Citation: Rabia Aziz, C.K. Verma, Namita Srivastava. Dimension reduction methods for microarray data: a review[J]. AIMS Bioengineering, 2017, 4(1): 179-197. doi: 10.3934/bioeng.2017.1.179

| [1] |
Chang TW (1983) Binding of cells to matrixes of distinct antibodies coated on solid surface. J Immunol Methods 65: 217–223. doi: 10.1016/0022-1759(83)90318-6

|
| [2] |
Lenoir T, Giannella E (2006) The emergence and diffusion of DNA microarray technology. J Biomed Discov Collab 1: 11–49. doi: 10.1186/1747-5333-1-11
|
| [3] | Pirrung MC, Read LJ, Fodor SPA, et al. (1992) Large scale photolithographic solid phase synthesis of polypeptides and receptor binding screening thereof: US, US5143854[P]. |
| [4] | Peng S, Xu Q, Ling XB, et al. (2003) Molecular classification of cancer types from microarray data using the combination of genetic algorithms and support vector machines. Febs Lett 555: 358–362. |
| [5] | Statnikov A, Aliferis CF, Tsamardinos I, et al. (2005) A comprehensive evaluation of multicategory classification methods for microarray gene expression cancer diagnosis. Bioinformatics 21: 631–643. |
| [6] |
Tan Y, Shi L, Tong W, et al. (2005) Multi-class cancer classification by total principal component regression (TPCR) using microarray gene expression data. Nucleic Acids Res 33: 56–65. doi: 10.1093/nar/gki144
|
| [7] |
Eisen MB, Brown PO (1999) DNA arrays for analysis of gene expression. Method Enzymol 303: 179–205. doi: 10.1016/S0076-6879(99)03014-1
|
| [8] |
Leng C (2008) Sparse optimal scoring for multiclass cancer diagnosis and biomarker detection using microarray data. Comput Biol Chem 32: 417–425. doi: 10.1016/j.compbiolchem.2008.07.015
|
| [9] |
Quackenbush J (2001) Computational analysis of microarray data. Nat Rev Genet 2: 418–427. doi: 10.1038/35076576
|
| [10] | Piatetsky-Shapiro G, Tamayo P (2003) Microarray data mining: facing the challenges. ACM Sigkdd Explor Newslett 5: 1–5. |
| [11] | Eisen MB, Spellman PT, Brown PO, et al. (1998) Cluster analysis and display of genome-wide expression patterns. P Natl Acad Sci USA 95: 14863–14868. |
| [12] |
Golub TR, Slonim DK, Tamayo P, et al. (1999) Molecular classification of cancer: class discovery and class prediction by gene expression monitoring. Science 286: 531–537. doi: 10.1126/science.286.5439.531
|
| [13] | O'Neill MC, Song L (2003) Neural network analysis of lymphoma microarray data: prognosis and diagnosis near-perfect. Bioinformatics 4: 1–12. |
| [14] | Beer DG, Kardia SL, Huang CC, et al. (2002) Gene-expression profiles predict survival of patients with lung adenocarcinoma. Nat Med 8: 816–824. |
| [15] | Lee JW, Lee JB, Park M, et al. (2005) An extensive comparison of recent classification tools applied to microarray data. Comput Stat Data An 48: 869–885. |
| [16] |
You W, Yang Z, Yuan M, et al. (2014) Totalpls: local dimension reduction for multicategory microarray data. IEEE T Hum Mach Syst 44: 125–138. doi: 10.1109/THMS.2013.2288777
|
| [17] | Xi M, Sun J, Liu L, et al. (2016) Cancer feature selection and classification using a binary quantum-behaved particle swarm optimization and support vector machine. Comput Math Method Med 2016: 1–9. |
| [18] |
Wang L, Feng Z, Wang X, et al. (2010) DEGseq: an R package for identifying differentially expressed genes from RNA-seq data. Bioinformatics 26: 136–138. doi: 10.1093/bioinformatics/btp612
|
| [19] |
Shen Q, Mei Z, Ye BX (2009) Simultaneous genes and training samples selection by modified particle swarm optimization for gene expression data classification. Comput Biol Med 39: 646–649. doi: 10.1016/j.compbiomed.2009.04.008
|
| [20] | Xie J, Xie W, Wang C, et al. (2010) A novel hybrid feature selection method based on ifsffs and svm for the diagnosis of erythemato-squamous diseases. J Mach Learn Res 11: 142–151. |
| [21] |
Chuang LY, Yang CH, Wu KC, et al. (2011) A hybrid feature selection method for DNA microarray data. Comput Biol Med 41: 228–237. doi: 10.1016/j.compbiomed.2011.02.004
|
| [22] |
Li B, Zheng CH, Huang DS, et al. (2010) Gene expression data classification using locally linear discriminant embedding. Comput Biol Med 40: 802–810. doi: 10.1016/j.compbiomed.2010.08.003
|
| [23] | Mahajan S, Singh S (2016) Review on feature selection approaches using gene expression data. IJIR 2: 356–364. |
| [24] |
Pinkel D, Segraves R, Sudar D, et al. (1998) High resolution analysis of DNA copy number variation using comparative genomic hybridization to microarrays. Nat Genet 20: 207–211. doi: 10.1038/2524
|
| [25] |
Cheadle C, Vawter MP, Freed WJ, et al. (2003) Analysis of microarray data using Z score transformation. J Mol Diagn 5: 73–81. doi: 10.1016/S1525-1578(10)60455-2
|
| [26] | Witten IH, Frank E (2016) Data mining: practical machine learning tools and techniques, 4th Edition, Morgan Kaufmannis, 4–7. |
| [27] | Dubitzky W, Granzow M, Berrar D (2002) Data mining and machine learning methods for microarray analysis, In: Methods of microarray data analysis,Springer US, 5–22. |
| [28] |
Brown MP, Grundy WN, Lin D, et al. (2000) Knowledge-based analysis of microarray gene expression data by using support vector machines. P Natl Acad Sci USA 97: 262–267. doi: 10.1073/pnas.97.1.262
|
| [29] |
Dudoit S, Fridlyand J, Speed TP (2002) Comparison of discrimination methods for the classification of tumors using gene expression data. J Am Stat Assoc 97: 77–87. doi: 10.1198/016214502753479248
|
| [30] |
Khan J, Wei JS, Ringner M, et al. (2001) Classification and diagnostic prediction of cancers using gene expression profiling and artificial neural networks. Nat Med 7: 673–679. doi: 10.1038/89044
|
| [31] | Zheng CH, Huang DS, Shang L (2006) Feature selection in independent component subspace for microarray data classification. Neurocomputing 69: 2407–2410. |
| [32] |
Peng Y (2006) A novel ensemble machine learning for robust microarray data classification. Comput Biol Med 36: 553–573. doi: 10.1016/j.compbiomed.2005.04.001
|
| [33] | Mohan A, Rao MD, Sunderrajan S, et al. (2014) Automatic classification of protein structures using physicochemical parameters. Interdiscipl Sci 6: 176–186. |
| [34] |
Saeys Y, Inza I, Larrañaga P (2007) A review of feature selection techniques in bioinformatics. Bioinformatics 23: 2507–2517. doi: 10.1093/bioinformatics/btm344
|
| [35] | Jirapech-Umpai T, Aitken S (2005) Feature selection and classification for microarray data analysis: Evolutionary methods for identifying predictive genes. Bioinformatics 6: 148–148. |
| [36] | Law MH, Figueiredo MA, Jain AK (2004) Simultaneous feature selection and clustering using mixture models. IEEE T Pattern Anal 26: 1154–1166. |
| [37] | Lazar C, Taminau J, Meganck S, et al. (2012) A survey on filter techniques for feature selection in gene expression microarray analysis. IEEE/ACM T Comput BiolBioinform 9: 1106–1119. |
| [38] | Guyon I, Elisseeff A (2003) An introduction to variable and feature selection. J Mach Learn Res 3: 1157–1182. |
| [39] | Ang JC, Mirzal A, Haron H, et al. (2015) Supervised, unsupervised and semi-supervised feature selection: a review on gene selection. IEEE/ACM T Comput BiolBioinform 13: 971–989. |
| [40] |
Chandrashekar G, Sahin F (2014) A survey on feature selection methods. Comput Electr Eng 40: 16–28. doi: 10.1016/j.compeleceng.2013.11.024
|
| [41] |
Lin KS, Chien CF (2009) Cluster analysis of genome-wide expression data for feature extraction. Expert Syst Appl 36: 3327–3335. doi: 10.1016/j.eswa.2008.01.068
|
| [42] | Sun Y, Todorovic S, Goodison S (2010) Local-learning-based feature selection for high-dimensional data analysis. IEEE T Pattern Anal 32: 1610–1626. |
| [43] |
Zhu S, Wang D, Yu K, et al. (2010) Feature selection for gene expression using model-based entropy. IEEE/ACM T Comput BiolBioinform 7: 25–36. doi: 10.1109/TCBB.2008.35
|
| [44] | Mishra D, Sahu B (2011) Feature selection for cancer classification: a signal-to-noise ratio approach. IJSER 2: 1–7. |
| [45] | Wei D, Li S, Tan M (2012) Graph embedding based feature selection. Neurocomputing 93: 115–125. |
| [46] | Liu JX, Wang YT, Zheng CH, et al. (2013) Robust PCA based method for discovering differentially expressed genes. BMC bioinform 14: S3. |
| [47] | Maulik U, Chakraborty D (2014) Fuzzy preference based feature selection and semisupervised SVM for cancer classification. IEEE T Nano Biosci 13: 152–160. |
| [48] | Chinnaswamy A, Srinivasan R (2016) Hybrid feature selection using correlation coefficient and particle swarm optimization on microarray gene expression data. IBICA, 229–239. |
| [49] | Mortazavi A, Moattar MH (2016) Robust feature selection from microarray data based on cooperative game theory and qualitative mutual information. Adv Bioinform 2016: 1–16. |
| [50] | John GH, Kohavi R, Pfleger K (1994) Irrelevant features and the subset selection problem, In: machine learning, Proceedings of the Eleventh International Conference, 121–129. |
| [51] |
Kohavi R, John GH (1997) Wrappers for feature subset selection. Artif Intel 97: 273–324. doi: 10.1016/S0004-3702(97)00043-X
|
| [52] |
Somol P, Pudil P, Novovičová J, et al. (1999) Adaptive floating search methods in feature selection. Pattern Recogn Lett 20: 1157–1163. doi: 10.1016/S0167-8655(99)00083-5
|
| [53] | Youssef H, Sait SM, Adiche H (2001) Evolutionary algorithms, simulated annealing and tabu search: a comparative study. Eng Appl Artif Intel 14: 167–181. |
| [54] | Maugis C, Celeux G, Martin-Magniette ML (2009) Variable selection for clustering with Gaussian mixture models. Biometrics 65: 701–709. |
| [55] | Ai-Jun Y, Xin YS (2010) Bayesian variable selection for disease classification using gene expression data. Bioinformatics 26: 215–222. |
| [56] |
Ji G, Yang Z, You W (2011) PLS-based gene selection and identification of tumor-specific genes. IEEE T Syst Man Cy C 41: 830–841. doi: 10.1109/TSMCC.2010.2078503
|
| [57] | Sharma A, Imoto S, Miyano S (2012) A top-r feature selection algorithm for microarray gene expression data. IEEE/ACM T Comput BiolBioinform 9: 754–764. |
| [58] |
Cadenas JM, Garrido MC, MartíNez R (2013) Feature subset selection filter–wrapper based on low quality data. Expert Syst Appl 40: 6241–6252. doi: 10.1016/j.eswa.2013.05.051
|
| [59] | Srivastava B, Srivastava R, Jangid M (2014) Filter vs. wrapper approach for optimum gene selection of high dimensional gene expression dataset: an analysis with cancer datasets. IEEE High Perform Comput Appl 454: 1–6. |
| [60] | Kar S, Sharma KD, Maitra M (2016) A particle swarm optimization based gene identification technique for classification of cancer subgroups. IEEE Control Instrum Energ Commun, 130–134. |
| [61] | Kumar V, Minz S (2014) Feature selection:a literature review. Smart Cr 4: 211–229. |
| [62] | Niijima S, Okuno Y (2009) Laplacian linear discriminant analysis approach to unsupervised feature selection. IEEE/ACM T Comput BiolBioinform 6: 605–614. |
| [63] | Cai X, Nie F, Huang H, et al. (2011) Multi-class l2, 1-norm support vector machine. IEEE Comput Soc, 91–100. |
| [64] | Maldonado S, Weber R, Basak J (2011) Simultaneous feature selection and classification using kernel-penalized support vector machines. Inform Sci Int J 181: 115–128. |
| [65] |
Xiang S, Nie F, Meng G, et al. (2012) Discriminative least squares regression for multiclass classification and feature selection. IEEE T Neur Netw Learn Syst 23: 1738–1754. doi: 10.1109/TNNLS.2012.2212721
|
| [66] | Lan L, Djuric N, Guo Y, et al. (2013) MS-kNN: protein function prediction by integrating multiple data sources. Bioinformatics 14: S8. |
| [67] | Cao J, Zhang L, Wang B, et al. (2015) A fast gene selection method for multi-cancer classification using multiple support vector data description. J Biomed Inform 53: 381–389. |
| [68] | Lan L, Vucetic S (2011) Improving accuracy of microarray classification by a simple multi-task feature selection filter. Int J Data Min Bioinform 5: 189–208. |
| [69] | Kursa MB (2016) Embedded all relevant feature selection with random ferns. arXiv preprint arXiv: 1604.06133. |
| [70] | Bartenhagen C, Klein HU, Ruckert C, et al. (2010) Comparative study of unsupervised dimension reduction techniques for the visualization of microarray gene expression data. Bioinformatics 11: 567–577. |
| [71] | Kotsiantis S (2011) Feature selection for machine learning classification problems: a recent overview. Artif Intell Rev, 1–20. |
| [72] | Hira ZM, Gillies DF (2015) A review of feature selection and feature extraction methods applied on microarray data. Adv Bioinform 2015: 1–13. |
| [73] | Tzeng J, Lu HH, Li WH (2008) Multidimensional scaling for large genomic data sets. Bioinformatics 9: 179–195. |
| [74] | Ehler M, Rajapakse VN, Zeeberg BR, et al. (2011) Nonlinear gene cluster analysis with labeling for microarray gene expression data in organ development. BMC proc 5: S3. |
| [75] |
Kong W, Vanderburg CR, Gunshin H, et al. (2008) A review of independent component analysis application to microarray gene expression data. Biotechniques 45: 501–520. doi: 10.2144/000112950
|
| [76] |
Aziz R, Verma C, Srivastava N (2016) A fuzzy based feature selection from independent component subspace for machine learning classification of microarray data. Genom Data 8: 4–15. doi: 10.1016/j.gdata.2016.02.012
|
| [77] |
Hsu CC, Chen MC, Chen LS (2010) Integrating independent component analysis and support vector machine for multivariate process monitoring. Comput Ind Eng 59: 145–156. doi: 10.1016/j.cie.2010.03.011
|
| [78] | Naik GR, Kumar DK (2011) An overview of independent component analysis and its applications. Informatica 35: 63–81. |
| [79] |
Huang Y, Lowe HJ (2007) A novel hybrid approach to automated negation detection in clinical radiology reports. J Am Med Inform Assoc 14: 304–311. doi: 10.1197/jamia.M2284
|
| [80] | Aziz R, Verma C, Srivastava N (2015) A weighted-SNR feature selection from independent component subspace for nb classification of microarray data. Int J Adv Biotec Res 6: 245–255. |
| [81] | Aziz R, Srivastava N, Verma C (2015) T-independent component analysis for svm classification of dna-microarray data. Int J Bioinform Res 6: 305–312. |
| [82] |
Zibakhsh A, Abadeh MS (2013) Gene selection for cancer tumor detection using a novel memetic algorithm with a multi-view fitness function. Eng Appl Artif Intel 26: 1274–1281. doi: 10.1016/j.engappai.2012.12.009
|
| [83] | Zhao W, Wang G, Wang Hb, et al. (2011) A novel framework for gene selection. Int J Adv Comput Technol 3: 184–191. |
| [84] | Alshamlan H, Badr G, Alohali Y (2015) mRMR-ABC: a hybrid gene selection algorithm for cancer classification using microarray gene expression profiling. Bio Med Res Int 2015: 1–15. |
| [85] |
Hu Q, Pan W, An S, et al. (2010) An efficient gene selection technique for cancer recognition based on neighborhood mutual information. Int J Mach Learn Cybern 1: 63–74. doi: 10.1007/s13042-010-0008-6
|
| [86] | El Akadi A, Amine A, El Ouardighi A, et al. (2011) A two-stage gene selection scheme utilizing MRMR filter and GA wrapper. Knowl Inform Syst 26: 487–500. |
| [87] | Shreem SS, Abdullah S, Nazri MZA, et al. (2012) Hybridizing ReliefF, MRMR filters and GA wrapper approaches for gene selection. J Theor Appl Inform Technol 46: 1034–1039. |
| [88] | Alshamlan HM, Badr GH, Alohali YA (2015) Genetic bee colony (GBC) algorithm: a new gene selection method for microarray cancer classification. Comput Bio Chem 56: 49–60. |
| [89] | Chuang LY, Yang CH, Yang CH (2009) Tabu search and binary particle swarm optimization for feature selection using microarray data. J Comput Biol 16: 1689–1703. |
| [90] |
Tong DL, Mintram R (2010) Genetic algorithm-neural network (GANN): a study of neural network activation functions and depth of genetic algorithm search applied to feature selection. Int J Mach Learn Cybern 1: 75–87. doi: 10.1007/s13042-010-0004-x
|
| [91] | Shi P, Ray S, Zhu Q, et al. (2011) Top scoring pairs for feature selection in machine learning and applications to cancer outcome prediction. Bioinformatics 12: 375–399. |
| [92] |
Liu Q, Zhao Z, Li YX, et al. (2012) Feature selection based on sensitivity analysis of fuzzy ISO data. Neurocomputing 85: 29–37. doi: 10.1016/j.neucom.2012.01.005
|
| [93] | Hajiloo M, Rabiee HR, Anooshahpour M (2013) Fuzzy support vector machine: an efficient rule-based classification technique for microarrays. Bioinformatics 14: S4. |
| [94] | Chang SW, Abdul-Kareem S, Merican AF, et al. (2013) Oral cancer prognosis based on clinicopathologic and genomic markers using a hybrid of feature selection and machine learning methods. Bioinformatics 14:1–15. |
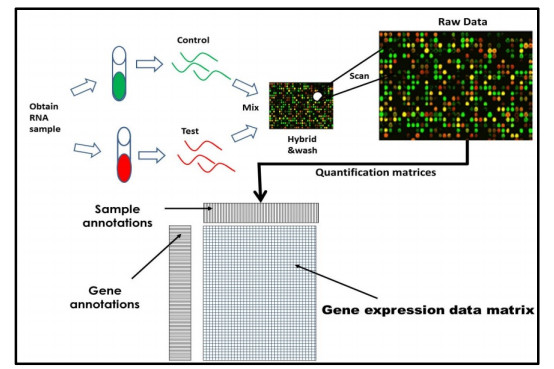
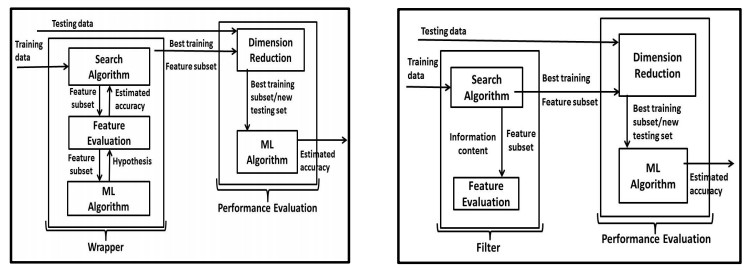
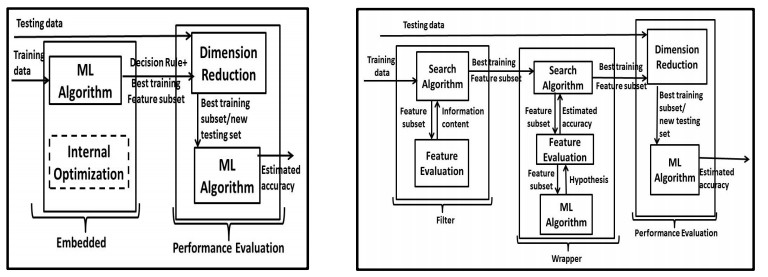
Figures(3) / Tables(5)

Rabia Aziz, C.K. Verma, Namita Srivastava. Dimension reduction methods for microarray data: a review[J]. AIMS Bioengineering, 2017, 4(1): 179-197. doi: 10.3934/bioeng.2017.1.179







 DownLoad:
DownLoad: