Citation: Zoha Deldar, Carlos Gevers-Montoro, Ali Khatibi, Ladan Ghazi-Saidi. The interaction between language and working memory: a systematic review of fMRI studies in the past two decades[J]. AIMS Neuroscience, 2021, 8(1): 1-32. doi: 10.3934/Neuroscience.2021001

| [1] | Aitchison J (1999) Linguistics England, UK: The McGraw-Hill Companies, Inc., 50-150. |
| [2] | Fromkin V, Rodman R, Hyams NM (2003) An introduction to language Boston: Thomson, Wadsworth, 69-329. |
| [3] | Parker F, Riley KL (2005) Linguistics for non-linguists: a primer with exercises Boston, Mass: Allyn and Bacon, 12-137. |
| [4] | Finch G (2005) Key concepts in language and linguistics: Palgrave Macmillan. 31-40. |
| [5] | Field J (2003) Psycholinguistics: A resource book for students: Psychology Press London: Routledge. |
| [6] | Fromkin V, Rodman R, Hyams N (2018) An introduction to language Wadsworth: Cengage Learning, 4-270. |
| [7] |
Ghazi Saidi L, Perlbarg V, Marrelec G, et al. (2013) Functional connectivity changes in second language vocabulary learning. Brain Lang 124: 56-65. doi: 10.1016/j.bandl.2012.11.008

|
| [8] |
Ghazi-Saidi L, Ansaldo AI (2017) Second Language Word Learning through Repetition and Imitation: Functional Networks as a Function of Learning Phase and Language Distance. Front Hum Neurosci 11: 463. doi: 10.3389/fnhum.2017.00463
|
| [9] | Parker F, Riley KL, Riley KL (2005) Grammar for grammarians: prescriptive, descriptive, generative, contextual Chicago: Parlay Press, 12-137. |
| [10] | Fromkin V, Rodman R (1988) An introduction to language New York: Holt, Rinehart, and Winston, 69-329. |
| [11] | Yule G (1996) The study of language Cambridge England: Cambridge University Press, 25-156. |
| [12] | Falk JS (1978) ERIC Clearinghouse on Languages and Linguistics. Language and linguistics: bases for a curriculum Arlington Va: Center for Applied Linguistics, 5-12. |
| [13] |
Hickok G, Poeppel D (2007) The cortical organization of speech processing. Nat Rev Neurosci 8: 393-402. doi: 10.1038/nrn2113
|
| [14] |
Poeppel D, Idsardi WJ, Van Wassenhove V (2008) Speech perception at the interface of neurobiology and linguistics. Philos Trans R Soc Lond B Biol Sci 363: 1071-1086. doi: 10.1098/rstb.2007.2160
|
| [15] |
Price CJ (2010) The anatomy of language: a review of 100 fMRI studies published in 2009. Ann N Y Acad Sci 1191: 62-88. doi: 10.1111/j.1749-6632.2010.05444.x
|
| [16] |
Buchweitz A, Mason RA, Tomitch LM, et al. (2009) Brain activation for reading and listening comprehension: An fMRI study of modality effects and individual differences in language comprehension. Psychol Neurosci 2: 111-123. doi: 10.3922/j.psns.2009.2.003
|
| [17] |
Keller TA, Carpenter PA, Just MA (2001) The neural bases of sentence comprehension: a fMRI examination of syntactic and lexical processing. Cereb Cortex 11: 223-237. doi: 10.1093/cercor/11.3.223
|
| [18] | Obler LK, Gjerlow K (1999) Language and the brain Cambridge, UK; New York: Cambridge University Press, 141-156. |
| [19] | Banich MT, Mack MA (2003) Mind, brain, and language: multidisciplinary perspectives Mahwah, NJ: L Erlbaum Associates, 23-61. |
| [20] |
Tan LH, Laird AR, Li K, et al. (2005) Neuroanatomical correlates of phonological processing of Chinese characters and alphabetic words: a meta-analysis. Hum Brain Mapp 25: 83-91. doi: 10.1002/hbm.20134
|
| [21] |
Price CJ (2000) The anatomy of language: contributions from functional neuroimaging. J Anat 197: 335-359. doi: 10.1046/j.1469-7580.2000.19730335.x
|
| [22] |
Hill VB, Cankurtaran CZ, Liu BP, et al. (2019) A Practical Review of Functional MRI Anatomy of the Language and Motor Systems. Am J Neuroradiol 40: 1084-1090. doi: 10.3174/ajnr.A6089
|
| [23] |
Gordon EM, Laumann TO, Marek S, et al. (2020) Default-mode network streams for coupling to language and control systems. Proc Natl Acad Sci U S A 117: 17308-17319. doi: 10.1073/pnas.2005238117
|
| [24] | Liberman P (2000) Human Languages and our brain: The subcortical bases of speech, syntax and thought Cambridge: Harvard University Press. |
| [25] |
Lopes TM, Yasuda CL, Campos BM, et al. (2016) Effects of task complexity on activation of language areas in a semantic decision fMRI protocol. Neuropsychologia 81: 140-148. doi: 10.1016/j.neuropsychologia.2015.12.020
|
| [26] |
Krings T, Topper R, Foltys H, et al. (2000) Cortical activation patterns during complex motor tasks in piano players and control subjects. A functional magnetic resonance imaging study. Neurosci Lett 278: 189-193. doi: 10.1016/S0304-3940(99)00930-1
|
| [27] | Carey JR, Bhatt E, Nagpal A (2005) Neuroplasticity promoted by task complexity. Exerc Sport Sci Rev 33: 24-31. |
| [28] |
van de Ven V, Esposito F, Christoffels IK (2009) Neural network of speech monitoring overlaps with overt speech production and comprehension networks: a sequential spatial and temporal ICA study. Neuroimage 47: 1982-1991. doi: 10.1016/j.neuroimage.2009.05.057
|
| [29] |
Bitan T, Booth JR, Choy J, et al. (2005) Shifts of effective connectivity within a language network during rhyming and spelling. J Neurosci 25: 5397-5403. doi: 10.1523/JNEUROSCI.0864-05.2005
|
| [30] |
Just MA, Newman SD, Keller TA, et al. (2004) Imagery in sentence comprehension: an fMRI study. Neuroimage 21: 112-124. doi: 10.1016/j.neuroimage.2003.08.042
|
| [31] |
Warren JE, Crinion JT, Lambon Ralph MA, et al. (2009) Anterior temporal lobe connectivity correlates with functional outcome after aphasic stroke. Brain 132: 3428-3442. doi: 10.1093/brain/awp270
|
| [32] |
Leff AP, Schofield TM, Stephan KE, et al. (2008) The cortical dynamics of intelligible speech. J Neurosci 28: 13209-13215. doi: 10.1523/JNEUROSCI.2903-08.2008
|
| [33] |
Vitali P, Abutalebi J, Tettamanti M, et al. (2007) Training-induced brain remapping in chronic aphasia: a pilot study. Neurorehabil Neural Repair 21: 152-160. doi: 10.1177/1545968306294735
|
| [34] |
Meinzer M, Flaisch T, Obleser J, et al. (2006) Brain regions essential for improved lexical access in an aged aphasic patient: a case report. BMC Neurol 6: 28. doi: 10.1186/1471-2377-6-28
|
| [35] |
Hillis AE, Kleinman JT, Newhart M, et al. (2006) Restoring cerebral blood flow reveals neural regions critical for naming. J Neurosci 26: 8069-8073. doi: 10.1523/JNEUROSCI.2088-06.2006
|
| [36] |
Marsh EB, Hillis AE (2005) Cognitive and neural mechanisms underlying reading and naming: evidence from letter-by-letter reading and optic aphasia. Neurocase 11: 325-337. doi: 10.1080/13554790591006320
|
| [37] |
Kan IP, Thompson-Schill SL (2004) Effect of name agreement on prefrontal activity during overt and covert picture naming. Cogn Affect Behav Neurosci 4: 43-57. doi: 10.3758/CABN.4.1.43
|
| [38] |
Leger A, Demonet JF, Ruff S, et al. (2002) Neural substrates of spoken language rehabilitation in an aphasic patient: an fMRI study. Neuroimage 17: 174-183. doi: 10.1006/nimg.2002.1238
|
| [39] |
Gotts SJ, della Rocchetta AI, Cipolotti L (2002) Mechanisms underlying perseveration in aphasia: evidence from a single case study. Neuropsychologia 40: 1930-1947. doi: 10.1016/S0028-3932(02)00067-2
|
| [40] |
Arevalo A, Perani D, Cappa SF, et al. (2007) Action and object processing in aphasia: from nouns and verbs to the effect of manipulability. Brain Lang 100: 79-94. doi: 10.1016/j.bandl.2006.06.012
|
| [41] |
Duffau H (2008) The anatomo-functional connectivity of language revisited. New insights provided by electrostimulation and tractography. Neuropsychologia 46: 927-934. doi: 10.1016/j.neuropsychologia.2007.10.025
|
| [42] |
Baddeley A (2012) Working memory: theories, models, and controversies. Annu Rev Psychol 63: 1-29. doi: 10.1146/annurev-psych-120710-100422
|
| [43] |
Diamond A (2013) Executive functions. Annu Rev Psychol 64: 135-168. doi: 10.1146/annurev-psych-113011-143750
|
| [44] |
Baddeley AD, Hitch G (1974) Working memory. Psychology of learning and motivation Elsevier: Academic Press, 47-89. doi: 10.1016/S0079-7421(08)60452-1
|
| [45] |
D'Esposito M, Postle BR (2015) The cognitive neuroscience of working memory. Annu Rev Psychol 66: 115-142. doi: 10.1146/annurev-psych-010814-015031
|
| [46] |
De Fockert JW (2013) Beyond perceptual load and dilution: a review of the role of working memory in selective attention. Front Psychol 4: 287. doi: 10.3389/fpsyg.2013.00287
|
| [47] |
Fougnie D, Marois R (2009) Attentive Tracking Disrupts Feature Binding in Visual Working Memory. Vis Cogn 17: 48-66. doi: 10.1080/13506280802281337
|
| [48] | Dowd EW (2016) Memory-Based Attentional Guidance: A Window to the Relationship between Working Memory and Attention, Doctoral dissertation: Duke University. 6-23. |
| [49] | Pennington BF, Bennetto L, McAleer O, et al. (1996) Executive functions and working memory: Theoretical and measurement issues. |
| [50] | Zillmer E, Spiers M, Culbertson WC (2001) Principles of neuropsychology Belmont CA: Wadsworth Pub Co, 606. |
| [51] | Cowan N (1995) Attention and memory: an integrated framework New York: Oxford University Press. |
| [52] |
Ericsson KA, Kintsch W (1995) Long-term working memory. Psychol Rev 102: 211-245. doi: 10.1037/0033-295X.102.2.211
|
| [53] |
Baddeley A (2003) Working memory: looking back and looking forward. Nat Rev Neurosci 4: 829-839. doi: 10.1038/nrn1201
|
| [54] |
Postle BR (2006) Working memory as an emergent property of the mind and brain. Neuroscience 139: 23-38. doi: 10.1016/j.neuroscience.2005.06.005
|
| [55] |
Woodman GF, Vogel EK (2005) Fractionating working memory: consolidation and maintenance are independent processes. Psychol Sci 16: 106-113. doi: 10.1111/j.0956-7976.2005.00790.x
|
| [56] | Fuster JM (1997) The prefrontal cortex: anatomy, physiology, and neuropsychology of the frontal lobe Philadelphia: Lippincott-Raven. |
| [57] |
Cowan N (2017) The many faces of working memory and short-term storage. Psychon Bull Rev 24: 1158-1170. doi: 10.3758/s13423-016-1191-6
|
| [58] |
Miyake A, Shah P (1999) Models of working memory: mechanisms of active maintenance and executive control New York: Cambridge University Press. doi: 10.1017/CBO9781139174909
|
| [59] |
Awh E, Vogel EK, Oh SH (2006) Interactions between attention and working memory. Neuroscience 139: 201-208. doi: 10.1016/j.neuroscience.2005.08.023
|
| [60] |
Engle RW, Tuholski SW, Laughlin JE, et al. (1999) Working memory, short-term memory, and general fluid intelligence: a latent-variable approach. J Exp Psychol Gen 128: 309-331. doi: 10.1037/0096-3445.128.3.309
|
| [61] |
Heitz RP, Engle RW (2007) Focusing the spotlight: individual differences in visual attention control. J Exp Psychol Gen 136: 217-240. doi: 10.1037/0096-3445.136.2.217
|
| [62] | Baddeley AD (2000) Short-term and working memory. The Oxford handbook of memory Oxford University Press, 77-92. |
| [63] |
Wager TD, Smith EE (2003) Neuroimaging studies of working memory: a meta-analysis. Cogn Affect Behav Neurosci 3: 255-274. doi: 10.3758/CABN.3.4.255
|
| [64] |
Jonides J, Lacey SC, Nee DE (2005) Processes of working memory in mind and brain. Curr Dir Psychol Sci 14: 2-5. doi: 10.1111/j.0963-7214.2005.00323.x
|
| [65] |
Pessoa L, Gutierrez E, Bandettini P, et al. (2002) Neural correlates of visual working memory: fMRI amplitude predicts task performance. Neuron 35: 975-987. doi: 10.1016/S0896-6273(02)00817-6
|
| [66] |
Palva JM, Monto S, Kulashekhar S, et al. (2010) Neuronal synchrony reveals working memory networks and predicts individual memory capacity. Proc Natl Acad Sci U S A 107: 7580-7585. doi: 10.1073/pnas.0913113107
|
| [67] |
Murphy AC, Bertolero MA, Papadopoulos L, et al. (2020) Multimodal network dynamics underpinning working memory. Nat Commun 11: 3035. doi: 10.1038/s41467-020-15541-0
|
| [68] |
Chai WJ, Abd Hamid AI, Abdullah JM (2018) Working Memory From the Psychological and Neurosciences Perspectives: A Review. Front Psychol 9: 401. doi: 10.3389/fpsyg.2018.00401
|
| [69] |
Kim C, Kroger JK, Calhoun VD, et al. (2015) The role of the frontopolar cortex in manipulation of integrated information in working memory. Neurosci Lett 595: 25-29. doi: 10.1016/j.neulet.2015.03.044
|
| [70] |
Jimura K, Chushak MS, Westbrook A, et al. (2018) Intertemporal Decision-Making Involves Prefrontal Control Mechanisms Associated with Working Memory. Cereb Cortex 28: 1105-1116. doi: 10.1093/cercor/bhx015
|
| [71] |
Osaka M, Osaka N, Kondo H, et al. (2003) The neural basis of individual differences in working memory capacity: an fMRI study. Neuroimage 18: 789-797. doi: 10.1016/S1053-8119(02)00032-0
|
| [72] |
Moore AB, Li Z, Tyner CE, et al. (2013) Bilateral basal ganglia activity in verbal working memory. Brain Lang 125: 316-323. doi: 10.1016/j.bandl.2012.05.003
|
| [73] |
Vartanian O, Jobidon ME, Bouak F, et al. (2013) Working memory training is associated with lower prefrontal cortex activation in a divergent thinking task. Neuroscience 236: 186-194. doi: 10.1016/j.neuroscience.2012.12.060
|
| [74] |
Rodriguez Merzagora AC, Izzetoglu M, Onaral B, et al. (2014) Verbal working memory impairments following traumatic brain injury: an fNIRS investigation. Brain Imaging Behav 8: 446-459. doi: 10.1007/s11682-013-9258-8
|
| [75] |
Owen AM, McMillan KM, Laird AR, et al. (2005) N-back working memory paradigm: a meta-analysis of normative functional neuroimaging studies. Hum Brain Mapp 25: 46-59. doi: 10.1002/hbm.20131
|
| [76] |
Andersen RA, Cui H (2009) Intention, action planning, and decision making in parietal-frontal circuits. Neuron 63: 568-583. doi: 10.1016/j.neuron.2009.08.028
|
| [77] |
Kiyonaga A, Egner T (2013) Working memory as internal attention: toward an integrative account of internal and external selection processes. Psychon Bull Rev 20: 228-242. doi: 10.3758/s13423-012-0359-y
|
| [78] |
Sreenivasan KK, Curtis CE, D'Esposito M (2014) Revisiting the role of persistent neural activity during working memory. Trends Cogn Sci 18: 82-89. doi: 10.1016/j.tics.2013.12.001
|
| [79] |
Andrews-Hanna JR (2012) The brain's default network and its adaptive role in internal mentation. Neuroscientist 18: 251-270. doi: 10.1177/1073858411403316
|
| [80] |
Spreng RN, Stevens WD, Chamberlain JP, et al. (2010) Default network activity, coupled with the frontoparietal control network, supports goal-directed cognition. Neuroimage 53: 303-317. doi: 10.1016/j.neuroimage.2010.06.016
|
| [81] |
Cowan N (2001) The magical number 4 in short-term memory: A reconsideration of mental storage capacity. Behav Brain Sci 24: 87-114. doi: 10.1017/S0140525X01003922
|
| [82] |
Luck SJ, Vogel EK (1997) The capacity of visual working memory for features and conjunctions. Nature 390: 279-281. doi: 10.1038/36846
|
| [83] |
Cowan N (1999) An Embedded Process Model of Working Memory. Models of Working Memory: Mechanisms of Active Maintenance and Executive Control Cambridge: Cambridge University Press, 62-101. doi: 10.1017/CBO9781139174909.006
|
| [84] |
Van den Berg R, Shin H, Chou WC, et al. (2012) Variability in encoding precision accounts for visual short-term memory limitations. Proc Natl Acad Sci 109: 8780-8785. doi: 10.1073/pnas.1117465109
|
| [85] |
Fougnie D, Suchow JW, Alvarez GA (2012) Variability in the quality of visual working memory. Nat Commun 3: 1229. doi: 10.1038/ncomms2237
|
| [86] |
Klencklen G, Lavenex PB, Brandner C, et al. (2017) Working memory decline in normal aging: Is it really worse in space than in color? Learn Motiv 57: 48-60. doi: 10.1016/j.lmot.2017.01.007
|
| [87] |
Unsworth N, Fukuda K, Awh E, et al. (2014) Working memory and fluid intelligence: capacity, attention control, and secondary memory retrieval. Cogn Psychol 71: 1-26. doi: 10.1016/j.cogpsych.2014.01.003
|
| [88] | Smith EE, Geva A (2000) Verbal working memory and its connections to language processing. In Foundations of Neuropsychology, Language and the Brain Academic Press, 123-141. |
| [89] |
Fan LZ, Li H, Zhuo JJ, et al. (2016) The Human Brainnetome Atlas: A New Brain Atlas Based on Connectional Architecture. Cereb Cortex 26: 3508-3526. doi: 10.1093/cercor/bhw157
|
| [90] |
Bordier C, Hupe JM, Dojat M (2015) Quantitative evaluation of fMRI retinotopic maps, from V1 to V4, for cognitive experiments. Front Hum Neurosci 9: 277. doi: 10.3389/fnhum.2015.00277
|
| [91] |
Fedorenko E, Varley R (2016) Language and thought are not the same thing: evidence from neuroimaging and neurological patients. Ann N Y Acad Sci 1369: 132-153. doi: 10.1111/nyas.13046
|
| [92] |
Emch M, von Bastian CC, Koch K (2019) Neural Correlates of Verbal Working Memory: An fMRI Meta-Analysis. Front Hum Neurosci 13: 180. doi: 10.3389/fnhum.2019.00180
|
| [93] |
Mahdavi A, Azar R, Shoar MH, et al. (2015) Functional MRI in clinical practice: Assessment of language and motor for pre-surgical planning. Neuroradiol J 28: 468-473. doi: 10.1177/1971400915609343
|
| [94] |
Siyanova-Chanturia A, Canal P, Heredia RR (2019) Event-Related Potentials in Monolingual and Bilingual Non-literal Language Processing. The Handbook of the Neuroscience of Multilingualism John Wiley & Sons Ltd, 508-529. doi: 10.1002/9781119387725.ch25
|
| [95] |
Rossi S, Telkemeyer S, Wartenburger I, et al. (2012) Shedding light on words and sentences: near-infrared spectroscopy in language research. Brain Lang 121: 152-163. doi: 10.1016/j.bandl.2011.03.008
|
| [96] | Crosson B (1992) Subcortical functions in language and memory New York: Guilford Press, 374. |
| [97] |
Buchweitz A, Keller TA, Meyler A, et al. (2012) Brain activation for language dual-tasking: listening to two people speak at the same time and a change in network timing. Hum Brain Mapp 33: 1868-1882. doi: 10.1002/hbm.21327
|
| [98] |
Fiebach CJ, Vos SH, Friederici AD (2004) Neural correlates of syntactic ambiguity in sentence comprehension for low and high span readers. J Cogn Neurosci 16: 1562-1575. doi: 10.1162/0898929042568479
|
| [99] |
Mason RA, Just MA (2007) Lexical ambiguity in sentence comprehension. Brain Res 1146: 115-127. doi: 10.1016/j.brainres.2007.02.076
|
| [100] |
Kane MJ, Conway ARA, Miura TK, et al. (2007) Working memory, attention control, and the N-back task: a question of construct validity. J Exp Psychol Learn Mem Cogn 33: 615-622. doi: 10.1037/0278-7393.33.3.615
|
| [101] |
Jaeggi SM, Buschkuehl M, Perrig WJ, et al. (2010) The concurrent validity of the N-back task as a working memory measure. Memory 18: 394-412. doi: 10.1080/09658211003702171
|
| [102] |
Rudner M, Karlsson T, Gunnarsson J, et al. (2013) Levels of processing and language modality specificity in working memory. Neuropsychologia 51: 656-666. doi: 10.1016/j.neuropsychologia.2012.12.011
|
| [103] |
Rudner M, Ronnberg J, Hugdahl K (2005) Reversing spoken items-mind twisting not tongue twisting. Brain Lang 92: 78-90. doi: 10.1016/j.bandl.2004.05.010
|
| [104] |
Newman SD, Malaia E, Seo R, et al. (2013) The effect of individual differences in working memory capacity on sentence comprehension: an FMRI study. Brain Topogr 26: 458-467. doi: 10.1007/s10548-012-0264-8
|
| [105] |
D'Esposito M, Detre JA, Alsop DC, et al. (1995) The neural basis of the central executive system of working memory. Nature 378: 279-281. doi: 10.1038/378279a0
|
| [106] |
Jaeggi SM, Seewer R, Nirkko AC, et al. (2003) Does excessive memory load attenuate activation in the prefrontal cortex? Load-dependent processing in single and dual tasks: functional magnetic resonance imaging study. Neuroimage 19: 210-225. doi: 10.1016/S1053-8119(03)00098-3
|
| [107] |
Taylor JG, Taylor NR (2000) Analysis of recurrent cortico-basal ganglia-thalamic loops for working memory. Biol Cybern 82: 415-432. doi: 10.1007/s004220050595
|
| [108] | Nir-Cohen G, Kessler Y, Egner T (2020) Neural substrates of working memory updating. BioRxiv 853630. |
| [109] |
McNab F, Klingberg T (2008) Prefrontal cortex and basal ganglia control access to working memory. Nat Neurosci 11: 103-107. doi: 10.1038/nn2024
|
| [110] |
Wallentin M, Roepstorff A, Glover R, et al. (2006) Parallel memory systems for talking about location and age in precuneus, caudate and Broca's region. Neuroimage 32: 1850-1864. doi: 10.1016/j.neuroimage.2006.05.002
|
| [111] | Levelt WJ, Roelofs A, Meyer AS (1999) A theory of lexical access in speech production. Behav Brain Sci 22: 1-38. |
| [112] |
Marvel CL, Desmond JE (2012) From storage to manipulation: How the neural correlates of verbal working memory reflect varying demands on inner speech. Brain Lang 120: 42-51. doi: 10.1016/j.bandl.2011.08.005
|
| [113] |
McGettigan C, Warren JE, Eisner F, et al. (2011) Neural correlates of sublexical processing in phonological working memory. J Cogn Neurosci 23: 961-977. doi: 10.1162/jocn.2010.21491
|
| [114] |
Powell JL, Kemp GJ, Garcia-Finana M (2012) Association between language and spatial laterality and cognitive ability: an fMRI study. Neuroimage 59: 1818-1829. doi: 10.1016/j.neuroimage.2011.08.040
|
| [115] |
Sahin NT, Pinker S, Halgren E (2006) Abstract grammatical processing of nouns and verbs in Broca's area: evidence from fMRI. Cortex 42: 540-562. doi: 10.1016/S0010-9452(08)70394-0
|
| [116] | Meyer L, Obleser J, Kiebel SJ, et al. (2012) Spatiotemporal dynamics of argument retrieval and reordering: an FMRI and EEG study on sentence processing. Front Psychol 3: 523. |
| [117] |
Bonhage CE, Fiebach CJ, Bahlmann J, et al. (2014) Brain signature of working memory for sentence structure: enriched encoding and facilitated maintenance. J Cogn Neurosci 26: 1654-1671. doi: 10.1162/jocn_a_00566
|
| [118] |
Bassett DS, Sporns O (2017) Network neuroscience. Nat Neurosci 20: 353-364. doi: 10.1038/nn.4502
|
| [119] |
Meier J, Tewarie P, Hillebrand A, et al. (2016) A Mapping Between Structural and Functional Brain Networks. Brain Connect 6: 298-311. doi: 10.1089/brain.2015.0408
|
| [120] |
Yao Z, Hu B, Xie Y, et al. (2015) A review of structural and functional brain networks: small world and atlas. Brain Inform 2: 45-52. doi: 10.1007/s40708-015-0009-z
|
| [121] |
Makuuchi M, Friederici AD (2013) Hierarchical functional connectivity between the core language system and the working memory system. Cortex 49: 2416-2423. doi: 10.1016/j.cortex.2013.01.007
|
| [122] |
Dehaene S, Cohen L (2011) The unique role of the visual word form area in reading. Trends Cogn Sci 15: 254-262. doi: 10.1016/j.tics.2011.04.003
|
| [123] | Caplan D, Waters GS (1999) Verbal working memory and sentence comprehension. Behav Brain Sci 22: 77-94. |
| [124] |
Perrachione TK, Ghosh SS, Ostrovskaya I, et al. (2017) Phonological Working Memory for Words and Nonwords in Cerebral Cortex. J Speech Lang Hear Res 60: 1959-1979. doi: 10.1044/2017_JSLHR-L-15-0446
|
| [125] |
Newman SD, Just MA, Carpenter PA (2002) The synchronization of the human cortical working memory network. Neuroimage 15: 810-822. doi: 10.1006/nimg.2001.0997
|
| [126] |
Nyberg L, Sandblom J, Jones S, et al. (2003) Neural correlates of training-related memory improvement in adulthood and aging. Proc Natl Acad Sci U S A 100: 13728-13733. doi: 10.1073/pnas.1735487100
|
| [127] |
Cooke A, Grossman M, DeVita C, et al. (2006) Large-scale neural network for sentence processing. Brain Lang 96: 14-36. doi: 10.1016/j.bandl.2005.07.072
|
| [128] |
Tomasi D, Volkow ND (2020) Network connectivity predicts language processing in healthy adults. Hum Brain Mapp 41: 3696-3708. doi: 10.1002/hbm.25042
|
| [129] |
Brownsett SL, Wise RJ (2010) The contribution of the parietal lobes to speaking and writing. Cereb Cortex 20: 517-523. doi: 10.1093/cercor/bhp120
|
| [130] |
Segal E, Petrides M (2013) Functional activation during reading in relation to the sulci of the angular gyrus region. Eur J Neurosci 38: 2793-2801. doi: 10.1111/ejn.12277
|
| [131] |
Tomasi D, Volkow ND (2012) Resting functional connectivity of language networks: characterization and reproducibility. Mol Psychiatry 17: 841-854. doi: 10.1038/mp.2011.177
|
| [132] |
Cunningham SI, Tomasi D, Volkow ND (2017) Structural and functional connectivity of the precuneus and thalamus to the default mode network. Hum Brain Mapp 38: 938-956. doi: 10.1002/hbm.23429
|
| [133] |
Raichle ME, Snyder AZ (2007) A default mode of brain function: a brief history of an evolving idea. Neuroimage 37: 1083-1090. doi: 10.1016/j.neuroimage.2007.02.041
|
| [134] |
Mineroff Z, Blank IA, Mahowald K, et al. (2018) A robust dissociation among the language, multiple demand, and default mode networks: Evidence from inter-region correlations in effect size. Neuropsychologia 119: 501-511. doi: 10.1016/j.neuropsychologia.2018.09.011
|
| [135] |
Ellis Weismer S, Plante E, Jones M, et al. (2005) A functional magnetic resonance imaging investigation of verbal working memory in adolescents with specific language impairment. J Speech Lang Hear Res 48: 405-425. doi: 10.1044/1092-4388(2005/028)
|
| [136] |
Beneventi H, Tonnessen FE, Ersland L (2009) Dyslexic children show short-term memory deficits in phonological storage and serial rehearsal: an fMRI study. Int J Neurosci 119: 2017-2043. doi: 10.1080/00207450903139671
|
| [137] |
Buchsbaum B, Pickell B, Love T, et al. (2005) Neural substrates for verbal working memory in deaf signers: fMRI study and lesion case report. Brain Lang 95: 265-272. doi: 10.1016/j.bandl.2005.01.009
|
| [138] |
Whitwell JL, Jones DT, Duffy JR, et al. (2015) Working memory and language network dysfunctions in logopenic aphasia: a task-free fMRI comparison with Alzheimer's dementia. Neurobiol Aging 36: 1245-1252. doi: 10.1016/j.neurobiolaging.2014.12.013
|
| [139] |
Price CJ (2012) A review and synthesis of the first 20 years of PET and fMRI studies of heard speech, spoken language and reading. Neuroimage 62: 816-847. doi: 10.1016/j.neuroimage.2012.04.062
|
| [140] | Heim S (2005) The structure and dynamics of normal language processing: insights from neuroimaging. Acta Neurobiol Exp (Wars) 65: 95-116. |
| [141] |
Dick AS, Bernal B, Tremblay P (2014) The language connectome: new pathways, new concepts. Neuroscientist 20: 453-467. doi: 10.1177/1073858413513502
|
 neurosci-08-01-001-s001.pdf neurosci-08-01-001-s001.pdf |
 |
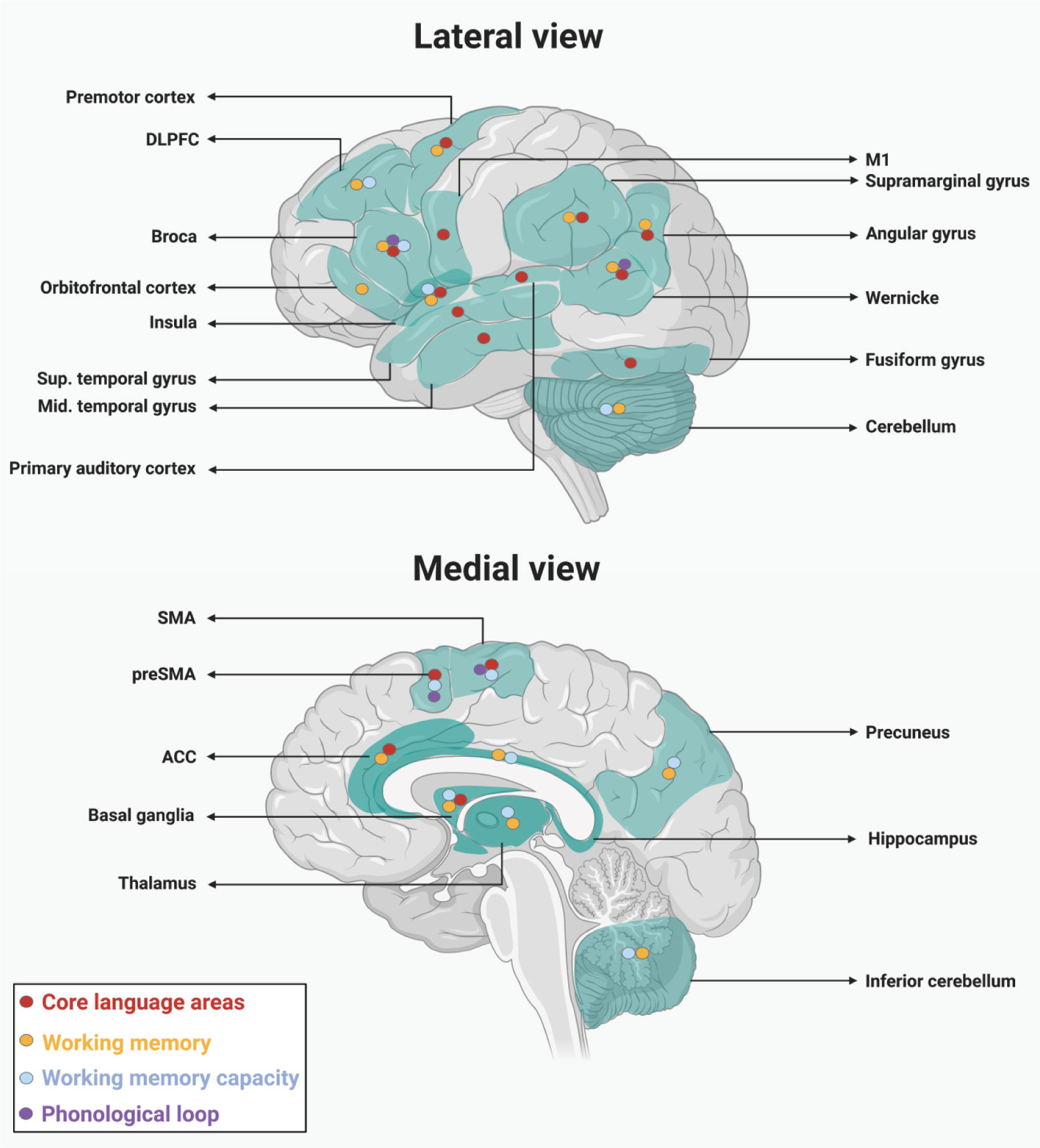
Figures(1) / Tables(1)

Zoha Deldar, Carlos Gevers-Montoro, Ali Khatibi, Ladan Ghazi-Saidi. The interaction between language and working memory: a systematic review of fMRI studies in the past two decades[J]. AIMS Neuroscience, 2021, 8(1): 1-32. doi: 10.3934/Neuroscience.2021001







 DownLoad:
DownLoad: