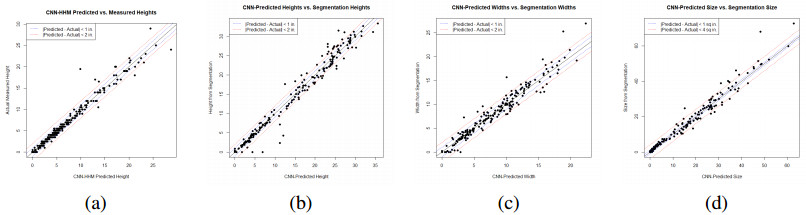
High-throughput plant phenotyping systems capable of producing large numbers of images have been constructed in recent years. In order for statistical analysis of plant traits to be possible, image processing must take place. This paper considers the extraction of plant trait data from soybean images taken in the University of Nebraska-Lincoln Greenhouse Innovation Center. Using transfer learning, which utilizes the VGG16 model along with its parameters in the convolutional layers as part of our model, convolutional neural networks (CNNs) are trained to predict measurements such as height, width, and size of the plants. It is demonstrated that, by making use of transfer learning, our CNNs efficiently and accurately extract the trait measurements from the images using a relatively small amount of training data. This approach to plant trait extraction is new to the field of plant phenomics, and the superiority of our CNN-based trait extraction approach to an image segmentation-based approach is demonstrated.
Citation: Jason Adams, Yumou Qiu, Luis Posadas, Kent Eskridge, George Graef. Phenotypic trait extraction of soybean plants using deep convolutional neural networks with transfer learning[J]. Big Data and Information Analytics, 2021, 6: 26-40. doi: 10.3934/bdia.2021003
High-throughput plant phenotyping systems capable of producing large numbers of images have been constructed in recent years. In order for statistical analysis of plant traits to be possible, image processing must take place. This paper considers the extraction of plant trait data from soybean images taken in the University of Nebraska-Lincoln Greenhouse Innovation Center. Using transfer learning, which utilizes the VGG16 model along with its parameters in the convolutional layers as part of our model, convolutional neural networks (CNNs) are trained to predict measurements such as height, width, and size of the plants. It is demonstrated that, by making use of transfer learning, our CNNs efficiently and accurately extract the trait measurements from the images using a relatively small amount of training data. This approach to plant trait extraction is new to the field of plant phenomics, and the superiority of our CNN-based trait extraction approach to an image segmentation-based approach is demonstrated.

| [1] |
Chéné Y, Rousseau D, Lucidarme P, et al. (2012) On the use of depth camera for 3D phenotyping of entire plants. Comput Elect Agr 82: 122-127. doi: 10.1016/j.compag.2011.12.007

|
| [2] | McCormick RF, Truong SK, Mullet JE, (2016) 3D sorghum reconstructions from depth images identify QTL regulating shoot architecture. Plant physiol 172: 823-834. |
| [3] |
Xiong X, Yu L, Yang W, et al. (2017) A high-throughput stereo-imaging system for quantifying rape leaf traits during the seedling stage. Plant Methods 13: 1-17. doi: 10.1186/s13007-016-0152-4
|
| [4] |
Peñuelas J and Filella I, (1998) Visible and near-infrared reflectance techniques for diagnosing plant physiological status. Trends Plant Sci 3: 151-156. doi: 10.1016/S1360-1385(98)01213-8
|
| [5] |
Lin Y, (2015) LiDAR: An important tool for next-generation phenotyping technology of high potential for plant phenomics? Comput Elect Agr 119: 61-73. doi: 10.1016/j.compag.2015.10.011
|
| [6] |
Fahlgren N, Gehan MA, Baxter I, (2015) Lights, camera, action: high-throughput plant phenotyping is ready for a close-up. Curr Opin Plant Biol 24: 93-99. doi: 10.1016/j.pbi.2015.02.006
|
| [7] |
Miller ND, Parks BM, Spalding EP, (2007) Computer-vision analysis of seedling responses to light and gravity. Plant J 52: 374-381. doi: 10.1111/j.1365-313X.2007.03237.x
|
| [8] |
Miao C, Yang J, Schnable JC, (2019) Optimising the identification of causal variants across varying genetic architectures in crops. Plant Biotech J 17: 893-905. doi: 10.1111/pbi.13023
|
| [9] |
Xavier A, Hall B, Casteel S, et al. (2017) Using unsupervised learning techniques to assess interactions among complex traits in soybeans. Euphytica 213: 1-18. doi: 10.1007/s10681-017-1975-4
|
| [10] |
Habier D, Fernando RL, Kizilkaya K, et al. (2011) Extension of the Bayesian alphabet for genomic selection. BMC Bioinfor 12: 1-12. doi: 10.1186/1471-2105-12-186
|
| [11] |
Gage JL, Richards E, Lepak N, et al. (2019) In-field whole-plant maize architecture characterized by subcanopy rovers and latent space phenotyping. Plant Phenome J 2: 1-11. doi: 10.2135/tppj2019.07.0011
|
| [12] |
Wu H, Wiesner-Hanks T, Stewart EL, et al. (2019) Autonomous detection of plant disease symptoms directly from aerial imagery. Plant Phenome J 2: 1-9. doi: 10.2135/tppj2019.03.0006
|
| [13] |
Choudhury SD, Bashyam S, Qiu Y, et al. (2018) Holistic and component plant phenotyping using temporal image sequence. Plant Methods 14: 1-21. doi: 10.1186/s13007-017-0271-6
|
| [14] | Johnson RA and Wichern DW, (2002) Applied Multivariate Statistical Analysis. Prentice Hall Upper Saddle River, NJ. |
| [15] |
Klukas C, Chen D, Pape JM, (2014) Integrated analysis platform: an open-source information system for high-throughput plant phenotyping. Plant Physiol 165: 506-518. doi: 10.1104/pp.113.233932
|
| [16] |
Hartmann A, Czauderna T, Hoffmann R, et al. (2011) HTPheno: an image analysis pipeline for high-throughput plant phenotyping. BMC Bioinfor 12: 1-9. doi: 10.1186/1471-2105-12-148
|
| [17] |
Ge Y, Bai G, Stoerger V, et al. (2016) Temporal dynamics of maize plant growth, water use, and leaf water content using automated high throughput RGB and hyperspectral imaging. Comput Elect Agr 127: 625-632. doi: 10.1016/j.compag.2016.07.028
|
| [18] |
Adams J, Qiu Y, Xu Y, et al. (2020) Plant segmentation by supervised machine learning methods. Plant Phenome J 3: e20001. doi: 10.1002/ppj2.20001
|
| [19] | Simonyan K, Zisserman A (2014) Very deep convolutional networks for large-scale image recognition. aarXiv: 14091556. |
| [20] | Krizhevsky A, Sutskever I, Hinton GE, (2012) Imagenet classification with deep convolutional neural networks. Adv Neural Infor Process Syst 25: 1097-1105. |
| [21] | Zhu X and Ramanan D, (2012) Face detection, pose estimation, and landmark localization in the wild. 2012 IEEE Confer Comput Vision Pattern Recognit: 2879-2886. |
| [22] | Gatys LA, Ecker AS, Bethge M, (2016) Image style transfer using convolutional neural networks. Process IEEE Confer Comput Vision Pattern Recognit: 2414-2423. |
| [23] | Liang Z, Powell A, Ersoy I, et al. (2016) CNN-based image analysis for malaria diagnosis. 2016 IEEE Int. Confer Bioinfor Biomed (BIBM): 493-496. |
| [24] |
LeCun Y, Bengio Y, Hinton G, (2015) Deep learning. Nature 521: 436-444. doi: 10.1038/nature14539
|
| [25] | Goodfellow I, Bengio Y, Courville A, et al. (2016) Deep Learning. MIT Press, Cambridge. |
| [26] | Miao C, Hoban TP, Pages A, et al. (2019) Simulated plant images improve maize leaf counting accuracy. BioRxiv: 706994. |
| [27] |
Lu H, Cao Z, Xiao Y, et al. (2017) TasselNet: counting maize tassels in the wild via local counts regression network. Plant Methods 13: 1-17. doi: 10.1186/s13007-016-0152-4
|
| [28] | Pound MP, Atkinson JA, Wells DM, et al. (2017) Deep learning for multi-task plant phenotyping. Process IEEE Int Confer Comput Vision Workshops: 2055-2063. |
| [29] | He K, Zhang X, Ren S, et al. (2016) Deep residual learning for image recognition. Process IEEE Confer Comput Vision Pattern Recognit: 770-778. |
| [30] | Orhan AE and Pitkow X, (2017) Skip connections eliminate singularities. arXiv: 170109175. |
| [31] | Aich S, Josuttes A, Ovsyannikov I, et al. (2018) Deepwheat: Estimating phenotypic traits from crop images with deep learning. 2018 IEEE Winter Confer Appl Comput Vision (WACV): 323-332. |
| [32] |
Badrinarayanan V, Kendall A, Cipolla R, (2017) Segnet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans Pattern Anal Machine Intell 39: 2481-2495. doi: 10.1109/TPAMI.2016.2644615
|
| [33] | Szegedy C, Liu W, Jia Y, et al. (2015) Going deeper with convolutions. Process IEEE Confer Comput Vision Pattern Recognit: 1-9. |
| [34] | Szegedy C, Ioffe S, Vanhoucke V, et al. (2017) Inception-v4, inception-resnet and the impact of residual connections on learning. Process AAAI Confer Artif Intell 31. |
| [35] | Pan SJ and Yang Q, (2009) A survey on transfer learning. IEEE Trans Knowl Data Eng 22: 1345-1359. |
| [36] |
LeCun Y, Bottou L, Bengio Y, et al. (1998) Gradient-based learning applied to document recognition. Process IEEE 86: 2278-2324. doi: 10.1109/5.726791
|
| [37] |
Shin H-C, Roth HR, Gao M, et al. (2016) Deep convolutional neural networks for computer-aided detection: CNN architectures, dataset characteristics and transfer learning. IEEE Trans Med Imag 35: 1285-1298. doi: 10.1109/TMI.2016.2528162
|
| [38] |
Han D, Liu Q, Fan W, (2018) A new image classification method using CNN transfer learning and web data augmentation. Expert Syst Appl 95: 43-56. doi: 10.1016/j.eswa.2017.11.028
|
| [39] |
Akcay S, Kundegorski ME, Willcocks CG, et al. (2018) Using deep convolutional neural network architectures for object classification and detection within x-ray baggage security imagery. IEEE Trans Infor Forensics Security 13: 2203-2215. doi: 10.1109/TIFS.2018.2812196
|
| [40] | Xie M, Jean N, Burke M, et al. (2016) Transfer learning from deep features for remote sensing and poverty mapping. Procee AAAI Confer Artif Intell 30. |
| [41] | Deng J, Dong W, Socher R, et al. (2009) Imagenet: A large-scale hierarchical image database. 2009 IEEE Confer Comput Vision Pattern Recognit: 248-255. |
| [42] | Shapiro L, (1992) Computer Vision and Image Processing: Academic Press. |
| [43] | Davies ER, (2012) Computer and Machine Vision: Theory, Algorithms, Practicalities. Academic Press. |
| [44] | Nielsen MA, (2015) Neural Networks and Deep Learning. Determination Press, San Francisco, CA. |
| [45] | Kingma DP and Ba J, (2014) Adam: A method for stochastic optimization. arXiv: 14126980. |
| [46] |
Zhang L, Allen Jr LH, Vaughan MM, et al. (2014) Solar ultraviolet radiation exclusion increases soybean internode lengths and plant height. Agric For Meteorol 184: 170-178. doi: 10.1016/j.agrformet.2013.09.011
|
| [47] |
Allen Jr LH, Zhang L, Boote KJ, et al. (2018) Elevated temperature intensity, timing, and duration of exposure affect soybean internode elongation, mainstem node number, and pod number per plant. Crop J 6: 148-161. doi: 10.1016/j.cj.2017.10.005
|
| [48] | Downs J and Thomas JF, (1990) Morphology and reproductive development of soybean under artificial conditions. Biotronics 19: 19-32. |
| [49] | Guo X, Qiu Y, Nettleton D, et al. (2020) Automatic traits extraction and fitting for field high-throughput phenotyping systems. bioRxiv. |
| [50] | Girshick R, (2015) Fast r-CNN. Procee IEEE Int Confer Comput Vision: 1440-1448. |
| [51] |
Ren S, He K, Girshick R, et al. (2016) Faster R-CNN: towards real-time object detection with region proposal networks. IEEE Trans Pattern Anal Machine Intell 39: 1137-1149. doi: 10.1109/TPAMI.2016.2577031
|
| [52] | Redmon J, Divvala S, Girshick R, et al. (2016) You only look once: Unified, real-time object detection. Procee IEEE Confer Comput Vision Pattern Recognit: 779-788. |



Figures(4) / Tables(4)

Jason Adams, Yumou Qiu, Luis Posadas, Kent Eskridge, George Graef. Phenotypic trait extraction of soybean plants using deep convolutional neural networks with transfer learning[J]. Big Data and Information Analytics, 2021, 6: 26-40. doi: 10.3934/bdia.2021003









 DownLoad:
DownLoad: