Citation: Aderemi T. Adeleye, Hitler Louis, Ozioma U. Akakuru, Innocent Joseph, Obieze C. Enudi, Dass P. Michael. A Review on the conversion of levulinic acid and its esters to various useful chemicals[J]. AIMS Energy, 2019, 7(2): 165-185. doi: 10.3934/energy.2019.2.165

| [1] | Adeleye AT, Louis H, Temitope HA, et al. (2019). Ionic liquids (ILs): advances in biorefinery for the efficient conversion of lignocellulosic biomass. Asian J Green Chem 3: 391–417. |
| [2] |
Tilman D, Hill J, Lehman C (2006). Carbon-Negative biofuels from Low-Input High-Diversity grassland biomass. Science 314: 1598–1600. doi: 10.1126/science.1133306

|
| [3] | International Energy Outlook 2016 with Projections to 2040. A report by U.S. Energy Information Administration (EIA), 2016. Available from: https://www.eia.gov/outlooks/ieo/pdf/0484(2016). |
| [4] |
Mohanty AK, Misra M, Drzal LT (2002) Sustainable Bio-Composites from renewable resources: opportunities and challenges in the green materials world. J Polym Environ 10: 19–26. doi: 10.1023/A:1021013921916
|
| [5] | Belkacemi K, Kemache N, Hamoudi S, et al. (2007) Hydrogenation of sunflower oil over bimetallic supported catalysts on mesostructured silica material. Int J Chem React Eng 5: 1–28. |
| [6] |
Makshina EV, Dusselier M, Janssens W, et al. (2014) Review of old chemistry and new catalytic advances in the on-purpose synthesis of butadiene. Chem Soc Rev 43: 7917–7953. doi: 10.1039/C4CS00105B
|
| [7] | Bridgwater A (2013) Fast pyrolysis of biomass for the production of liquids for use as fuels and chemicals. Biomass Combust Sci, Technol Eng 7: 130–171. |
| [8] | Top value added chemicals from biomass. Volume I-Results of screening for potential candidates from sugars and synthesis gas (2004). Available from: https://www.nrel.gov/docs/fy04osti/35523.pdf. |
| [9] |
Jow J, Rorrer GL, Hawley MC, et al. (1987) Dehydration of d-fructose to levulinic acid over LZY zeolite catalyst. Biomass 14: 185–194. doi: 10.1016/0144-4565(87)90046-1
|
| [10] |
Serrano-Ruiz JC, West RM, Dumesic JA (2010) Catalytic conversion of renewable biomass resources to fuels and chemicals. Annu Rev Chem Biomol Eng 1: 79–100. doi: 10.1146/annurev-chembioeng-073009-100935
|
| [11] |
Andersson-Engels S, Berg R, Svanberg K, et al. (1995) Multi‐colour fluorescence imaging in connection with photodynamic therapy of δ‐amino levulinic acid (ALA) sensitised skin malignancies. Bioimaging 3: 134–143. doi: 10.1002/1361-6374(199509)3:3<134::AID-BIO4>3.3.CO;2-T
|
| [12] |
Zhang J, Wu S, Li B, et al. (2012) Advances in the catalytic production of valuable Levulinic Acid derivatives. ChemCatChem 4: 1230–1237. doi: 10.1002/cctc.201200113
|
| [13] |
Pasquale G, Vázquez P, Romanelli G, et al. (2012) Catalytic upgrading of levulinic acid to ethyl levulinate using reusable silica-included Wells-Dawson heteropolyacid as catalyst. Catal Commun 18: 115–120. doi: 10.1016/j.catcom.2011.12.004
|
| [14] |
Huber GW, Iborra S, Corma A (2006) Synthesis of transportation fuels from biomass: Chemistry, catalysts, and engineering. Chem Rev 106: 4044–4098. doi: 10.1021/cr068360d
|
| [15] |
Tiong YW, Yap CL, Gan S, et al. (2018) Conversion of biomass and its derivatives to levulinic acid and levulinate esters via ionic liquids. Ind Eng Chem Res 57: 4749–4766. doi: 10.1021/acs.iecr.8b00273
|
| [16] |
Yu HT, Chen BY, Li BY, et al. (2018) Efficient pretreatment of lignocellulosic biomass with high recovery of solid lignin and fermentable sugars using Fenton reaction in a mixed solvent. Biotechnol Biofuels 11: 287. doi: 10.1186/s13068-018-1288-4
|
| [17] |
Rackemann DW, Doherty WO (2011) The conversion of lignocellulosics to levulinic acid. Biofuels, Bioprod Biorefin 5: 198–214. doi: 10.1002/bbb.267
|
| [18] | Mthembu LD (2016) Production of levulinic acid from sugarcane bagasse. Available from: https://openscholar.dut.ac.za/handle/10321/1713.pdf. |
| [19] | Morrison RT, Boyd RN (1983) "Organic Chemistry", 4th Eds., Allyn and Bacon, Inc. Boston, 338. |
| [20] |
Chalid M, Heeres HJ, Broekhuis AA (2012) Green polymer precursors from Biomass-Based levulinic acid. Procedia Chem 4: 260–267. doi: 10.1016/j.proche.2012.06.036
|
| [21] |
Horváth IT, Mehdi H, Fábos V, et al. (2008) γ-Valerolactone-a sustainable liquid for energy and carbon-based chemicals. Green Chem 10: 238–242. doi: 10.1039/B712863K
|
| [22] |
Fegyverneki D, Orha L, Láng G, et al. (2010) Gamma-valerolactone-based solvents. Tetrahedron 66: 1078–1081. doi: 10.1016/j.tet.2009.11.013
|
| [23] | Van der Waal JC, de Jong E (2016) Avantium Chemicals: The high potential for the levulinic product tree. Ind Biorenewables 4: 97–120. |
| [24] |
Su K, Li Z, Cheng B, et al. (2010) Studies on the carboxymethylation and methylation of bisphenol A with dimethyl carbonate over TiO2/SBA-15. J Mol Catal A: Chem 315: 60–68. doi: 10.1016/j.molcata.2009.08.027
|
| [25] |
Yan Z, Lin L, Liu S (2009) Synthesis of γ-Valerolactone by hydrogenation of biomass-derived levulinic acid over Ru/C Catalyst. Energy Fuels 23: 3853–3858. doi: 10.1021/ef900259h
|
| [26] |
Tukacs JM, Király D, Strádi A, et al. (2012) Efficient catalytic hydrogenation of levulinic acid: a key step in biomass conversion. Green Chem 14: 2057–2067. doi: 10.1039/c2gc35503e
|
| [27] |
Ruppert AM, Jędrzejczyk M, Sneka-Płatek O, et al. (2016) Ru catalysts for levulinic acid hydrogenation with formic acid as a hydrogen source. Green Chem 18: 2014–2028. doi: 10.1039/C5GC02200B
|
| [28] |
Jones DR, Iqbal S, Miedziak PJ, et al. (2018) Selective hydrogenation of levulinic acid using Ru/C catalysts prepared by Sol-Immobilisation. Top Catal 61: 833–843. doi: 10.1007/s11244-018-0927-0
|
| [29] |
Joó F, Beck MT (1975) Formation and catalytic properties of water-soluble phosphine complexes. React Kinet Catal Lett 2: 257–263. doi: 10.1007/BF02068199
|
| [30] |
Mehdi H, Fábos V, Tuba R, et al. (2008) Integration of homogeneous and heterogeneous catalytic processes for a Multi-step conversion of biomass: From sucrose to levulinic acid, γ-Valerolactone, 1,4-Pentanediol, 2-Methyl-tetrahydrofuran, and alkanes. Top Catal 48: 49–54. doi: 10.1007/s11244-008-9047-6
|
| [31] |
Mallat T, Baiker A (2004) Oxidation of alcohols with molecular oxygen on solid catalysts. Chem Rev 104: 3037–3058. doi: 10.1021/cr0200116
|
| [32] |
Werkmeister S, Junge K, Beller M (2014) Catalytic hydrogenation of carboxylic acid esters, amides, and nitriles with homogeneous catalysts. Org Process Res Dev 18: 289–302. doi: 10.1021/op4003278
|
| [33] |
Geilen FMA, Engendahl B, Hölscher M, et al. (2011) Selective homogeneous hydrogenation of biogenic carboxylic acids with [Ru(TriPhos)H]+: A mechanistic study. J Am Chem Soc 133: 14349–14358. doi: 10.1021/ja2034377
|
| [34] |
Fábos V, Koczó G, Mehdi H, et al. (2009) Bio-oxygenates and the peroxide number: a safety issue alert. Energy Environ Sci 2: 767–770. doi: 10.1039/b900229b
|
| [35] |
Feng J, Gu X, Xue Y, et al. (2018) Production of γ-valerolactone from levulinic acid over a Ru/C catalyst using formic acid as the sole hydrogen source. Sci Total Environ 633: 426–432. doi: 10.1016/j.scitotenv.2018.03.209
|
| [36] |
Piskun AS, de Haan JE, Wilbers E, et al. (2016) Hydrogenation of levulinic acid to γ-Valerolactone in water using millimeter sized supported Ru catalysts in a packed bed reactor. ACS Sustainable Chem Eng 4: 2939–2950. doi: 10.1021/acssuschemeng.5b00774
|
| [37] | Balla P, Perupogu V, Vanama PK, et al. (2015) Hydrogenation of biomass-derived levulinic acid to γ-valerolactone over copper catalysts supported on ZrO2. J Chem Technol Biotechnol 91: 769–776. |
| [38] |
Mohan V, Raghavendra C, Pramod CV, et al. (2014) Ni/H-ZSM-5 as a promising catalyst for vapour phase hydrogenation of levulinic acid at atmospheric pressure. RSC Adv 4: 9660–9669. doi: 10.1039/c3ra46485g
|
| [39] |
Alonso DM, Wettstein SG, Dumesic JA, et al. (2013) Gamma-valerolactone, a sustainable platform molecule derived from lignocellulosic biomass. Green Chem 15: 584–595. doi: 10.1039/c3gc37065h
|
| [40] | Girisuta B, Heeres HJ (2017) Levulinic acid from biomass: Synthesis and applications. In: Biofuels and Biorefineries, 143–169. |
| [41] |
Motagamwala AH, Won W, Dumesic JA, et al. (2016) An engineered solvent system for sugar production from lignocellulosic biomass using biomass derived gammavalerolactone. Green Chem 18: 5756–5763. doi: 10.1039/C6GC02297A
|
| [42] |
Rodenas Olaya Y, Mariscal R, Fierro JLG, et al. (2018) Granados, Improving the production of maleic acid from biomass: TS-1 catalysed aqueous phase oxidation of furfural in the presence of γ-valerolactone. Green Chem 20: 2845–2856. doi: 10.1039/C8GC00857D
|
| [43] |
Canan S, Hussain MA, Martin AD, et al. (2018) Enhanced furfural yields from xylose dehydration in the γ-Valerolactone/Water solvent system at elevated temperatures. ChemSusChem 11: 2321–2331. doi: 10.1002/cssc.201800730
|
| [44] |
Moreno-Marrodan C, Barbaro P (2014) Energy efficient continuous production of γ-valerolactone by bifunctional metal/acid catalysis in one pot. Green Chem 16: 3434–3438. doi: 10.1039/c4gc00298a
|
| [45] |
Tadele K, Verma S, Gonzalez MA, et al. (2017) A sustainable approach to empower the bio-based future: upgrading of biomass via process intensification. Green Chem 19: 1624–1627. doi: 10.1039/C6GC03568J
|
| [46] | Gerardy R, Morodo R, Estager J, et al. (2018) Sustaining the Transition from a petrobased to a Biobased Chemical Industry with Flow Chemistry. Top Curr Chem 377: 1–35. |
| [47] |
Bozell JJ, Petersen GR (2010) Technology development for the production of biobased products from biorefinery carbohydrates-the US Department of Energy's 'Top 10' revisited. Green Chem 12: 539–556. doi: 10.1039/b922014c
|
| [48] |
Fortman JL, Chhabra S, Mukhopadhyay A, et al. (2008) Biofuel alternatives to ethanol: pumping the microbial well. Trends Biotechnol 26: 375–381. doi: 10.1016/j.tibtech.2008.03.008
|
| [49] |
Serrano-Ruiz JC, Dumesic JA (2009) Catalytic upgrading of lactic acid to fuels and chemicals by dehydration/hydrogenation and C–C coupling reactions. Green Chem 11: 1101–1106. doi: 10.1039/b906869d
|
| [50] |
Abdelrahman OA, Heyden A, Bond JQ (2014) Analysis of kinetics and reaction pathways in the Aqueous-Phase hydrogenation of levulinic acid to form γ-Valerolactone over Ru/C. ACS Catal 4: 1171–1181. doi: 10.1021/cs401177p
|
| [51] |
Prati L, Jouve A, Villa A (2017) Production and upgrading of γ-Valerolactone with bifunctional catalytic processes. Biofuels Biorefin 8: 221–237. doi: 10.1007/978-981-10-5137-1_7
|
| [52] |
Patankar SC, Yadav GD (2015) Cascade engineered synthesis of γ-Valerolactone, 1,4-Pentanediol, and 2-Methyltetrahydrofuran from levulinic acid using Pd–Cu/ZrO2Catalyst in water as solvent. ACS Sustainable Chem Eng 3: 2619–2630. doi: 10.1021/acssuschemeng.5b00763
|
| [53] |
Obregón I, Gandarias I, Miletić N, et al. (2015) One-Pot 2-Methyltetrahydrofuran production from levulinic acid in green solvents using Ni-Cu/Al2O3 catalysts. ChemSusChem 8: 3483–3488. doi: 10.1002/cssc.201500671
|
| [54] |
Phanopoulos A, White AJP, Long NJ, et al. (2015) Catalytic transformation of levulinic acid to 2-Methyltetrahydrofuran using ruthenium–N-Triphos complexes. ACS Catal 5: 2500–2512. doi: 10.1021/cs502025t
|
| [55] |
De Lima AEP, de Oliveira DC (2017) In situ XANES study of cobalt in Co-Ce-Al catalyst applied to steam reforming of ethanol reaction. Catal Today 283: 104–109. doi: 10.1016/j.cattod.2016.02.029
|
| [56] |
Du XL, Bi QY, Liu YM, et al. (2012) Tunable copper-catalyzed chemoselective hydrogenolysis of biomass-derived γ-valerolactone into 1,4-pentanediol or 2-methyltetrahydrofuran. Green Chem 14: 935–939. doi: 10.1039/c2gc16599f
|
| [57] |
Al-Shaal MG, Dzierbinski A, Palkovits R (2014) Solvent-free γ-valerolactone hydrogenation to 2-methyltetrahydrofuran catalysed by Ru/C: a reaction network analysis. Green Chem 16: 1358–1364. doi: 10.1039/C3GC41803K
|
| [58] |
Delidovich I, Palkovits R (2016) Catalytic isomerization of Biomass-Derived aldoses: A Review. ChemSusChem 9: 547–561. doi: 10.1002/cssc.201501577
|
| [59] |
Mizugaki T, Nagatsu Y, Togo K, et al. (2015) Selective hydrogenation of levulinic acid to 1,4-pentanediol in water using a hydroxyapatite-supported Pt–Mo bimetallic catalyst. Green Chem 17: 5136–5139. doi: 10.1039/C5GC01878A
|
| [60] |
Licursi D, Antonetti C, Fulignati S, et al. (2018) Cascade strategy for the tunable catalytic valorization of levulinic acid and γ-Valerolactone to 2-Methyltetrahydrofuran and alcohols. Catalysts 8: 277–293. doi: 10.3390/catal8070277
|
| [61] | Wittstock A, Bäumer M (2013) Catalysis by unsupported skeletal gold catalysts. Acc Chem Res 47: 731–739. |
| [62] |
Velisoju VK, Gutta N, Tardio J, et al. (2018) Hydrodeoxygenation activity of W modified Ni/H-ZSM-5 catalyst for single step conversion of levulinic acid to pentanoic acid: An insight on the reaction mechanism and structure activity relationship. Appl Catal A: Gen 550: 142–150. doi: 10.1016/j.apcata.2017.11.008
|
| [63] | Isikgor FH, Becer CR (2015) Lignocellulosic biomass: a sustainable platform for the production of bio-based chemicals and polymers. Polym Chem 6: 4497–4559. |
| [64] |
Di Mondo D, Ashok D, Waldie F, et al. (2011) Stainless steel as a catalyst for the total deoxygenation of glycerol and levulinic acid in aqueous acidic medium. ACS Catal 1: 355–364. doi: 10.1021/cs200053h
|
| [65] |
Lin H, Strull J, Liu Y, et al. (2012) High yield production of levulinic acid by catalytic partial oxidation of cellulose in aqueous media. Energy Environ Sci 5: 9773–9781. doi: 10.1039/c2ee23225a
|
| [66] |
Weingarten R, Conner WC, Huber GW (2012) Production of levulinic acid from cellulose by hydrothermal decomposition combined with aqueous phase dehydration with a solid acid catalyst. Energy Environ Sci 5: 7559–7571. doi: 10.1039/c2ee21593d
|
| [67] |
Wettstein SG, Alonso DM, Chong Y, et al. (2012) Production of levulinic acid and gamma-valerolactone (GVL) from cellulose using GVL as a solvent in biphasic systems. Energy Environ Sci 5: 8199–8204. doi: 10.1039/c2ee22111j
|
| [68] |
Dutta S, Wu L, Mascal M (2015) Efficient, metal-free production of succinic acid by oxidation of biomass-derived levulinic acid with hydrogen peroxide. Green Chem 17: 2335–2338. doi: 10.1039/C5GC00098J
|
| [69] |
Zhang D, Hillmyer MA, Tolman WB (2004) A new synthetic route to Poly[3-hydroxypropionic acid] (P[3-HP]): Ring-Opening polymerization of 3-HP macrocyclic esters. Macromolecules 37: 8198–8200. doi: 10.1021/ma048092q
|
| [70] |
Song H, Lee SY (2006) Production of succinic acid by bacterial fermentation. Enzyme Microb Technol 39: 352–361. doi: 10.1016/j.enzmictec.2005.11.043
|
| [71] |
Beauprez JJ, De Mey M, Soetaert WK, et al. (2010) Microbial succinic acid production: natural versus metabolic engineered producers. Process Biochem 45: 1103–1114. doi: 10.1016/j.procbio.2010.03.035
|
| [72] |
Cao Y, Cao Y, Lin X (2011) Metabolicallyengineered escherichia coli forbiotechnological production offour-carbon 1,4-dicarboxylic acids. J Ind Microbiol Biotechnol 38: 649–656. doi: 10.1007/s10295-010-0913-4
|
| [73] |
Kumar V, Ashok S, Park S (2013) Recent advances in biological production of 3-hydroxypropionic acid. Biotechnol Adv 31: 945–961.. doi: 10.1016/j.biotechadv.2013.02.008
|
| [74] |
Li J, Zheng XY, Fang XJ, et al. (2011) A complete industrial system for economical succinic acid production by Actinobacillus succinogenes. Bioresour Technol 102: 6147–6152. doi: 10.1016/j.biortech.2011.02.093
|
| [75] |
Ten Brink GJ, Arends IWCE, Sheldon RA (2004) The Baeyer−Villiger reaction: New developments toward greener procedures. Chem Rev 104: 4105–4124. doi: 10.1021/cr030011l
|
| [76] |
Cok B, Tsiropoulos I, Roes AL, et al. (2014) Succinic acid production derived from carbohydrates: An energy and greenhouse gas assessment of a platform chemical toward a bio-based economy. Biofuels, Bioprod Biorefin 8: 16–29. doi: 10.1002/bbb.1427
|
| [77] |
Deng W, Zhang Q, Wang Y (2014) Catalytic transformations of cellulose and cellulose derived carbohydrates into organic acids. Catal Today 234: 31–41. doi: 10.1016/j.cattod.2013.12.041
|
| [78] |
Kobayashi H, Fukuoka A (2013) Synthesis and utilisation of sugar compounds derived from lignocellulosic biomass. Green Chem 15: 1740–1764.. doi: 10.1039/c3gc00060e
|
| [79] | Nemoto K, Tominaga K, Sato K (2015) Facile and efficient transformation of lignocellulose into levulinic acid using an AlCl3.6H2O/H3PO4 hybrid acid catalyst. Bull Chem Soc Jpn 88: 1752–1754. |
| [80] |
Nemoto K, Tominaga K, Sato K (2014) Straightforward synthesis of levulinic acid ester from lignocellulosic biomass resources. Chem Lett 43: 1327–1329. doi: 10.1246/cl.140382
|
| [81] |
Tominaga K, Mori A, Fukushima Y, et al. (2011) Mixed-acid systems for the catalytic synthesis of methyl levulinate from cellulose. Green Chem 13: 810–813. doi: 10.1039/c0gc00715c
|
| [82] |
Galletti AMR, Antonetti C, De Luise V, et al. (2012) A sustainable process for the production of γ-valerolactone by hydrogenation of biomass-derived levulinic acid. Green Chem 14: 688–695. doi: 10.1039/c2gc15872h
|
| [83] |
Joshi SS, Zodge AD, Pandare KV, et al. (2014) Efficient conversion of cellulose to levulinic acid by hydrothermal treatment using zirconium dioxide as a recyclable solid acid catalyst. Ind Eng Chem Res 53: 18796–18805. doi: 10.1021/ie5011838
|
| [84] |
Tuteja J, Choudhary H, Nishimura S, et al. (2014) Direct synthesis of 1,6-Hexanediol from HMF over a heterogeneous Pd/ZrP catalyst using formic acid as hydrogen source. ChemSusChem 7: 96–100. doi: 10.1002/cssc.201300832
|
| [85] |
McKinlay JB, Vielle C, Zeikus JG (2007) Prospects for a bio-based succinate industry. Appl Microbiol Biotechnol 76: 727–740. doi: 10.1007/s00253-007-1057-y
|
| [86] |
Bechthold I, Bretz K, Kabasci S, et al. (2008) Succinic Acid: A new platform chemical for biobased polymers from renewable resources. Chem Eng Technol 31: 647–654. doi: 10.1002/ceat.200800063
|
| [87] | Mitschka R, Oehldrich J, Takahashi K, et al. (1981) General approach for the synthesis of polyquinanes. Facile generation of molecular complexity via reaction of 1,2-dicarbonyl compounds with dimethyl 3-. Tetrahedron 37: 4521–4542. |
| [88] |
Kawasumi R, Narita S, Miyamoto K, et al. (2017) One-step conversion of levulinic acid to succinic acid using I2/t-BuOK system: The iodoform reaction revisited. Scientific Reports 7: 1–8. doi: 10.1038/s41598-016-0028-x
|
| [89] |
Podolean I, Kuncser V, Gheorghe N, et al. (2013) Ru-based magnetic nanoparticles (MNP) for succinic acid synthesis from levulinic acid. Green Chem 15: 3077–3083. doi: 10.1039/c3gc41120f
|
| [90] | Pandey SK, Yadav SPS, Prasad M, et al. (1999) Mechanism of Ru(III) catalysis in oxidation of levulinic acid. Asian J Chem11: 203–206. |
| [91] |
Caretto A, Perosa A (2013) Upgrading of levulinic acid with dimethylcarbonate as solvent/reagent. ACS Sustainable Chem Eng 1: 989–994. doi: 10.1021/sc400067s
|
| [92] |
Besson M, Gallezot P, Pinel C (2014) Conversion of biomass into chemicals over metal catalysts. Chem Rev 114: 1827–1870. doi: 10.1021/cr4002269
|
| [93] |
Stoute VA, Winnik MA, Csizmadia IG (1974) Theoretical model for the Baeyer-Villiger rearrangement. J Am Chem Soc 96: 6388–6393. doi: 10.1021/ja00827a023
|
| [94] |
Wang M, Ma J, Liu H, et al. (2018) Sustainable productions of organic acids and their derivatives from biomass via selective oxidative cleavage of C–C Bond. ACS Catal 8: 2129–2165. doi: 10.1021/acscatal.7b03790
|
| [95] |
Van de Vyver S, Thomas J, Geboers J, et al. (2011) Catalytic production of levulinic acid from cellulose and other biomass-derived carbohydrates with sulfonated hyperbranched poly(arylene oxindole)s. Energy Environ Sci 4: 3601–3610. doi: 10.1039/c1ee01418h
|
| [96] |
Kong X, Wu S, Li X, et al. (2016) Efficient conversion of levulinic acid to ethyl levulinate over a silicotungstic-Acid-Modified commercially Silical-Gel sphere catalyst. Energy Fuels 30: 6500–6504. doi: 10.1021/acs.energyfuels.6b01207
|
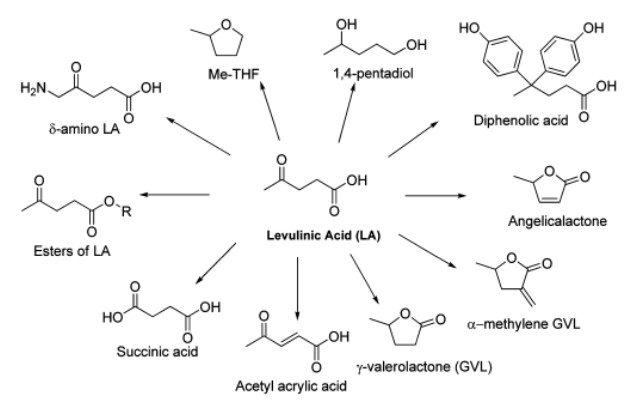
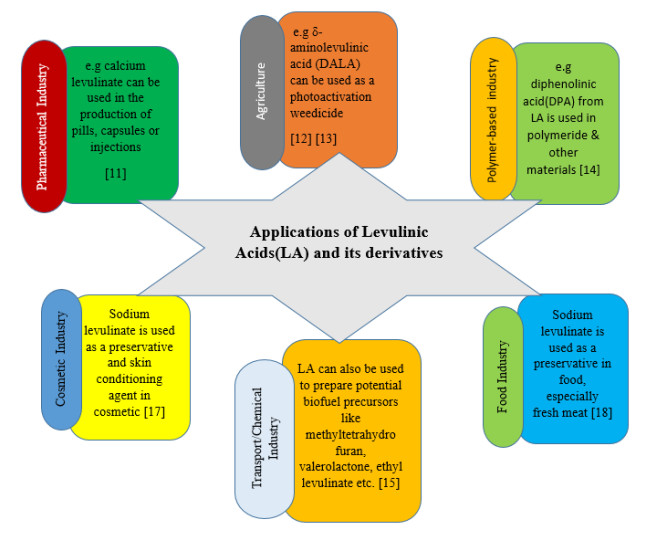
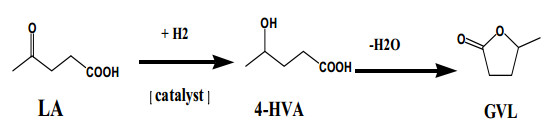
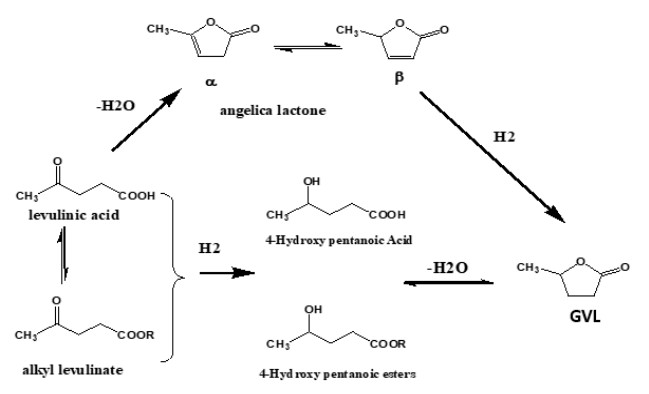
Figures(12)

Aderemi T. Adeleye, Hitler Louis, Ozioma U. Akakuru, Innocent Joseph, Obieze C. Enudi, Dass P. Michael. A Review on the conversion of levulinic acid and its esters to various useful chemicals[J]. AIMS Energy, 2019, 7(2): 165-185. doi: 10.3934/energy.2019.2.165







 DownLoad:
DownLoad: