Citation: Guojun Gan, Qiujun Lan, Shiyang Sima. Scalable Clustering by Truncated Fuzzy c-means[J]. Big Data and Information Analytics, 2016, 1(2): 247-259. doi: 10.3934/bdia.2016007

| [1] | [ C. C. Aggarwal and C. K. Reddy (eds.), Data Clustering:Algorithms and Applications, CRC Press, Boca Raton, FL, USA, 2014. |
| [2] | [ D. Arthur and S. Vassilvitskii, k-means++:The advantages of careful seeding, in Proceedings of the Eighteenth Annual ACM-SIAM Symposium on Discrete Algorithms, SODA'07, Society for Industrial and Applied Mathematics, Philadelphia, PA, USA, 2007, 1027-1035. |
| [3] | [ J. C. Bezdek, R. Ehrlich and W. Full, FCM:The fuzzy c-means clustering algorithm, Computers & Geosciences, 10(1984), 191-203. |
| [4] | [ J. Bezdek, Pattern Recognition with Fuzzy Objective Function Algorithms, Kluwer Academic Publishers, Norwell, MA, USA, 1981. |
| [5] | [ A. Broder, L. Garcia-Pueyo, V. Josifovski, S. Vassilvitskii and S. Venkatesan, Scalable kmeans by ranked retrieval, in Proceedings of the 7th ACM International Conference on Web Search and Data Mining, WSDM'14, ACM, 2014, 233-242. |
| [6] | [ R. L. Cannon, J. V. Dave and J. Bezdek, Efficient implementation of the fuzzy c-means clustering algorithms, IEEE Transactions on Pattern Analysis and Machine Intelligence, PAMI-8(1986), 248-255. |
| [7] | [ T. W. Cheng, D. B. Goldgof and L. O. Hall, Fast fuzzy clustering, Fuzzy Sets and Systems, 93(1998), 49-56. |
| [8] | [ M. de Souto, I. Costa, D. de Araujo, T. Ludermir and A. Schliep, Clustering cancer gene expression data:A comparative study, BMC Bioinformatics, 9(2008), p497. |
| [9] | [ J. C. Dunn, A fuzzy relative of the ISODATA process and its use in detecting compact well-separated clusters, Journal of Cybernetics, 3(1973), 32-57. |
| [10] | [ G. Gan, Data Clustering in C++:An Object-Oriented Approach, Data Mining and Knowledge Discovery Series, Chapman & Hall/CRC Press, Boca Raton, FL, USA, 2011. |
| [11] | [ G. Gan, Application of data clustering and machine learning in variable annuity valuation, Insurance:Mathematics and Economics, 53(2013), 795-801. |
| [12] | [ G. Gan, A multi-asset Monte Carlo simulation model for the valuation of variable annuities, in Proceedings of the Winter Simulation Conference, 2015, 3162-3163. |
| [13] | [ G. Gan and S. Lin, Valuation of large variable annuity portfolios under nested simulation:A functional data approach, Insurance:Mathematics and Economics, 62(2015), 138-150. |
| [14] | [ G. Gan and M. K.-P. Ng, Subspace clustering using affinity propagation, Pattern Recognition, 48(2015), 1455-1464. |
| [15] | [ G. Gan and M. K.-P. Ng, Subspace clustering with automatic feature grouping, Pattern Recognition, 48(2015), 3703-3713. |
| [16] | [ G. Gan, Y. Zhang and D. K. Dey, Clustering by propagating probabilities between data points, Applied Soft Computing, 41(2016), 390-399. |
| [17] | [ R. J. Hathaway and J. C. Bezdek, Extending fuzzy and probabilistic clustering to very large data sets, Computational Statistics & Data Analysis, 51(2006), 215-234. |
| [18] | [ T. Havens, J. Bezdek, C. Leckie, L. Hall and M. Palaniswami, Fuzzy c-means algorithms for very large data, IEEE Transactions on Fuzzy Systems, 20(2012), 1130-1146. |
| [19] | [ M.-C. Hung and D.-L. Yang, An efficient fuzzy c-means clustering algorithm, in Proceedings IEEE International Conference on Data Mining, 2001, 225-232. |
| [20] | [ Z.-X. Ji, Q.-S. Sun and D.-S. Xia, A modified possibilistic fuzzy c-means clustering algorithm for bias field estimation and segmentation of brain MR image, Computerized Medical Imaging and Graphics, 35(2011), 383-397. |
| [21] | [ D. Jiang, C. Tang and A. Zhang, Cluster analysis for gene expression data:A survey, IEEE Transactions on Knowledge and Data Engineering, 16(2004), 1370-1386. |
| [22] | [ F. Klawonn, Fuzzy clustering:Insights and a new approach, Mathware & Soft Computing, 11(2004), 125-142. |
| [23] | [ J. F. Kolen and T. Hutcheson, Reducing the time complexity of the fuzzy c-means algorithm, IEEE Transactions on Fuzzy Systems, 10(2002), 263-267. |
| [24] | [ T. Kwok, K. Smith, S. Lozano and D. Taniar, Parallel fuzzy c-means clustering for large data sets, in Euro-Par 2002 Parallel Processing (eds. B. Monien and R. Feldmann), vol. 2400 of Lecture Notes in Computer Science, Springer, 2002, 365-374. |
| [25] | [ H. Liu, F. Zhao and L. Jiao, Fuzzy spectral clustering with robust spatial information for image segmentation, Applied Soft Computing, 12(2012), 3636-3647. |
| [26] | [ J. D. MacCuish and N. E. MacCuish, Clustering in Bioinformatics and Drug Discovery, CRC Press, Boca Raton, FL, 2010. |
| [27] | [ J. Macqueen, Some methods for classification and analysis of multivariate observations, in Proceedings of the 5th Berkeley Symposium on Mathematical Statistics andProbability (eds. L. LeCam and J. Neyman), University of California Press, Berkely, CA, USA, 1(1967), 281-297. |
| [28] | [ S. A. A. Shalom, M. Dash and M. Tue, Graphics hardware based efficient and scalable fuzzy cmeans clustering, in Proceedings of the 7th Australasian Data Mining Conference, 87(2008), 179-186. |
| [29] | [ A. Stetco, X.-J. Zeng and J. Keane, Fuzzy c-means++:Fuzzy c-means with effective seeding initalization, Expert Systems with Applications, 42(2015), 7541-7548. |
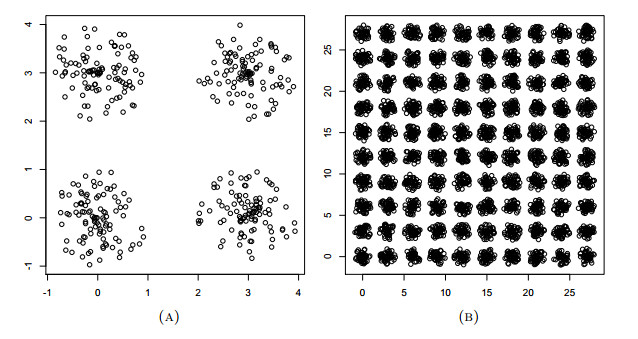
Figures(1) / Tables(5)

Guojun Gan, Qiujun Lan, Shiyang Sima. Scalable Clustering by Truncated Fuzzy c-means[J]. Big Data and Information Analytics, 2016, 1(2): 247-259. doi: 10.3934/bdia.2016007









 DownLoad:
DownLoad: