Citation: Marco Tosato, Jianhong Wu. An application of PART to the Football Manager data for players clusters analyses to inform club team formation[J]. Big Data and Information Analytics, 2018, 3(1): 43-54. doi: 10.3934/bdia.2018002

| [1] | [Financial Fair Play club summary - Official document, retrieved from www.uefa.com. |
| [2] | [ Guide to Football Manager, retrieved from www.guidetofm.com. |
| [3] | [ C. C. Aggarwal, J. L. Wolf, P. S. Yu, C. Procopiuc and J. S. Park, Fast algorithms for projected clustering, Proceedings of the 1999 ACM SIGMOD International Conference on Management of Data, ACM Press, (1999), 61-72. |
| [4] | [ R. Agrawal, J. Gehrke, D. Gunopulos and P. Raghavan, Automatic subspace clustering of high dimensional data for data mining applications, Proceedings of the 1998 ACM SIGMOD International Conference on Management of Data, ACM Press (1998), 94-105. |
| [5] | [J. Cao and J. Wu, Dynamics of projective adaptive resonance theory model: The foundation of PART algorithm, IEEE Transactions on Neural Networks, 2004. |
| [6] | [ J. Cao and J. Wu, Projective ART for clustering data sets in high dimensional spaces, Neural Networks, 2002. |
| [7] | [C. H. Cheng, A. W. Fu and Y. Zhang, Entropy-based subspace clustering for mining numerical data, Proceedings of the Fifth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, ACM Press (1999), 84-93. |
| [8] | [G. Gan, C. Ma and J. Wu, Data clustering: Theory, algorithms and applications, SIAM, Philadelphia, ASA, Alexandria, VA, (2007), xxii+466 pp. |
| [9] | [J. D. Hunter, J. Wu and J. Milton, Clustering neural spike trains with transient responses, Proceedings of the 47th IEEE Conference on Decision and Control, 2008. |
| [10] | [Director - L. Myles, An alternative reality: The football manager documentary, Sports Interactive, 2014. |
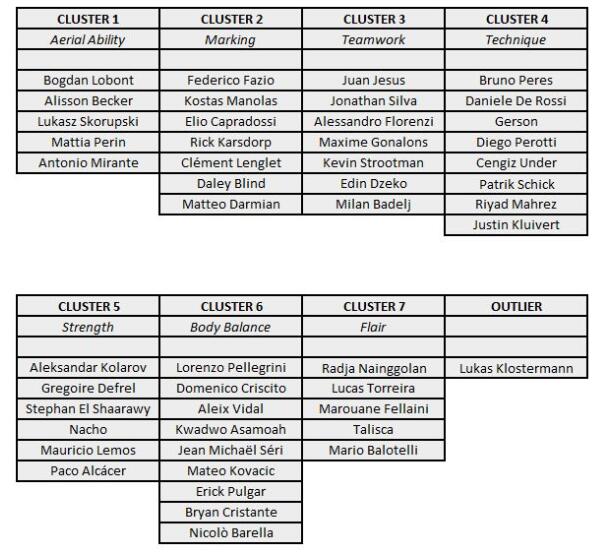
Figures(5)

Marco Tosato, Jianhong Wu. An application of PART to the Football Manager data for players clusters analyses to inform club team formation[J]. Big Data and Information Analytics, 2018, 3(1): 43-54. doi: 10.3934/bdia.2018002









 DownLoad:
DownLoad: