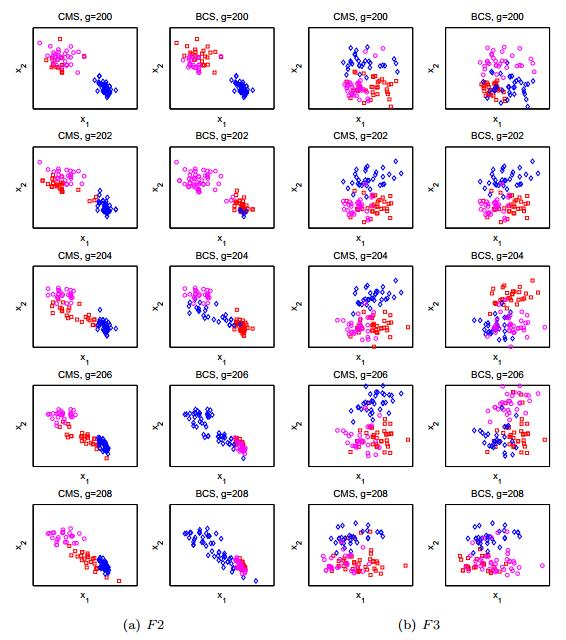
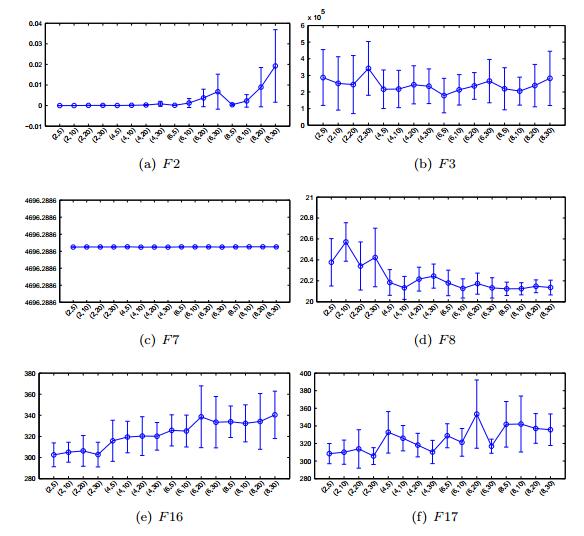
The mate selection plays a key role in natural evolution process. Although a variety of mating strategies have been proposed in the community of evolutionary computation, the importance of mate selection has been ignored. In this paper, we propose a clustering based mate selection (CMS) strategy for evolutionary algorithms (EAs). In CMS, the population is partitioned into clusters and only the solutions in the same cluster are chosen for offspring reproduction. Instead of doing a whole new clustering process in each EA generation, the clustering iteration process is combined with the evolution iteration process. The combination of clustering and evolving processes benefits EAs by saving the cost to discover the population structure. To demonstrate this idea, a CMS utilizing the k-means clustering method is proposed and applied to a state-of-the-art EA. The experimental results show that the CMS strategy is promising to improve the performance of the EA.
Citation: Jinyuan Zhang, Aimin Zhou, Guixu Zhang, Hu Zhang. 2017: A clustering based mate selection for evolutionary optimization, Big Data and Information Analytics, 2(1): 77-85. doi: 10.3934/bdia.2017010
The mate selection plays a key role in natural evolution process. Although a variety of mating strategies have been proposed in the community of evolutionary computation, the importance of mate selection has been ignored. In this paper, we propose a clustering based mate selection (CMS) strategy for evolutionary algorithms (EAs). In CMS, the population is partitioned into clusters and only the solutions in the same cluster are chosen for offspring reproduction. Instead of doing a whole new clustering process in each EA generation, the clustering iteration process is combined with the evolution iteration process. The combination of clustering and evolving processes benefits EAs by saving the cost to discover the population structure. To demonstrate this idea, a CMS utilizing the k-means clustering method is proposed and applied to a state-of-the-art EA. The experimental results show that the CMS strategy is promising to improve the performance of the EA.

| [1] | Back T., Fogel D.B., Michalewicz v, et al. (1997) Handbook of Evolutionary Computation Oxford University Press. |
| [2] | K. Deb and D. E. Goldberg, An investigation of niche and species formation in genetic function optimization, in Proceedings of the 3rd International Conference on Genetic Algorithms. Morgan Kaufmann Publishers Inc. , 1989, 42–50. |
| [3] | L. J. Eshelman and J. D. Schaffer, Preventing premature convergence in genetic algorithms by preventing incest, in International Conference on Genetic Algorithms, 1991,115–122. |
| [4] | Fernandes C.M., Rosa A.C. (2008) Evolutionary algorithms with dissortative mating on static and dynamic environments. Advances in Evolutionary Algorithms 181-206. |
| [5] | Galán S.F., Mengshoel O.J., Pinter R. (2013) A novel mating approach for genetic algorithms. Evolutionary Computation 21: 197-229. |
| [6] |
A. Gog, C. Chira, D. Dumitrescu and D. Zaharie, Analysis of some mating and collaboration strategies in evolutionary algorithms, in 10th International Symposium on Symbolic and Numeric Algorithms for Scientific Computing, IEEE, 2008,538–542. 10.1109/SYNASC.2008.87 |
| [7] | Goh K.S., Lim A., Rodrigues B. (2003) Sexual selection for genetic algorithms. Artificial Intelligence Review 19: 123-152. |
| [8] |
T. Hastie, R. Tibshirani and J. Friedman, The Elements of Statistical Learning: Data Mining, Inference, and Prediction Second edition. Springer Series in Statistics. Springer, New York, 2009. 10.1007/978-0-387-84858-7 MR2722294 |
| [9] |
Jin Y. (2011) Surrogate-assisted evolutionary computation: Recent advances and future challenges. Swarm and Evolutionary Computation 1: 61-70. doi: 10.1016/j.swevo.2011.05.001

|
| [10] |
P. Larranaga and J. A. Lozano, Estimation of Distribution Algorithms: A New Tool for Evolutionary Computation Kluwer Academic Publishers, 2002. 10.1007/978-1-4615-1539-5 |
| [11] |
J. B. MacQueen, Some methods for classification and analysis of multivariate observations, in Proceedings of 5th Berkeley Symposium on Mathematical Statistics and Probability, Ed. University of California Press, (1967), 281–297. MR0214227 |
| [12] |
G. Ochoa, C. Mädler-Kron, R. Rodriguez and K. Jaffe, Assortative mating in genetic algorithms for dynamic problems, in Applications of Evolutionary Computing, Springer, 2005,617–622. 10.1007/978-3-540-32003-6_65 |
| [13] | T. S. Quirino, Improving Search in Genetic Algorithms Through Instinct-Based Mating Strategies Ph. D. dissertation, The University of Miami, 2012. |
| [14] |
Quirino T., Kubat M., Bryan N.J. (2010) Instinct-based mating in genetic algorithms applied to the tuning of 1-nn classifiers. IEEE Transactions on Knowledge and Data Engineering 22: 1724-1737. doi: 10.1109/TKDE.2009.211
|
| [15] | J. Sanchez-Velazco and J. A. Bullinaria, Sexual selection with competitive/co-operative operators for genetic algorithms, in Neural Networks and Computational Intelligence(NCI). ACTA Press, 2003,191–196. |
| [16] | Sivaraj R., Ravichandran T. (2011) A review of selection methods in genetic algorithm. International Journal of Engineering Science and Technology (IJEST) 3: 3792-3797. |
| [17] | P. N. Suganthan, N. Hansen, J. J. Liang, K. Deb, Y. P. Chen, A. Auger and S. Tiwari, Problem Definitions and Evaluation Criteria for the cec 2005 Special Session on Real-Parameter Optimization Tech. rep. , Nanyang Technological University, Singapore and Kanpur Genetic Algorithms 369 Laboratory, IIT Kanpur, 2005. |
| [18] |
Ting C.-K., Li S.-T., Lee C. (2003) On the harmonious mating strategy through tabu search. Information Sciences 156: 189-214. doi: 10.1016/S0020-0255(03)00176-2
|
| [19] | S. Wagner and M. Affenzeller, Sexualga: Gender-specific selection for genetic algorithms, in Proceedings of the 9th World Multi-Conference on Systemics, Cybernetics and Informatics (WMSCI), 4 (2005), 76–81. |
| [20] |
Wang R., Fleming P.J., Purshousea R.C. (2014) General framework for localised multi-objective evolutionary algorithms. Information Sciences 258: 29-53. doi: 10.1016/j.ins.2013.08.049
|
| [21] |
Wang Y., Cai Z., Zhang Q. (2011) Differential evolution with composite trial vector generation strategies and control parameters. IEEE Transactions on Evolutionary Computation 15: 55-66. doi: 10.1109/TEVC.2010.2087271
|
Figures(2) / Tables(2)

Jinyuan Zhang, Aimin Zhou, Guixu Zhang, Hu Zhang. 2017: A clustering based mate selection for evolutionary optimization, Big Data and Information Analytics, 2(1): 77-85. doi: 10.3934/bdia.2017010









 DownLoad:
DownLoad: