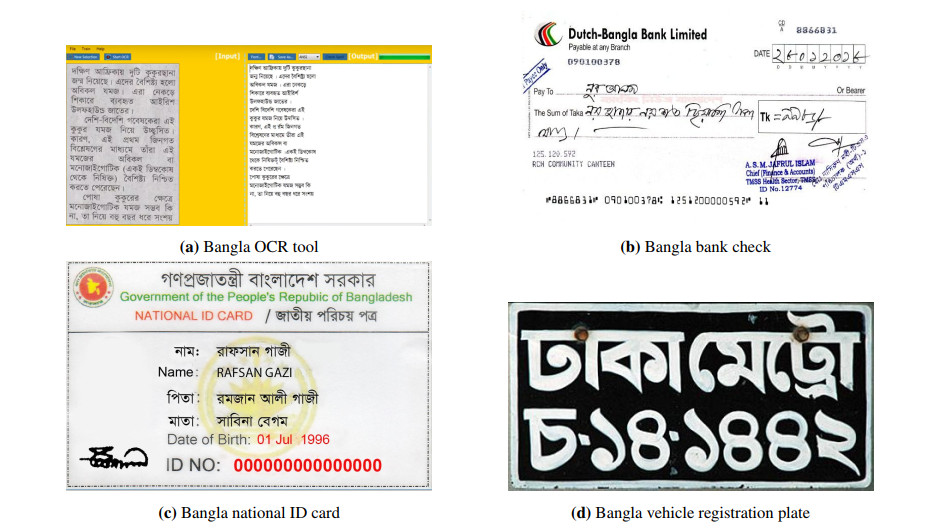
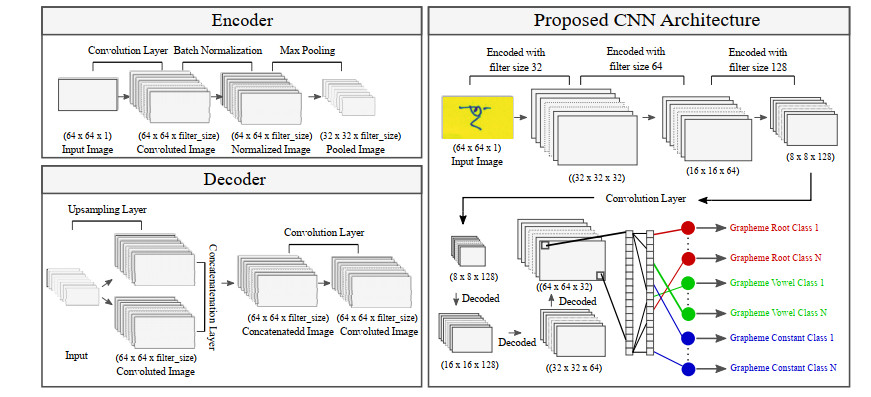
Handwritten grapheme recognition is popular research in computer vision and now widespread in the commercial industry due to its large number of applications in document analysis and recognition. Bengali grapheme classification is a complex task as it has 49 letters and 18 potential diacritics with almost 13,000 possible variations. Bengali is now the fifth most spoken native language and the seventh most spoken language by the total number of speakers in the world. Having set a bigger scope, this paper deals with the recognition of Bengali handwritten script letters. A class of deep Convolutional Neural Networks (CNNs) with encoder-decoder is used to classify handwritten letters. We use several serial non-linear layers as the encoders and a corresponding set of decoders that work as a pixel-wise classifier for letter recognition. The key idea is to encode images by convolution and decode them by deconvolution so that the max-pooling and up-sampling layers can correctly identify grapheme pixel-by-pixel. In this study, almost 200,840 grapheme images were analyzed, including root, vowels, and consonants. A large number of variations make additional complexity in recognition and may lead the model into over-fitting or under-fitting. We introduce regularization techniques to reduce the over-fitting in the fully connected layers. The results suggest that CNN with encoder-decoder can recognize complex grapheme characters with higher precision than traditional CNN. Experimental results show that the images' augmentation helps the model train better and improves its accuracy and loss.
Citation: Sayed Mohsin Reza, Md Al Masum Bhuiyan, Nishat Tasnim. A convolution neural network with encoder-decoder applied to the study of Bengali letters classification[J]. Big Data and Information Analytics, 2021, 6: 41-55. doi: 10.3934/bdia.2021004
Handwritten grapheme recognition is popular research in computer vision and now widespread in the commercial industry due to its large number of applications in document analysis and recognition. Bengali grapheme classification is a complex task as it has 49 letters and 18 potential diacritics with almost 13,000 possible variations. Bengali is now the fifth most spoken native language and the seventh most spoken language by the total number of speakers in the world. Having set a bigger scope, this paper deals with the recognition of Bengali handwritten script letters. A class of deep Convolutional Neural Networks (CNNs) with encoder-decoder is used to classify handwritten letters. We use several serial non-linear layers as the encoders and a corresponding set of decoders that work as a pixel-wise classifier for letter recognition. The key idea is to encode images by convolution and decode them by deconvolution so that the max-pooling and up-sampling layers can correctly identify grapheme pixel-by-pixel. In this study, almost 200,840 grapheme images were analyzed, including root, vowels, and consonants. A large number of variations make additional complexity in recognition and may lead the model into over-fitting or under-fitting. We introduce regularization techniques to reduce the over-fitting in the fully connected layers. The results suggest that CNN with encoder-decoder can recognize complex grapheme characters with higher precision than traditional CNN. Experimental results show that the images' augmentation helps the model train better and improves its accuracy and loss.

| [1] |
Drobac S, Lindén K, (2020) Optical character recognition with neural networks and post-correction with finite state methods. Int J Doc Anal Recognit 23:279–295. doi: 10.1007/s10032-020-00359-9

|
| [2] |
Rahman A F R, Fairhurst M C, (2003) Multiple classifier decision combination strategies for character recognition: A review. Doc Anal Recognit 5:166–194. doi: 10.1007/s10032-002-0090-8
|
| [3] | Paul M C, Sarkar S, Rahman M, Reza S M, Kaiser M S, (2016) Low cost and portable patient monitoring system for e-Health services in Bangladesh. 2016 IEEE Int Confer Computer Communication and Informatics :1–4. |
| [4] |
Matan O, Baird H S, Bromley J, et al. (1992) Reading handwritten digits: A zip code recognition system. Computer 25: 59–63. doi: 10.1109/2.144441
|
| [5] | Sazal M M R, Biswas S K, Amin M F, et al. (2014) Bangla handwritten character recognition using deep belief network. 2013 Int Confer Electron Inf Commun Technol: 1–5. |
| [6] | Reza S M, Rahman M, Parvez M H, Kaiser M S, Al Mamun S, (2015) Innovative approach in web application effort & cost estimation using functional measurement type. 2015 IEEE Int Confer Elect Eng. Infor Commun. Technology :1–7. |
| [7] | Karim M R, Chakravarthi B R, McCrae J P, et al. (2020) Classification benchmarks for under-resourced bengali language based on multichannel convolutional-lstm network. 2020 IEEE 7th Int Confer Data Sci Adv Anal: 390–399. |
| [8] | M. G. Kibria, Imtiaz A, (2012) Bengali optical character recognition using self organizing map. 2012 Int Confer Inf Electron Vision: 764–769. |
| [9] | Akhand M A H, Ahmed M, Rahman M, (2016) Convolutional neural network based handwritten bengali and bengali-english mixed numeral recognition. Int J Image Graph Signal Proc 8: 40. |
| [10] |
Plamondon R, Srihari S N, (2000) Online and off-line handwriting recognition: a comprehensive survey. IEEE Trans Pattern Anal Mach Intell 22:63–84. doi: 10.1109/34.824821
|
| [11] |
Wong P K, Chan C, (1998) Off-line handwritten chinese character recognition as a compound bayes decision problem. IEEE Trans Pattern Anal Mach Intell 20:1016–1023. doi: 10.1109/34.713366
|
| [12] | Rahman S, Sharma T, Reza S M, Rahman M M, Kaiser M S, (2016) PSO-NF based vertical handoff decision for ubiquitous heterogeneous wireless network (UHWN). Int Workshop Computational Intelligence :153–158. |
| [13] | Ashiquzzaman A, Tushar A K, (2017) Handwritten arabic numeral recognition using deep learning neural networks. 2017 IEEE Int Confer Imaging Vision Pattern Recognit: 1–4. |
| [14] |
Kim I J, Xie X H, (2015) Handwritten hangul recognition using deep convolutional neural networks. Int J Doc Anal Recognit 18: 1–13. doi: 10.1007/s10032-014-0229-4
|
| [15] | Cireşan D C, Meier U, Schmidhuber J, (2012) Transfer learning for latin and chinese characters with deep neural networks. 2012 Int Joint Confer Neural Networks: 1–6. |
| [16] |
Zhang J L, Guo M T, Fan J P, (2019) A novel cnn structure for fine-grained classification of chinese calligraphy styles. Int J Doc Anal Recognit 22: 177–188. doi: 10.1007/s10032-019-00324-1
|
| [17] | Reza S M, Rahman M M, Mamun S A, (2014) A new approach for road networks - a vehicle xml device collaboration with big data. 2014 IEEE Int Conf Elec Eng and Infor & Commun Tech : 1–5. |
| [18] | Reza S M, Rahman M M, Mahmud M M, Mamun S A, (2014) A New Approach of Big Data collaboration for Road Traffic Networks considering Path Loss Analysis in context of Bangladesh. JU Journal of Information Technology 3: 1–5 |
| [19] |
Tagougui N, Kherallah M, Alimi A M, (2013) Online arabic handwriting recognition: a survey. Int J Doc Anal Recognit 16: 209–226. doi: 10.1007/s10032-012-0186-8
|
| [20] | Reza S M, Badreddin O, Rahad K, (2020) Modelmine: a tool to facilitate mining models from open source repositories. 2020 ACM/IEEE Conf Model Driven Eng Lang Sys : 1–5. |
| [21] | Bluche T, Ney H, Kermorvant C, (2013) Feature extraction with convolutional neural networks for handwritten word recognition. 2013 12th Int Confer Doc Anal Recognit: 285–289. |
| [22] | Alekseevich Z A, Rybkin V, Vladimirovich A K, (2020) Differential classification using multiple neural networks. U. S. Patent No. 10,565,478. |
| [23] | Transue S, Reza S M, Halbower A C, Choi M, (2018) Behavioral analysis of turbulent exhale flows. 2018 IEEE EMBS Int Conf Biome & Health Infor: 42–45. |
| [24] |
Yang J Y, (2020) Gridmask based data augmentation for bengali handwritten grapheme classification. Proc 2020 2nd Int Confer Intell Med Image Proc: 98–102. doi: 10.1145/3399637.3399650
|
| [25] |
Shopon M, Mohammed N, Abedin M A, (2016) Bangla handwritten digit recognition using autoencoder and deep convolutional neural network. 2016 Int Workshop Comput Intell: 64–68. doi: 10.1109/IWCI.2016.7860340
|
| [26] | Akhand M A H, Ahmed M, Rahman M M H, (2016) Convolutional neural network training with artificial pattern for bangla handwritten numeral recognition. 2016 5th Int Confer Inf Electron Vision: 625–630. |
| [27] |
Rahad K, Badreddin O, Reza S M, (2021) The human in model-driven engineering loop: A case study on integrating handwritten code in model-driven engineering repositories. 2021 Journ Softw Pract Exper 51: 1308–1321. doi: 10.1002/spe.2957
|
| [28] |
Rabby A S A, Haque S, Islam M S, et al. (2018) Bornonet: Bangla handwritten characters recognition using convolutional neural network. Proc Comput Sci 143: 528–535. doi: 10.1016/j.procs.2018.10.426
|
| [29] | Alif M A R, Ahmed S, Hasan M A, (2017) Isolated bangla handwritten character recognition with convolutional neural network. 2017 20th Int Confer Comput Inf Technol: 1–6. |
| [30] |
Rahad K, Badreddin O, Reza S M, (2021) Characterization of Software Design and Collaborative Modeling in Open Source Projects. 9th Int Conf Model-Driven Eng and Soft Dev: 254–261. doi: 10.5220/0010266802540261
|
| [31] |
Mikołajczyk A, Grochowski M, (2018) Data augmentation for improving deep learning in image classification problem. 2018 Int Interdiscip PhD Workshop: 117–122. doi: 10.1109/IIPHDW.2018.8388338
|
| [32] | Reza S M, Badreddin O, Rahad K, Mahmud S U, (2021) Software code quality and source code metrics dataset. Mendeley Data DOI: 10.17632/77p6rzb73n. |
| [33] | Ye J C, Sung W K, (2019) Understanding geometry of encoder-decoder cnns. Int Confer Mach Learning: 7064–7073. |
| [34] | Albawi S, Mohammed T A, Al-Zawi S, (2017) Understanding of a convolutional neural network. 2017 Int Confer Eng Technol: 1–6. |
| [35] | Reza S M, Rahman M M, Parvez H, Badreddin O, Mamun S A, (2020) Performance Analysis of Machine Learning Approaches in Software Complexity Prediction. Int Conf Trends in Computa and Cogni Eng: 27–39. |
| [36] | Nwankpa C, Ijomah W, Gachagan A, et al. (2018) Activation functions: Comparison of trends in practice and research for deep learning. arXiv: 1811.03378 |
| [37] |
Qiumei Z, Dan T, Fenghua W, (2019) Improved convolutional neural network based on fast exponentially linear unit activation function. IEEE Access 7: 151359–151367. doi: 10.1109/ACCESS.2019.2948112
|
| [38] | Singh P, Varshney M, Namboodiri V, (2020) Cooperative initialization based deep neural network training. IEEE Winter Confer Appl Comput Vision: 1141–1150. |
| [39] | Bjorck N, Gomes C P, Selman B, Weinberger K Q, (2018) Understanding batch normalization. Adv Neural Inf Proc Syst: 7694–7705. |
| [40] | Ioffe S, (2017) Batch renormalization: Towards reducing minibatch dependence in batch-normalized models. Adv Neural Inf Proc Syst: 1945–1953. |
| [41] | Helmbold D P, Long P M, (2017) Surprising properties of dropout in deep networks. J Mach Learning Res 18: 7284–7311. |
| [42] | Kubo Y, Tucker G, Wiesler S, (2016) Compacting neural network classifiers via dropout training. arXiv: 1611.06148 |
| [43] |
Arora S, Bhatia M P S, (2018) Handwriting recognition using deep learning in keras. 2018 Int Confer Adv Comput Commun Control Networking: 142–145. doi: 10.1109/ICACCCN.2018.8748540
|
| [44] | Ma H, Mao F, Taylor G W, (2016) Theano-mpi: a theano-based distributed training framework. Eur Confer Parallel Proc : 800–813. |
| [45] | Rusiecki A, . Trimmed categorical cross-entropy for deep learning with label noise. Electron Lett, 55: 319–320. |
| [46] | Tang D Y, Wei F R, Qin B, et al. (2014) Coooolll: A deep learning system for twitter sentiment classification. Proc 8th Inte Workshop Semantic Eval: 208–212. |
| [47] | Singh A, Principe J C, (2010) A loss function for classification based on a robust similarity metric. 2010 Int Joint Confer Neural Networks: 1–6. |
| [48] | Cheng D, Gong Y H, Zhou S P, et al. (2016) Person re-identification by multi-channel parts-based cnn with improved triplet loss function. Proc IEEE Confer Computer Vision Pattern Recognit: 1335–1344. |


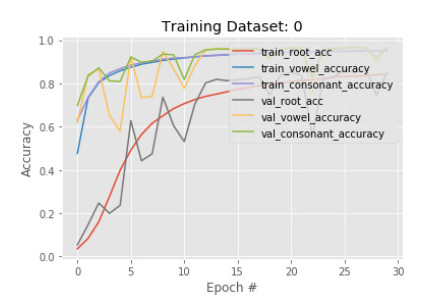
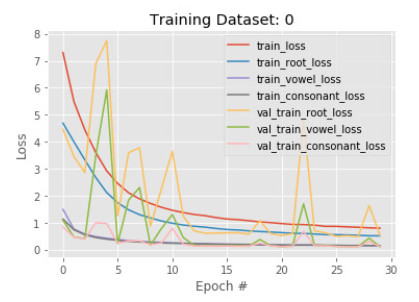
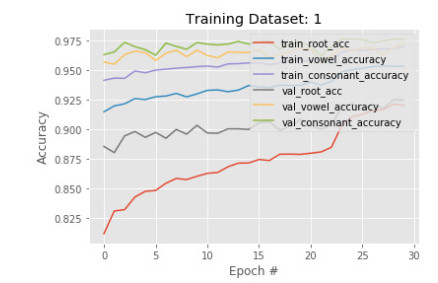
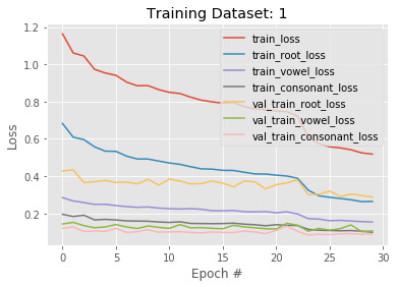
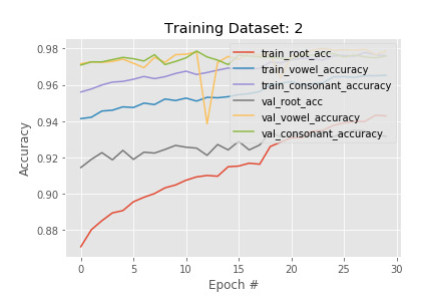
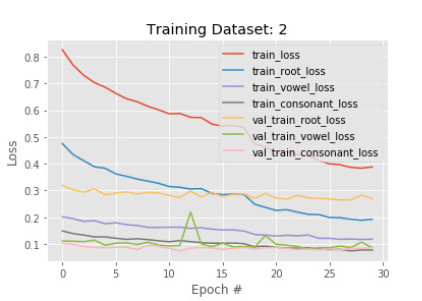
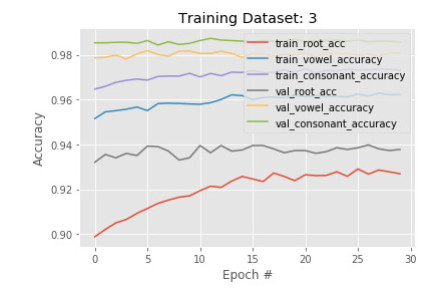
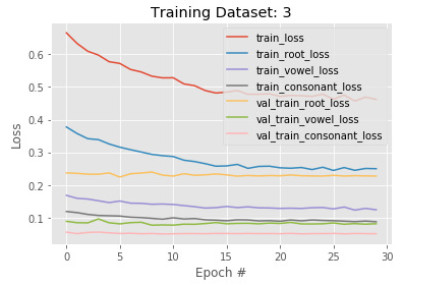
Figures(14) / Tables(2)

Sayed Mohsin Reza, Md Al Masum Bhuiyan, Nishat Tasnim. A convolution neural network with encoder-decoder applied to the study of Bengali letters classification[J]. Big Data and Information Analytics, 2021, 6: 41-55. doi: 10.3934/bdia.2021004









 DownLoad:
DownLoad: