inhibiting E-cadherin expression. Cancer Lett 333: 213-221. doi: 10.1016/j.canlet.2013.01.033
|
| [92] |
Ma C, Nong K, Zhu H, et al. (2014) H19 promotes pancreatic cancer metastasis by derepressing let-7's suppression on its target HMGA2-mediated EMT. Tumour Biol 35: 9163-9169. doi: 10.1007/s13277-014-2185-5
|
| [93] |
Zhang EB, Han L, Yin DD, et al. (2014) c-Myc-induced, long, noncoding H19 affects cell proliferation and predicts a poor prognosis in patients with gastric cancer. Med Oncol 31: 914. doi: 10.1007/s12032-014-0914-7
|
| [94] |
Barsyte-Lovejoy D, Lau SK, Boutros PC, et al. (2006) The c-Myc oncogene directly induces the H19 noncoding RNA by allele-specific binding to potentiate tumorigenesis. Cancer Res 66: 5330-5337. doi: 10.1158/0008-5472.CAN-06-0037
|
| [95] |
Shi Y, Wang Y, Luan W, et al. (2014) Long non-coding RNA H19 promotes glioma cell invasion by deriving miR-675. PLoS One 9: e86295. doi: 10.1371/journal.pone.0086295
|
| [96] |
Kallen AN, Zhou XB, Xu J, et al. (2013) The imprinted H19 lncRNA antagonizes let-7 microRNAs. Mol Cell 52: 101-112. doi: 10.1016/j.molcel.2013.08.027
|
| [97] |
Yan L, Zhou J, Gao Y, et al. (2015) Regulation of tumor cell migration and invasion by the H19/let-7 axis is antagonized by metformin-induced DNA methylation. Oncogene 34: 3076-3084. doi: 10.1038/onc.2014.236
|
| [98] |
Liao LM, Sun XY, Liu AW, et al. (2014) Low expression of long noncoding XLOC_010588 indicates a poor prognosis and promotes proliferation through upregulation of c-Myc in cervical cancer. Gynecol Oncol 133: 616-623. doi: 10.1016/j.ygyno.2014.03.555
|
| [99] |
Mestdagh P, Fredlund E, Pattyn F, et al. (2010) An integrative genomics screen uncovers ncRNA T-UCR functions in neuroblastoma tumours. Oncogene 29: 3583-3592. doi: 10.1038/onc.2010.106
|
| [100] |
Atmadibrata B, Liu PY, Sokolowski N, et al. (2014) The novel long noncoding RNA linc00467 promotes cell survival but is down-regulated by N-Myc. PLoS One 9: e88112. doi: 10.1371/journal.pone.0088112
|
| [101] |
Tee AE, Ling D, Nelson C, et al. (2014) The histone demethylase JMJD1A induces cell migration and invasion by up-regulating the expression of the long noncoding RNA MALAT1. Oncotarget 5: 1793-1804. doi: 10.18632/oncotarget.1785
|
| [102] | Liu PY, Erriquez D, Marshall GM, et al. (2014) Effects of a novel long noncoding RNA, lncUSMycN, on N-Myc expression and neuroblastoma progression. J Natl Cancer Inst 106. |
| [103] |
Vadie N, Saayman S, Lenox A, et al. (2015) MYCNOS functions as an antisense RNA regulating MYCN. RNA Biol 12: 893-899. doi: 10.1080/15476286.2015.1063773
|
| [104] |
Stanton BR, Perkins AS, Tessarollo L, et al. (1992) Loss of N-myc function results in embryonic lethality and failure of the epithelial component of the embryo to develop. Genes Dev 6: 2235-2247. doi: 10.1101/gad.6.12a.2235
|
| [105] | Stanton BR, Parada LF (1992) The N-myc proto-oncogene: developmental expression and in vivo site-directed mutagenesis. Brain Pathol 2: 71-83. |

Michael J. Hamilton, Matthew D. Young, Silvia Sauer, Ernest Martinez. The interplay of long non-coding RNAs and MYC in cancer[J]. AIMS Biophysics, 2015, 2(4): 794-809. doi: 10.3934/biophy.2015.4.794

| Features | Description |
| image_id | Sample ID number for each handwritten image |
| grapheme_root | Unique number of vowels, consonants, or conjuncts |
| vowel_diacritic | Nasalization of vowels, and suppression of the inherent vowels |
| consonant_diacritic | Nasalization of consonants, and suppression of the inherent consonants |
| grapheme | Target variable |
DownLoad:
CSV
| Features | Description |
| image_id | An unique image ID for each testing image |
| row_id | Test id of grapheme root, consonant diacritic, vowel diacritic |
| component | Grapheme root, consonant diacritic, vowel diacritic |
DownLoad:
CSV
| Features | Description |
| image_id | Sample ID number for each handwritten image |
| grapheme_root | Unique number of vowels, consonants, or conjuncts |
| vowel_diacritic | Nasalization of vowels, and suppression of the inherent vowels |
| consonant_diacritic | Nasalization of consonants, and suppression of the inherent consonants |
| grapheme | Target variable |
| Features | Description |
| image_id | An unique image ID for each testing image |
| row_id | Test id of grapheme root, consonant diacritic, vowel diacritic |
| component | Grapheme root, consonant diacritic, vowel diacritic |