Citation: Thomas Bintsis. Lactic acid bacteria as starter cultures: An update in their metabolism and genetics[J]. AIMS Microbiology, 2018, 4(4): 665-684. doi: 10.3934/microbiol.2018.4.665

| [1] | Bintsis T (2018) Lactic acid bacteria: their applications in foods. J Bacteriol Mycol 5: 1065. |
| [2] | Hayek SA, Ibrahim SA (2013) Current limitations and challenges with lactic acid bacteria: a review. Food Nutr Sci 4: 73–87. |
| [3] | Khalid K (2011) An overview of lactic acid bacteria. Int J Biosci 1: 1–13. |
| [4] | Bintsis T, Athanasoulas A (2015) Dairy starter cultures, In: Papademas P, Editor, Dairy Microbiology, A Practical Approach, Boca Raton: CRC Press, 114–154. |
| [5] | Von Wright A, Axelsson L (2011) Lactic acid bacteria: An introduction, In: Lahtinne S, Salminen S, Von Wright A, et al., Editors, Lactic Acid Bacteria: Microbiological and Functional Aspects, London: CRC Press, 1–17. |
| [6] | Sheehan JJ (2007) What are starters and what starter types are used for cheesemaking? In: McSweeney PLH, Editor, Cheese problems solved, Boca Raton: Woodhead Publishing Ltd., 36–37. |
| [7] | Tamime AY (2002) Microbiology of starter cultures, In: Robinson RK, Editor, Dairy Microbiology Handbook, 3 Eds., New York: John Wiley & Sons Inc., 261–366. |
| [8] | Parente E, Cogan TM (2004) Starter cultures: General aspects, In: Fox PF, McSweeney PLH, Cogan TM, et al., Cheese: Chemistry, Physics and Microbiology, 4 Eds., London: Elsevier Academic Press, 23–147. |
| [9] | Bourdichon F, Boyaval P, Casaregola J, et al. (2012) The 2012 Inventory of Microbial Species with technological beneficial role in fermented food products. B Int Dairy Fed 455: 22–61. |
| [10] | Bourdichon F, Berger B, Casaregola S, et al. (2012) A safety assessment of microbial food cultures with history of use in fermented dairy products. B Int Dairy Fed 455: 2–12. |
| [11] | Ricci A, Allende A, Bolton D, et al. (2017) Scientific Opinion on the update of the list of QPS-recommended biological agents intentionally added to food or feed as notified to EFSA. EFSA J 15: 4664. |
| [12] | Beresford T, Cogan T (1997) Improving Cheddar cheese flavor, In: Proceedings of the 5th Cheese Symposium, Cork: Teagasc/University College Cork, 53–61. |
| [13] | Picon A (2018) Cheese Microbial Ecology and Safety, In: Papademas P, Bintsis T, Editors, Global Cheesemaking Technology, Cheese Quality and Characteristics, Chichester: John Wiley & Sons Ltd., 71–99. |
| [14] | Wedajo B (2015) Lactic acid bacteria: benefits, selection criteria and probiotic potential in fermented food. J Prob Health 3: 129. |
| [15] |
Grattepanche F, Miescher-Schwenninger S, Meile L, et al. (2008) Recent developments in cheese cultures with protective and probiotic functionalities. Dairy Sci Technol 88: 421–444. doi: 10.1051/dst:2008013

|
| [16] | Law BA (1999) Cheese ripening and cheese flavour technology, In: Law BA, Editor, Technology of Cheesemaking, Sheffield: Sheffield Academic Press Ltd., 163–192. |
| [17] |
Smit G, Smit BA, Engels WJ (2005) Flavour formation by lactic acid bacteria and biochemical flavour profiling of cheese products. FEMS Microbiol Rev 29: 591–610. doi: 10.1016/j.fmrre.2005.04.002
|
| [18] | Tamime AY, Robinson RK (1999) Yoghurt Science and Technology, 2 Eds., Cambridge: Woodhead Publishing Ltd. |
| [19] | Ammor MS, Mayo B (2006) Selection criteria for lactic acid bacteria to be used as functional starter cultures in dry sausage production: An update. Meat Sci 76: 138–146. |
| [20] | Souza MJ, Ardo Y, McSweeney PLH (2001) Advances in the study of proteolysis in cheese. Int Dairy J 11: 327–345. |
| [21] |
Martinez FAC, Balciunas EM, Salgado JM, et al. (2013) Lactic acid properties, applications and production: A review. Trends Food Sci Tech 30: 70–83. doi: 10.1016/j.tifs.2012.11.007
|
| [22] |
Burgos-Rubio CN, Okos MR, Wankat PC (2000) Kinetic study of the conversion of different substrates to lactic acid using Lactobacillus bulgaricus. Biotechnol Progr 16: 305–314. doi: 10.1021/bp000022p
|
| [23] |
Hofvendahl K, Hahn-Hägerda B (2000) Factors affecting the fermentative lactic acid production from renewable resources. Enzyme Microb Tech 26: 87–107. doi: 10.1016/S0141-0229(99)00155-6
|
| [24] | Crow VL, Davey GP, Pearce LE, et al. (1983) Plasmid linkage of the D-tagatose 6-phosphate pathway in Streptococcus lactis: Effect on lactose and galactose metabolism. J Bacteriol 153: 76–83. |
| [25] |
Hugenholtz J (1993) Citrate metabolism in lactic acid bacteria. FEMS Microbiol Rev 12: 165–178. doi: 10.1111/j.1574-6976.1993.tb00017.x
|
| [26] |
McFeeters RF, Fleming HP, Thompson RL (1982) Malic acid as a source of carbon dioxide in cucumber fermentations. J Food Sci 47: 1862–1865. doi: 10.1111/j.1365-2621.1982.tb12900.x
|
| [27] | Daeschel MA, McFeeters RF, Fleming HP, et al. (1984) Mutation and selection of Lactobacillus plantarum strains that do not produce carbon dioxide from malate. Appl Environ Microb 47: 419–420. |
| [28] | Li KY (2004) Fermentation: Principles and Microorganisms, In: Hui YH, Meunier-Goddik L, Hansen LM, et al., Editors, Handbook of Food and Beverage Fermentation Technology, New York: Marcel Dekker Inc., 594–608. |
| [29] |
Chopin A (1993) Organization and regulation of genes for amino acid biosynthesis in lactic acid bacteria. FEMS Microbiol Rev 12: 21–38. doi: 10.1111/j.1574-6976.1993.tb00011.x
|
| [30] |
Kunji ERS, Mierau I, Hagting A, et al. (1996) The proteolytic system of lactic acid bacteria. Anton Leeuw 70: 187–221. doi: 10.1007/BF00395933
|
| [31] | Upadhyay VK, McSweeney PLH, Magboul AAA, et al. (2004) Proteolysis in Cheese during Ripening, In: Fox PF, McSweeney PLH, Cogan TM, et al., Editors, Cheese: Chemistry, Physics and Microbiology, 4 Eds., London: Elsevier Academic Press, 391–433. |
| [32] | Curtin AC, McSweeney PLH (2004) Catabolism of Amino Acids in Cheese during Ripening, In: Fox PF, McSweeney PLH, Cogan TM, et al., Editors, Cheese: Chemistry, Physics and Microbiology, 4 Eds., London: Elsevier Academic Press, 435–454. |
| [33] |
Christensen JE, Dudley EG, Pederson JA, et al. (1999) Peptidases and amino acid catabolism in lactic acid bacteria. Anton Leeuw 76: 217–246. doi: 10.1023/A:1002001919720
|
| [34] | Fox PF, Wallace JM (1997) Formation of flavour compounds in cheese. Adv Appl Microbiol 45: 17–85. |
| [35] |
Khalid NM, Marth EM (1990) Lactobacilli-their enzymes and role in ripening and spoilage of cheese: A review. J Dairy Sci 73: 2669–2684. doi: 10.3168/jds.S0022-0302(90)78952-7
|
| [36] |
Bintsis T, Robinson RK (2004) A study of the effects of adjunct cultures on the aroma compounds of Feta-type cheese. Food Chem 88: 435–441. doi: 10.1016/j.foodchem.2004.01.057
|
| [37] |
Broadbent JR, McMahon DJ, Welker DL, et al. (2003) Biochemistry, genetics, and applications of exopolysaccharide production in Streptococcus thermophilus: A review. J Dairy Sci 86: 407–423. doi: 10.3168/jds.S0022-0302(03)73619-4
|
| [38] | Callanan MJ, Ross RP (2004) Starter Cultures: Genetics, In: Fox PF, McSweeney PLH, Cogan TM, et al., Editors, Cheese: Chemistry, Physics and Microbiology, 4 Eds., London: Elsevier Academic Press, 149–161. |
| [39] |
Klaenhammer T, Altermann E, Arigoni F, et al. (2002) Discovering lactic acid bacteria by genomics. Anton Leeuw 82: 29–58. doi: 10.1023/A:1020638309912
|
| [40] | Morelli L, Vogensen FK, Von Wright A (2011) Genetics of Lactic Acid Bacteria, In: Salminen S, Von Wright A, Ouwehand A, Editors, Lactic Acid Bacteria-Microbiological and Functional Aspects, 3 Eds., New York: Marcel Dekker Inc., 249–293. |
| [41] |
Mills S, O'Sullivan O, Hill C, et al. (2010) The changing face of dairy starter culture research: From genomics to economics. Int J Dairy Tech 63: 149–170. doi: 10.1111/j.1471-0307.2010.00563.x
|
| [42] | NCBI, Data collected from Genbank, 2018. Available from: https://www.ncbi.nlm.nih.gov/genome/browse/. |
| [43] | Oliveira AP, Nielsen J, Förster J (2005) Modeling Lactococcus lactis using a genome-scale flux model. BMC Microbiol 55: 39. |
| [44] | Salama M, Sandine WE, Giovannoni S (1991) Development and application of oligonucleotide probes for identification of Lactococcus lactis subsp. cremoris. Appl Environ Microb 57: 1313–1318. |
| [45] | McKay LL (1985) Roles of plasmids in starter cultures, In: Gilliland SE, Editor, Bacterial Starter Cultures for Food, Boca Raton: CRC Press, 159–174. |
| [46] |
Davidson B, Kordis N, Dobos M, et al. (1996) Genomic organization of lactic acid bacteria. Anton Leeuw 70: 161–183. doi: 10.1007/BF00395932
|
| [47] |
Dunny G, McKay LL (1999) Group II introns and expression of conjugative transfer functions in lactic acid bacteria. Anton Leeuw 76: 77–88. doi: 10.1023/A:1002085605743
|
| [48] | Hughes D (2000) Evaluating genome dynamics: The constraints on rearrangements within bacterial genomes. Genome Biol 1: 1–8. |
| [49] |
Hols P, Kleerebezem M, Schanck AN, et al. (1999) Conversion of Lactococcus lactis from homolactic to homoalanine fermentation through metabolic engineering. Nat Biotechnol 17: 588–592. doi: 10.1038/9902
|
| [50] |
Bolotin A, Quinquis B, Renault P, et al. (2004) Complete sequence and comparative genome analysis of the dairy bacterium Streptococcus thermophilus. Nat Biotechnol 22: 1554–1558. doi: 10.1038/nbt1034
|
| [51] |
Pastink MI, Teusink B, Hols P, et al. (2009) Genome-scale model of Streptococcus thermophilus LMG18311 for metabolic comparison of lactic acid bacteria. Appl Environ Microb 75: 3627–3633. doi: 10.1128/AEM.00138-09
|
| [52] |
Madera C, Garcia P, Janzen T, et al. (2003) Characterization of technologically proficient wild Lactococcus lactis strains resistant to phage infection. Int J Food Microbiol 86: 213–222. doi: 10.1016/S0168-1605(03)00042-4
|
| [53] |
Turgeon N, Frenette M, Moineau S (2004) Characterization of a theta-replicating plasmid from Streptococcus thermophilus. Plasmid 51: 24–36. doi: 10.1016/j.plasmid.2003.09.004
|
| [54] | Hols P, Hancy F, Fontaine L, et al. (2005) New insights in the molecular biology and physiology of Streptococcus thermophilus revealed by comparative genomics. FEMS Microbiol Rev 29: 435–463. |
| [55] | O'Sullivan DJ (1999) Methods for analysis of the intestinal microflora, In: Tannock GW, Editor, Probiotics: A critical review, Norfolk: Horizon Scientific Press. |
| [56] | Solow BT, Somkuti GA (2000) Molecular properties of Streptococcus thermophilus plasmid pER35 encoding a restriction modification system. Curr Microbiol 42: 122–128. |
| [57] |
El Demerdash HAM, Oxmann J, Heller KJ, et al. (2006) Yoghurt fermentation at elevated temperatures by strains of Streptococcus thermophilus expressing a small heat-shock protein: Application of a two-plasmid system for constructing food-grade strains of Streptococcus thermophilus. Biotechnol J 1: 398–404. doi: 10.1002/biot.200600018
|
| [58] |
Chevallier B, Hubert JC, Kammerer B (1994) Determination of chromosome size and number of rrn loci in Lactobacillus plantarum by pulsed-field gel electrophoresis. FEMS Microbiol Lett 120: 51–56. doi: 10.1111/j.1574-6968.1994.tb07006.x
|
| [59] |
Daniel P (1995) Sizing the Lactobacillus plantarum genome and other lactic bacteria species by transverse alternating field electrophoresis. Curr Microbiol 30: 243–246. doi: 10.1007/BF00293640
|
| [60] |
Oliveira PM, Zannini E, Arendt EK (2014) Cereal fungal infection, mycotoxins, and lactic acid bacteria mediated bioprotection: From crop farming to cereal products. Food Microbiol 37: 78–95. doi: 10.1016/j.fm.2013.06.003
|
| [61] |
Johnson JL, Phelps CF, Cummins CS, et al. (1980) Taxonomy of the Lactobacillus acidophilus group. Int J Syst Bacteriol 30: 53–68. doi: 10.1099/00207713-30-1-53
|
| [62] | Fujisawa T, Benno Y, Yaeshima T, et al. (1992) Taxonomic study of the Lactobacillus acidophilus group, with recognition of Lactobacillus gallinarum sp. nov. and Lactobacillus johnsonii sp. nov. and synonymy of Lactobacillus acidophilus group A3 with the type strain of Lactobacillus amylovorus. Int J Syst Bacteriol 42: 487–491. |
| [63] |
Link-Amster H, Rochat F, Saudan KY, et al. (1994) Modulation of a specific humoral immune response and changes in intestinal flora mediated through fermented milk intake. FEMS Immunol Med Mic 10: 55–64. doi: 10.1111/j.1574-695X.1994.tb00011.x
|
| [64] |
Schiffrin EJ, Rochat F, Link-Amster H, et al. (1995) Immunomodulation of human blood cells following the ingestion of lactic acid bacteria. J Dairy Sci 78: 491–497. doi: 10.3168/jds.S0022-0302(95)76659-0
|
| [65] | Bernet-Camard MF, Liévin V, Brassart D, et al. (1997) The human Lactobacillus acidophilus strain La1 secretes a non bacteriocin antibacterial substance active in vitro and in vivo. Appl Environ Microb 63: 2747–2753. |
| [66] |
Felley CP, Corthésy-Theulaz I, Rivero JL, et al. (2001) Favourable effect of an acidified milk (LC-1) on Helicobacter pylori gastritis in man. Eur J Gastroenterol Hepatol 13: 25–29. doi: 10.1097/00042737-200101000-00005
|
| [67] | Pérez PF, Minnaard J, Rouvet M, et al. (2001) Inhibition ofGiardia intestinalisby extracellularfactors from lactobacilli: An in vitro study. Appl Environ Microb 67: 5037–5042. |
| [68] | Schleifer KH, Ludwig W (1995) Phylogenetic relationships of lactic acid bacteria, In: Wood BJB, Holzapfel WH, Editors, The Genera of Lactic Acid Bacteria, London: Chapman & Hall, 7–18. |
| [69] | Hassan AN, Frank JF (2001) Starter cultures and their use, In: Marth EH, Steele JL, Editors, Applied Dairy Microbiology, 2 Eds., New York: Marcel Dekker Inc., 151–206. |
| [70] | Hammes WP, Vogel RF (1995) The genus Lactobacillus, In: Wood BJB, Holzapfel WH, Editors, The Genera of Lactic Acid Bacteria, London: Blackie Academic and Professional, 19–54. |
| [71] |
Park JS, Shin E, Hong H, et al. (2015) Characterization of Lactobacillus fermentum PL9988 isolated from healthy elderly Korean in a longevity village. J Microbiol Biotechnol 25: 1510–1518. doi: 10.4014/jmb.1505.05015
|
| [72] | Simpson WJ, Taguchi H (1995) The genus Pediococcus, with notes on the genera Tetratogenococcus and Aerococcus, In: Wood BJB, Holzapfel WH, Editors, The Genera of Lactic Acid Bacteria, London: Chapman & Hall, 125–172. |
| [73] |
Beresford TP, Fitzsimons NA, Brennan NL, et al. (2001) Recent advances in cheese microbiology. Int Dairy J 11: 259–274. doi: 10.1016/S0958-6946(01)00056-5
|
| [74] | Caldwell S, McMahon DL, Oberg CL, et al. (1996) Development and characterization of lactose-positive Pediococcus species for milk fermentation. Appl Environ Microb 62: 936–941. |
| [75] |
Caldwell S, Hutkins RW, McMahon DJ, et al. (1998) Lactose and galactose uptake by genetically engineered Pediococcus species. Appl Microbiol Biot 49: 315–320. doi: 10.1007/s002530051175
|
| [76] | Graham DC, McKay LL (1985) Plasmid DNA in strains of Pediococcus cerevisiae and Pediococcus pentosaceus. Appl Environ Microb 50: 532–534. |
| [77] | Daeschel MA, Klaenhammer TR (1985) Association of a 13.6-megadalton plasmid in Pediococcus pentosaceus with bacteriocin activity. Appl Environ Microb 50: 1528–1541. |
| [78] | Gonzalez CF, Kunka BS (1986) Evidence for plasmid linkage of raffinose utilization and associated α-galactosidase and sucrose hydrolase activity in Pediococcus pentosaceus. Appl Environ Microb 51: 105–109. |
| [79] | De Roos J, De Vuyst L (2018) Microbial acidification, alcoholization, and aroma production during spontaneous limbic beer production. J Sci Food Agr 99: 25–38. |
| [80] |
Sakamoto K, Margolles A, van Veen HW, et al. (2001) Hop resistance in the beer spoilage bacterium Lactobacillus brevis is mediated by the ATP-binding cassette multidrug transporter HorA. J Bacteriol 183: 5371–5375. doi: 10.1128/JB.183.18.5371-5375.2001
|
| [81] |
Snauwaert I, Stragier P, De Vuyst L, et al. (2015) Comparative genome analysis of Pediococcus damnosus LMG 28219, a strain well-adapted to the beer environment. BMC Genomics 16: 267. doi: 10.1186/s12864-015-1438-z
|
| [82] |
Suzuki K, Ozaki K, Yamashita H (2004) Comparative analysis of conserved genetic markers and adjacent DNA regions identified in beer spoilage lactic acid bacteria. Lett Appl Microbiol 39: 240–245. doi: 10.1111/j.1472-765X.2004.01572.x
|
| [83] | Bergsveinson J, Friesen V, Ziola B (2017) Transcriptome analysis of beer-spoiling Lactobacillus brevis BSO 464 during growth in degassed and gassed beer. Int J Food Microbiol 235: 28–35. |
| [84] | Garvie EI (1986) Genus Leuconostoc, In: Sneath PHA, Mair NS, Sharpe ME, et al., Editors, Bergey's Manual of Systematic Bacteriology, 9 Eds., Baltimore: Williams and Wilkins, 1071–1075. |
| [85] | Cogan TM, O'Dowd M, Mellerick D (1981) Effects of sugar on acetoin production from citrate by Leuconostoc lactis. Appl Environ Microb 41: 1–8. |
| [86] |
Klare I, Werner G, Witte W (2001) Enterococci: Habitats, infections, virulence factors, resistances to antibiotics, transfer of resistance determinants. Contrib Microbiol 8: 108–122. doi: 10.1159/000060406
|
| [87] |
Endtz HP, van den Braak N, Verbrugh HA, et al. (1999) Vancomycin resistance: Status quo and quo vadis. Eur J Clin Microbiol 18: 683–690. doi: 10.1007/s100960050379
|
| [88] |
Moreno MRF, Sarantinopoulos P, Tsakalidou E, et al. (2006) The role and application of enterococci in food and health. Int J Food Microbiol 106: 1–24. doi: 10.1016/j.ijfoodmicro.2005.06.026
|
| [89] |
Cappello MS, Zapparoli G, Logrieco A, et al. (2017) Linking wine lactic acid bacteria diversity with wine aroma and flavor. Int J Food Microbiol 243: 16–27. doi: 10.1016/j.ijfoodmicro.2016.11.025
|
| [90] |
Hugenholtz J (2008) The lactic acid bacterium as a cell factory for food ingredient production. Int Dairy J 18: 466–475. doi: 10.1016/j.idairyj.2007.11.015
|
| [91] | Hugenholtz J, Kleerebezem M, Starrenburg M, et al. (2000) Lactococcus lactis as a cell-factory for high level diacetyl production. Appl Environ Microb 66: 4112–4114. |
| [92] |
Hugenholtz J, Smid EJ (2002) Neutraceutical production with food-grade microorganisms. Curr Opin Biotech 13: 497–507. doi: 10.1016/S0958-1669(02)00367-1
|
| [93] |
Hugenholtz J, Sybesma W, Groot MN, et al. (2002) Metabolic engineering of lactic acid bacteria for the production of nutraceuticals. Anton Leeuw 82: 217–235. doi: 10.1023/A:1020608304886
|
| [94] |
Hols P, Kleerebezem M, Schranck AN, et al. (1999) Conversion of Lactococcus lactis from homolactic to homoalanine fermentation through metabolic engineering. Nat Biotechnol 17: 588–592. doi: 10.1038/9902
|
| [95] | Börner RA, Kandasamy V, Axelsen AM, et al. (2018) High-throughput genome editing tools for lactic acid bacteria: Opportunities for food, feed, pharma and biotech. Available from: www.preprints.org. |
| [96] | Johansen E (2018) Use of natural selection and evolution to develop new starter cultures for fermented foods. Annu Rev Food Sci T 9: 411–428. |
| [97] | EC (2013) Regulation (EC) No 1829/2003 of the European Parliament and of the council on genetically modified food and feed. Off J Eur Union L 268: 1–23. |
| [98] |
Derkx PM, Janzen T, Sørensen KI, et al. (2014) The art of strain improvement of industrial lactic acid bacteria without the use of recombinant DNA technology. Microb Cell Fact 13: S5. doi: 10.1186/1475-2859-13-S1-S5
|
| [99] | Bachmann H, Pronk JT, Kleerebezem M, et al. (2015) Evolutionary engineering to enhance starter culture performance in food fermentations. Curr Opin Biotech 32: 1–7. |
| [100] |
Zeidan AA, Poulsen VK, Janzen T, et al. (2017) Polysaccharide production by lactic acid bacteria: From genes to industrial applications. FEMS Microbiol Rev 41: S168–S200. doi: 10.1093/femsre/fux017
|
| [101] |
De Angelis M, de Candia S, Calasso MP, et al. (2008) Selection and use of autochthonous multiple strain cultures for the manufacture of high-moisture traditional Mozzarella cheese. Int J Food Microbiol 125: 123–132. doi: 10.1016/j.ijfoodmicro.2008.03.043
|
| [102] |
Terzić-Vidojević A, Tonković K, Leboš A, et al. (2015) Evaluation of autochthonous lactic acid bacteria as starter cultures for production of white pickled and fresh soft cheeses. LWT-Food Sci Technol 63: 298–306. doi: 10.1016/j.lwt.2015.03.050
|
| [103] |
Frau F, Nuñez M, Gerez L, et al. (2016) Development of an autochthonous starter culture for spreadable goat cheese. Food Sci Technol 36: 622–630. doi: 10.1590/1678-457x.08616
|
| [104] |
Kargozari M, Moini S, Basti AA, et al. (2014) Effect of autochthonous starter cultures isolated from Siahmazgi cheese on physicochemical, microbiological and volatile compound profiles and sensorial attributes of sucuk, a Turkish dry-fermented sausage. Meat Sci 97: 104–114. doi: 10.1016/j.meatsci.2014.01.013
|
| [105] | Casquete R, Benito MJ, Martin A, et al. (2012) Use of autochthonous Pediococcus acidilactici and Staphylococcus vitulus starter cultures in the production of "Chorizo" in 2 different traditional industries. J Food Sci 77: 70–79. |
| [106] | Talon R, Leroy S, Lebert I, et al. (2008) Safety improvement and preservation of typical sensory qualities of traditional dry fermented sausages using autochthonous starter cultures. Int J Food Microbiol 126: 227–234. |
| [107] | EFSA (2008) Scientific opinion of the panel on biological hazards on the request from EFSA on the maintenance of the list of QPS microorganisms intentionally added to food or feed. EFSA J 928: 1–48. |
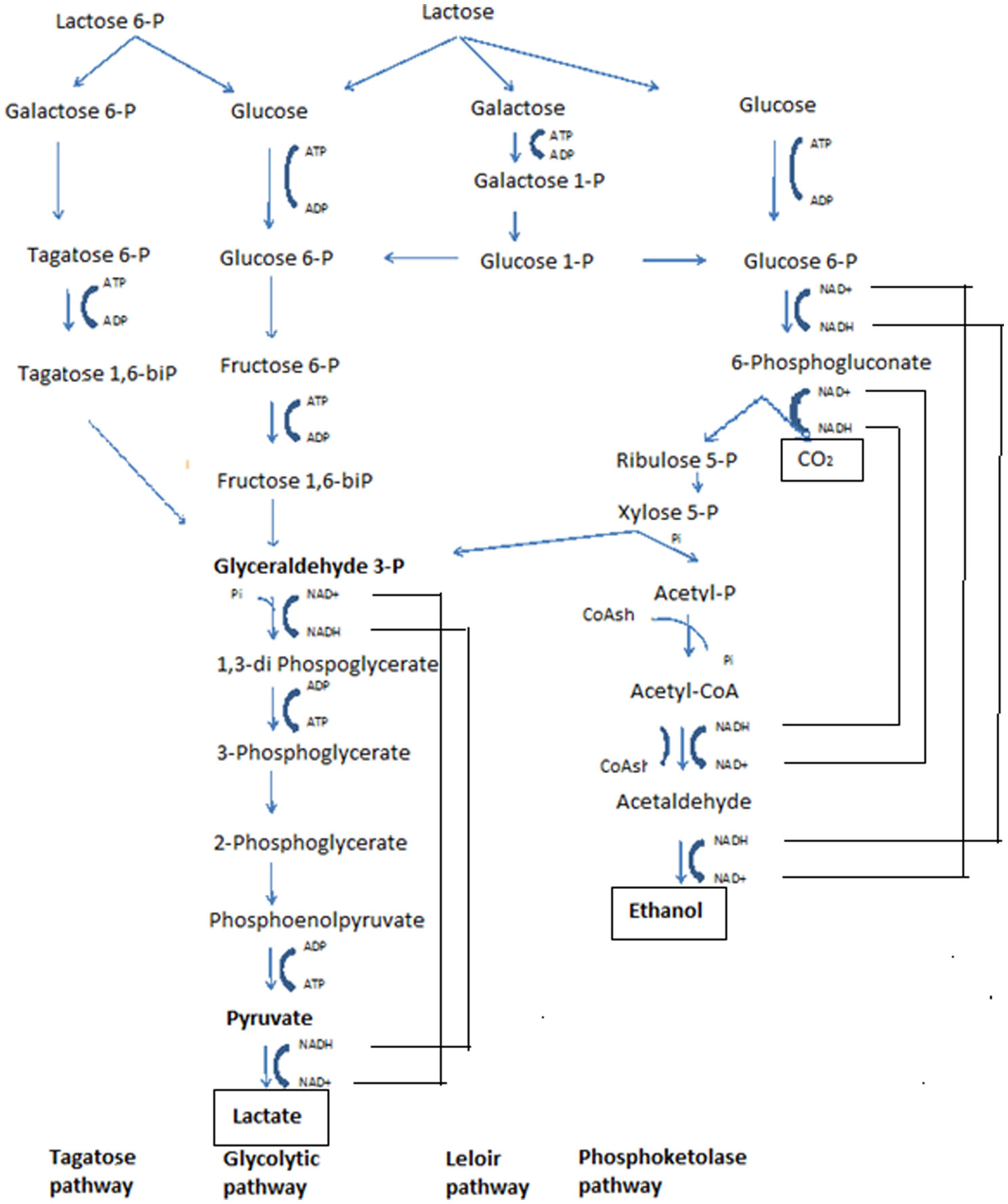
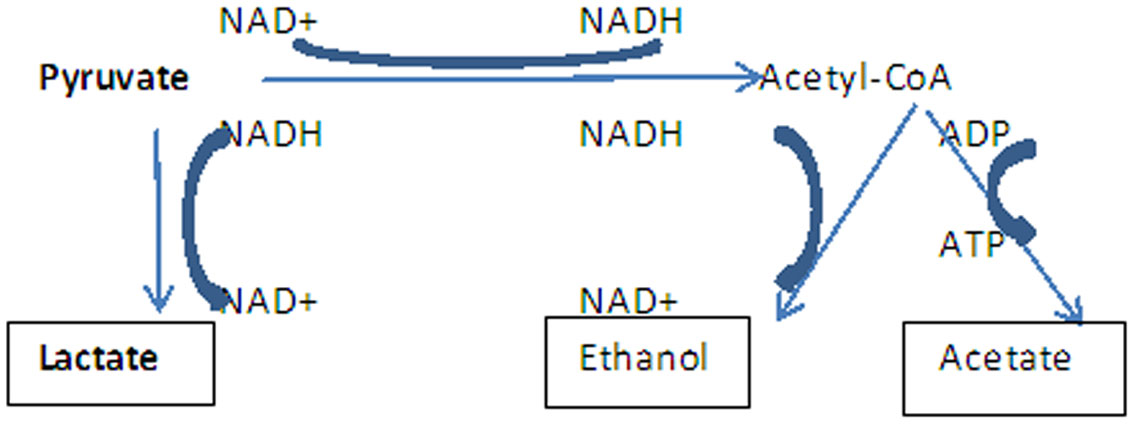
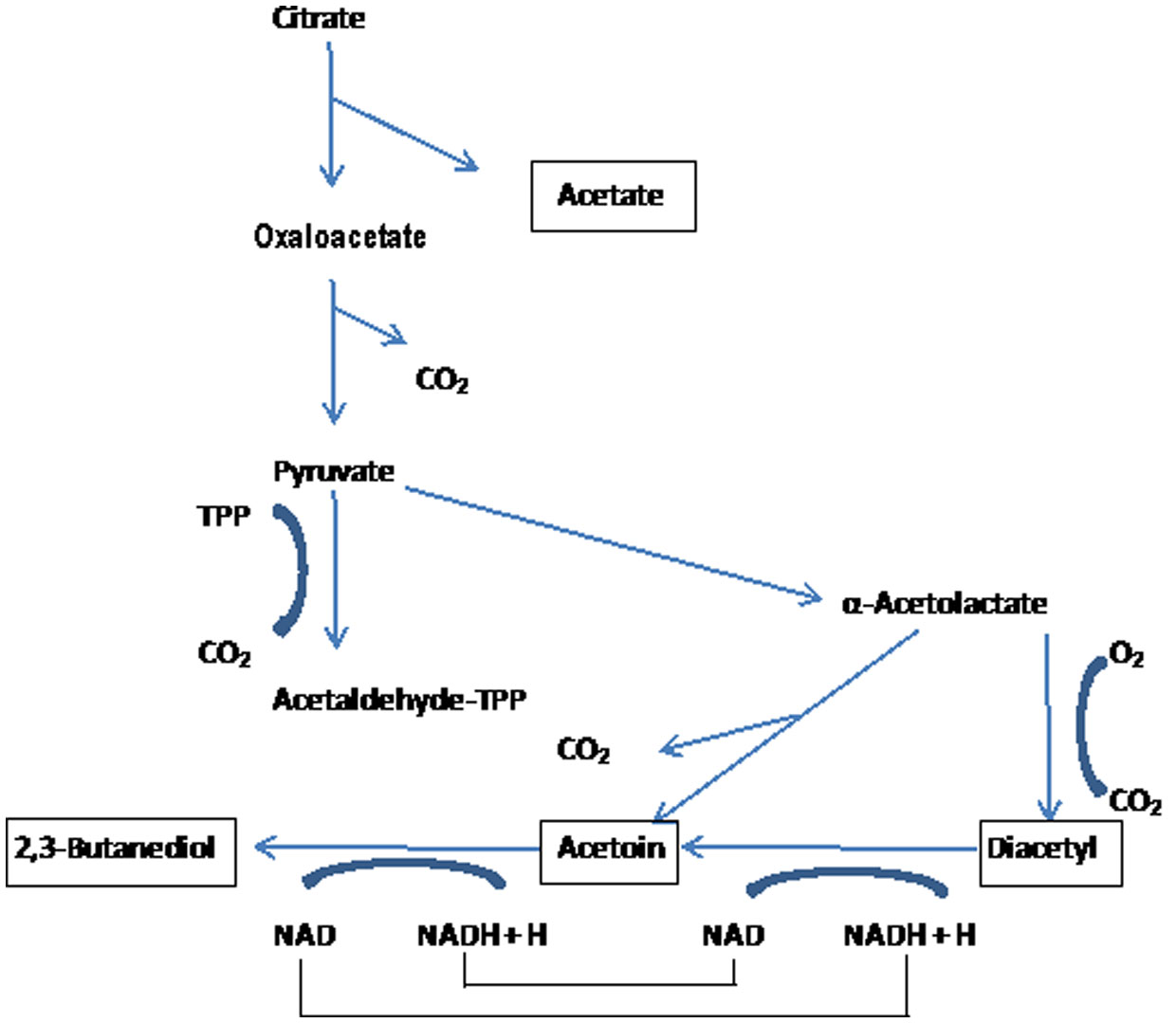
Figures(3)

Thomas Bintsis. Lactic acid bacteria as starter cultures: An update in their metabolism and genetics[J]. AIMS Microbiology, 2018, 4(4): 665-684. doi: 10.3934/microbiol.2018.4.665







 DownLoad:
DownLoad: