Citation: Yong X. Chen, Brian Cain, Pranav Soman. Gelatin methacrylate-alginate hydrogel with tunable viscoelastic properties[J]. AIMS Materials Science, 2017, 4(2): 363-369. doi: 10.3934/matersci.2017.2.363

| [1] |
Tayalia P, Mendonca CR, Baldacchini T, et al. (2008) 3D Cell-Migration Studies using Two-Photon Engineered Polymer Scaffolds. Adv Mater 20: 4494–4498. doi: 10.1002/adma.200801319

|
| [2] |
Annabi N, Tamayol A, Uquillas JA, et al. (2014) 25th anniversary article: rational design and applications of hydrogels in regenerative medicine. Adv Mater 26: 85–124. doi: 10.1002/adma.201303233
|
| [3] |
Lee KY, Mooney DJ (2001) Hydrogels for tissue engineering. Chem Rev 101: 1869–1880. doi: 10.1021/cr000108x
|
| [4] |
Tibbitt MW, Anseth KS (2009) Hydrogels as extracellular matrix mimics for 3D cell culture. Biotechnol Bioeng 103: 655–663. doi: 10.1002/bit.22361
|
| [5] |
Storm C, Pastore JJ, MacKintosh FC, et al. (2005) Nonlinear elasticity in biological gels. Nature 435: 191–194. doi: 10.1038/nature03521
|
| [6] |
Wen Q, Janmey PA (2013) Effects of nonlinearity on cell-ECM interactions. Exp Cell Res 319: 2481–2489. doi: 10.1016/j.yexcr.2013.05.017
|
| [7] |
Burdick JA, Murphy WL (2012) Moving from static to dynamic complexity in hydrogel design. Nat Commun 3: 1269. doi: 10.1038/ncomms2271
|
| [8] |
McKinnon DD, Domaille DW, Cha JN, et al. (2014) Biophysically defined and cytocompatible covalently adaptable networks as viscoelastic 3D cell culture systems. Adv Mater 26: 865–872. doi: 10.1002/adma.201303680
|
| [9] |
Hong X, Stegemann JP, Deng CX (2016) Microscale characterization of the viscoelastic properties of hydrogel biomaterials using dual-mode ultrasound elastography. Biomaterials 88: 12–24. doi: 10.1016/j.biomaterials.2016.02.019
|
| [10] |
Wang H, Heilshorn SC (2015) Adaptable hydrogel networks with reversible linkages for tissue engineering. Adv Mater 27: 3717–3736. doi: 10.1002/adma.201501558
|
| [11] | Sun TL, Kurokawa T, Kuroda S, et al. (2013) Physical hydrogels composed of polyampholytes demonstrate high toughness and viscoelasticity. Nat Mater 12: 932–937. |
| [12] |
Rodell CB, MacArthur JW, Dorsey SM, et al. (2015) Shear-Thinning Supramolecular Hydrogels with Secondary Autonomous Covalent Crosslinking to Modulate Viscoelastic Properties In Vivo. Adv Funct Mater 25: 636–644. doi: 10.1002/adfm.201403550
|
| [13] | Chaudhuri O, Gu L, Klumpers D, et al. (2016) Hydrogels with tunable stress relaxation regulate stem cell fate and activity. Nat Mater 15: 326–334. |
| [14] |
Gillette BM, Jensen JA, Wang M, et al. (2010) Dynamic Hydrogels: Switching of 3D Microenvironments Using Two-Component Naturally Derived Extracellular Matrices. Adv Mater 22: 686–691. doi: 10.1002/adma.200902265
|
| [15] |
Park H, Kang SW, Kim BS, et al. (2009) Shear-reversibly crosslinked alginate hydrogels for tissue engineering. Macromol Biosci 9: 895–901. doi: 10.1002/mabi.200800376
|
| [16] | Stowers RS, Allen SC, Suggs LJ (2015) Dynamic phototuning of 3D hydrogel stiffness. Proceedings of the National Academy of Sciences, 112: 1953–1958. |
| [17] |
Gonen-Wadmany M, Oss-Ronen L, Seliktar D (2007) Protein-polymer conjugates for forming photopolymerizable biomimetic hydrogels for tissue engineering. Biomaterials 28: 3876–3886. doi: 10.1016/j.biomaterials.2007.05.005
|
| [18] |
Nichol JW, Koshy ST, Bae H, et al. (2010) Cell-laden microengineered gelatin methacrylate hydrogels. Biomaterials 31: 5536–5544. doi: 10.1016/j.biomaterials.2010.03.064
|
| [19] |
Soman P, Chung PH, Zhang AP, et al. (2013) Digital microfabrication of user-defined 3D microstructures in cell-laden hydrogels. Biotechnol Bioeng 110: 3038–3047. doi: 10.1002/bit.24957
|
| [20] |
Fairbanks BD, Singh SP, Bowman CN, et al. (2011) Photodegradable, photoadaptable hydrogels via radical-mediated disulfide fragmentation reaction. Macromolecules 44: 2444–2450. doi: 10.1021/ma200202w
|
| [21] |
Chen YX, Yang S, Yan J, et al. (2015) A Novel Suspended Hydrogel Membrane Platform for Cell Culture. J Nanotechnol Eng Med 6: 021002. doi: 10.1115/1.4031231
|
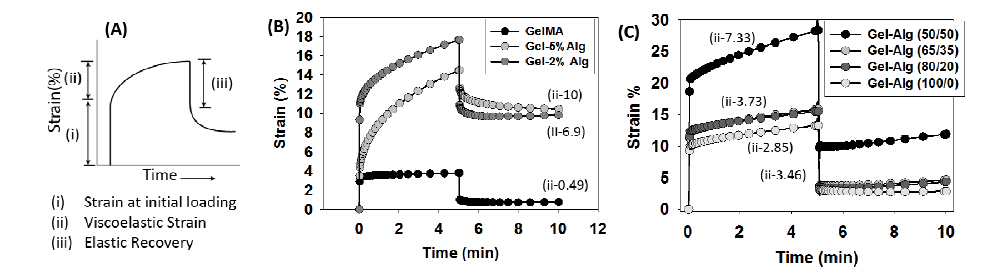
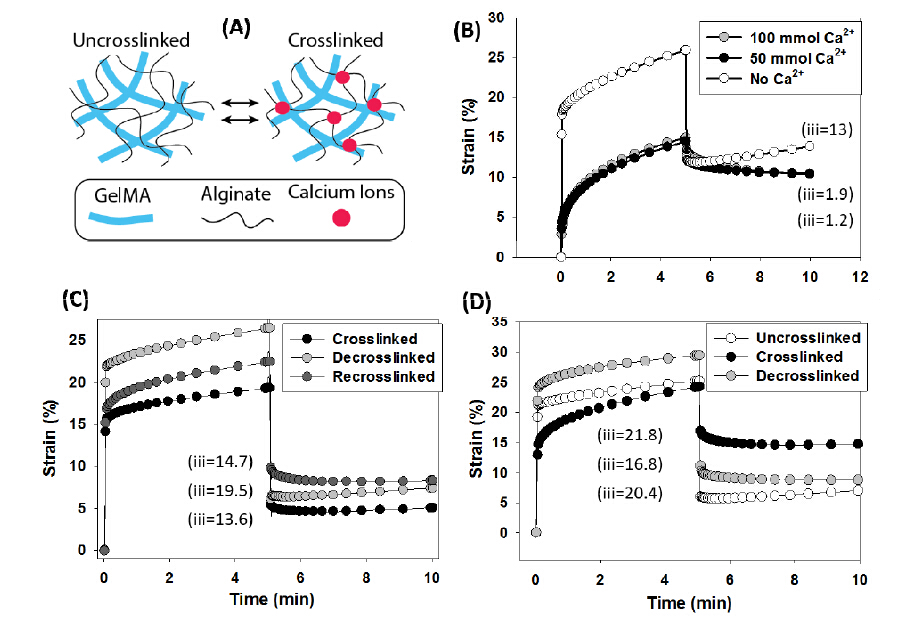
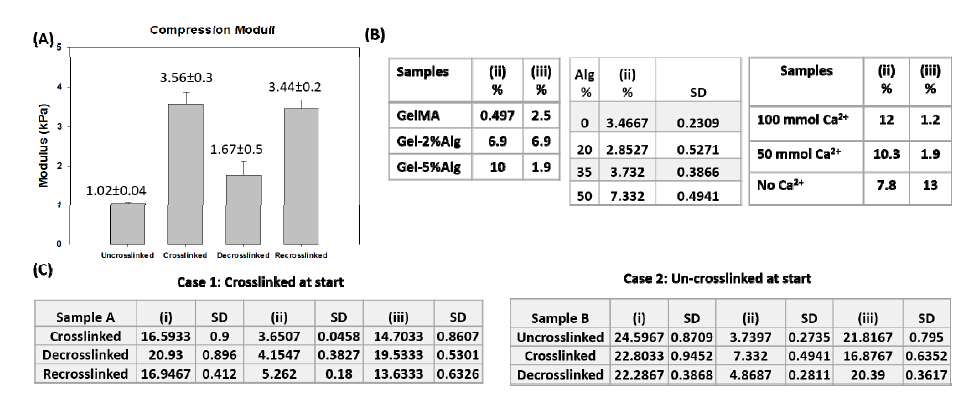
Figures(3)

Yong X. Chen, Brian Cain, Pranav Soman. Gelatin methacrylate-alginate hydrogel with tunable viscoelastic properties[J]. AIMS Materials Science, 2017, 4(2): 363-369. doi: 10.3934/matersci.2017.2.363







 DownLoad:
DownLoad: