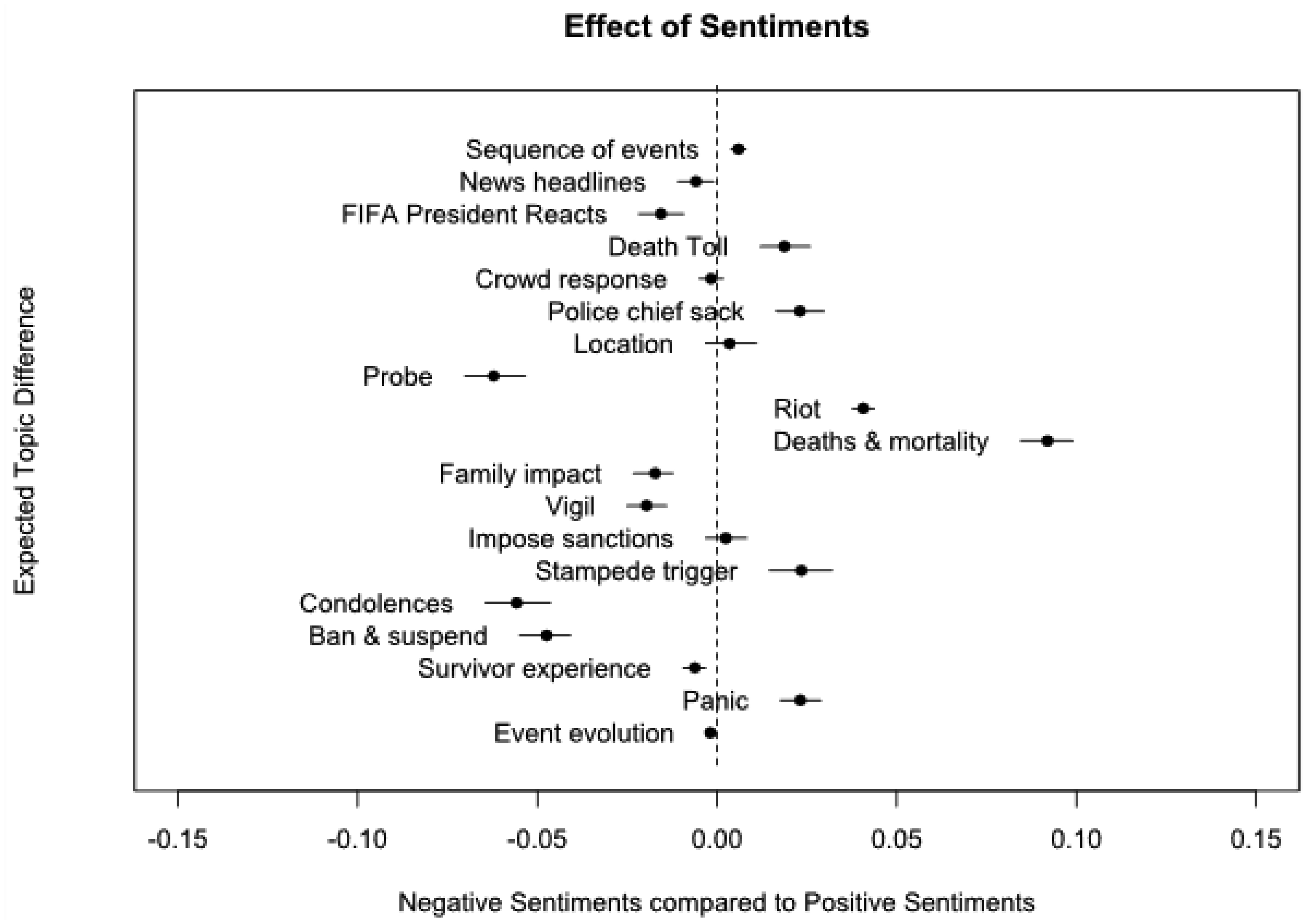
This study examined discourses related to an Indonesian soccer stadium stampede on 1st October 2022 using comments posted on Twitter. We conducted a lexicon-based sentiment analysis to identify the sentiments and emotions expressed in tweets and performed structural topic modeling to identify latent themes in the discourse. The majority of tweets (87.8%) expressed negative sentiments, while 8.2% and 4.0% of tweets expressed positive and neutral sentiments, respectively. The most common emotion expressed was fear (29.3%), followed by sadness and anger. Of the 19 themes identified, “Deaths and mortality” was the most prominent (15.1%), followed by “family impact”. The negative stampede discourse was related to public concerns such as “vigil” and “calls for bans and suspension,” while positive discourse focused more on the impact of the stampede. Public health institutions can leverage the volume and rapidity of social media to improve disaster prevention strategies.
Citation: Otobo I. Ujah, Chukwuemeka E Ogbu, Russell S. Kirby. “Is a game really a reason for people to die?” Sentiment and thematic analysis of Twitter-based discourse on Indonesia soccer stampede[J]. AIMS Public Health, 2023, 10(4): 739-754. doi: 10.3934/publichealth.2023050
This study examined discourses related to an Indonesian soccer stadium stampede on 1st October 2022 using comments posted on Twitter. We conducted a lexicon-based sentiment analysis to identify the sentiments and emotions expressed in tweets and performed structural topic modeling to identify latent themes in the discourse. The majority of tweets (87.8%) expressed negative sentiments, while 8.2% and 4.0% of tweets expressed positive and neutral sentiments, respectively. The most common emotion expressed was fear (29.3%), followed by sadness and anger. Of the 19 themes identified, “Deaths and mortality” was the most prominent (15.1%), followed by “family impact”. The negative stampede discourse was related to public concerns such as “vigil” and “calls for bans and suspension,” while positive discourse focused more on the impact of the stampede. Public health institutions can leverage the volume and rapidity of social media to improve disaster prevention strategies.

| [1] | Daniel DTG, Alpert EA, Jaffe E (2022) The crowd crush at mount meron: Emergency medical services response to a silent mass casualty incident. Disaster Med Public Health Prep 1–3. https://doi.org/10.1017/dmp.2022.162 |
| [2] |
Alquthami AH, Pines JM (2014) A systematic review of noncommunicable health issues in mass gatherings. Prehosp Disaster Med 29: 167-175. https://doi.org/10.1017/S1049023X14000144 
|
| [3] |
Memish ZA, Steffen R, White P, et al. (2019) Mass gatherings medicine: Public health issues arising from mass gathering religious and sporting events. Lancet 393: 2073-2084. https://doi.org/10.1016/S0140-6736(19)30501-X
|
| [4] | World Health OrganizationPublic health for mass gatherings: Key considerations (2015). Available from: https://www.who.int/publications/i/item/public-health-for-mass-gatherings-key-considerations |
| [5] |
de Almeida MM, von Schreeb J (2019) Human stampedes: An updated review of current literature. Prehosp Disaster Med 34: 82-88. https://doi.org/10.1017/S1049023X18001073
|
| [6] |
Hsieh YH, Ngai KM, Burkle FM, et al. (2009) Epidemiological characteristics of human stampedes. Disaster Med Public Health Prep 3: 217-223. https://doi.org/10.1097/DMP.0b013e3181c5b4ba
|
| [7] |
Ngai KM, Burkle FM, Hsu A, et al. (2009) Human stampedes: a systematic review of historical and peer-reviewed sources. Disaster Med Public Health Prep 3: 191-195. https://doi.org/10.1097/DMP.0b013e3181c5b494
|
| [8] |
Madzimbamuto F D (2003) A hospital response to a soccer stadium stampede in Zimbabwe. Emerg Med J 20: 556-559. https://doi.org/10.1136/emj.20.6.556
|
| [9] |
Burkle F M, Hsu E B (2011) Ram Janki Temple: understanding human stampedes. Lancet 377: 106-107. https://doi.org/10.1016/S0140-6736(10)60442-4
|
| [10] | Illiyas FT, Mani SK, Pradeepkumar AP, et al. (2013) Human stampedes during religious festivals: A comparative review of mass gathering emergencies in India. Int J Disast Risk Re 5: 10-18. https://doi.org/10.1016/j.ijdrr.2013.09.003 |
| [11] | Washington PostStampede at Indonesia soccer game kills 125, officials say (2022). Available from: https://www.washingtonpost.com/world/2022/10/01/indonesia-riot-arema-fc-liga-football/. |
| [12] |
Doan AE, Bogen KW, Higgins E, et al. (2022) A content analysis of twitter backlash to Georgia's abortion ban. Sex Reprod Healthc 31: 100689. https://doi.org/10.1016/j.srhc.2021.100689
|
| [13] |
Sinnenberg L, Buttenheim A M, Padrez K, et al. (2017) Twitter as a tool for health research: A systematic review. Am J Public Health 107: e1-e8. https://doi.org/10.2105/AJPH.2016.303512
|
| [14] |
Amoudi G, Almansour A, Watters C, et al. (2015) Tweet for help: the role of social media in disaster events and the case of the 2015 Mina stampede. Digit Creat 33: 329-348. https://doi.org/10.1080/14626268.2022.2141262
|
| [15] |
Kryvasheyeu Y, Chen H, Moro E, et al. (2015) Performance of social network sensors during hurricane Sandy. PloS One 10: e0117288. https://doi.org/10.1371/journal.pone.0117288
|
| [16] |
Martín Y, Li Z, Cutter S L (2017) Leveraging Twitter to gauge evacuation compliance: Spatiotemporal analysis of hurricane Matthew. PloS One 12: e0181701. https://doi.org/10.1371/journal.pone.0181701
|
| [17] |
Shelton T, Poorthuis A, Graham M, et al. (2014) Mapping the data shadows of Hurricane Sandy: Uncovering the sociospatial dimensions of ‘big data’. Geoforum 52: 167-179. http://dx.doi.org/10.1016/j.geoforum.2014.01.006
|
| [18] |
Xu Z, Lachlan K, Ellis L, et al. (2020) Understanding public opinion in different disaster stages: a case study of Hurricane Irma. Internet Res 30: 695-709. https://doi.org/10.1108/intr-12-2018-0517
|
| [19] |
Zou L, Lam NSN, Shams S, et al. (2019) Social and geographical disparities in Twitter use during Hurricane Harvey. Int J Digit Earth 12: 1300-1318. https://doi.org/10.1080/17538947.2018.1545878
|
| [20] |
Duan J, Zhai W, Cheng C (2020) Crowd detection in mass gatherings based on social media data: A case study of the 2014 Shanghai New Year's Eve stampede. Int J Environ Res Public Health 17: 8640. https://doi.org/10.3390/ijerph17228640
|
| [21] |
Lanier HD, Diaz MI, Saleh SN, et al. (2022) Analyzing COVID-19 disinformation on Twitter using the hashtags #scamdemic and #plandemic: Retrospective study. PloS One 17: e0268409. https://doi.org/10.1371/journal.pone.0268409
|
| [22] |
Saleh SN, Lehmann C, McDonald S, et al. (2020) Understanding public perception of COVID-19 Social distancing on Twitter. Open Forum Infect D 7: S309. https://doi.org/10.1093/ofid/ofaa439.679
|
| [23] |
Saleh SN, Lehmann CU, McDonald SA, et al. (2021) Understanding public perception of coronavirus disease 2019 (COVID-19) social distancing on Twitter. Infect Cont Hosp Ep 42: 131-138. https://doi.org/10.1017/ice.2020.406
|
| [24] |
Yi J, Pan S, Chen Q (2020) Simulation of pedestrian evacuation in stampedes based on a cellular automaton model. Simul Model Pract Th 104: 102147. https://doi.org/10.1016/j.simpat.2020.102147
|
| [25] |
Ujah OI, Olaore P, Nnorom OC, et al. (2023) Examining ethno-racial attitudes of the public in Twitter discourses related to the United States Supreme Court Dobbs vs. Jackson Women's Health Organization ruling: A machine learning approach. Frontiers Glob Women Health 4: 1149441. https://doi.org/10.3389/fgwh.2023.1149441
|
| [26] |
Aranda AM, Sele K, Etchanchu H, et al. (2021) From big data to rich theory: Integrating critical discourse analysis with structural topic modeling. Eur Manag Rev 18: 197-214. https://doi.org/10.1111/emre.12452
|
| [27] | O'Connor Brendan, Bamman David, A Smith Noah (2018) Computational text analysis for social science: Model assumptions and complexity. Carnegie Mellon Univ. J Contrib . https://doi.org/10.1184/R1/6473291.v1 |
| [28] |
Macanovic A (2022) Text mining for social science - The state and the future of computational text analysis in sociology. Soc Sci Res 108: 102784. https://doi.org/10.1016/j.ssresearch.2022.102784
|
| [29] |
Stracqualursi L, Agati P (2022) Tweet topics and sentiments relating to distance learning among Italian Twitter users. Sci Rep 12: 9163. https://doi.org/10.1038/s41598-022-12915-w
|
| [30] |
Kryvasheyeu Y, Chen H, Obradovich N, et al. (2016) Rapid assessment of disaster damage using social media activity. Sci Advances 2: e1500779. https://doi.org/10.1126/sciadv.1500779
|
| [31] |
Perlstein SG, Verboord M (2021) Lockdowns, lethality, and laissez-faire politics. Public discourses on political authorities in high-trust countries during the COVID-19 pandemic. PloS One 16: e0253175. https://doi.org/10.1371/journal.pone.0253175
|
| [32] |
Carosia AEO, Coelho GP, Silva AEA (2020) Analyzing the Brazilian Financial Market through Portuguese Sentiment Analysis in Social Media. Appl Artif Intell 34: 1-19. https://doi.org/10.1080/08839514.2019.1673037
|
| [33] |
Fino E, Hanna-Khalil B, Griffiths MD (2021) Exploring the public's perception of gambling addiction on Twitter during the COVID-19 pandemic: Topic modelling and sentiment analysis. J Addict Dis 39: 489-503. https://doi.org/10.1080/10550887.2021.1897064
|
| [34] |
Shahin S, Ng YMM (2022) Connective action or collective inertia? Emotion, cognition, and the limits of digitally networked resistance. Soc Movement Stud 21: 530-548. https://doi.org/10.1080/14742837.2021.1928485
|
| [35] |
Lindstedt NC (2019) Structural topic modeling for social scientists: A brief case study with social movement studies literature, 2005–2017. Soc Curr 6: 307-318. https://doi.org/10.1177/2329496519846505
|
| [36] |
Roberts ME, Stewart BM, Tingley D (2019) stm: An R Package for Structural Topic Models. J Stat Softw 91: 1-40. https://doi.org/10.18637/jss.v091.i02
|
| [37] |
Ramondt S, Kerkhof P, Merz EM (2022) Blood donation narratives on social media: A topic modeling study. Transfus Med Rev 36: 58-65. https://doi.org/10.1016/j.tmrv.2021.10.001
|
| [38] |
Schwartz B, Nafziger S, Milsten A, et al. (2015) Mass gathering medical care: Resource document for the national association of EMS physicians position statement. Prehosp Emerg Care 19: 559-568. https://doi.org/10.3109/10903127.2015.1051680
|
| [39] | Slabbert AD, Ukpere WI (2010) A preliminary comparative study of rugby and football spectators' attitudes towards violence. Afr J Bus Manag 4: 459-466. https://doi.org/10.5897/AJBM.9000022 |
| [40] |
Khan AA, Sabbagh AY, Ranse J, et al. (2021) Mass gathering medicine in soccer leagues: A review and creation of the SALEM Tool. Int J Environ Res Public Health 18: 9973. https://doi.org/10.3390/ijerph18199973
|
| [41] |
Thackway S, Churches T, Fizzell J, et al. (2009) Should cities hosting mass gatherings invest in public health surveillance and planning? Reflections from a decade of mass gatherings in Sydney, Australia. BMC Public Health 9: 324. https://doi.org/10.1186/1471-2458-9-324
|
| [42] |
Koski A, Kouvonen A, Sumanen H (2020) Preparedness for Mass Gatherings: Factors to Consider According to the Rescue Authorities. Int J Environ Res Public Health 17: 1361. https://doi.org/10.3390/ijerph17041361
|
| [43] |
Hawkins JB, Brownstein JS, Tuli G, et al. (2016) Measuring patient-perceived quality of care in US hospitals using Twitter. BMJ Qual Saf 25: 404-413. https://doi.org/10.1136/bmjqs-2015-004309
|

Figures(2) / Tables(1)

Otobo I. Ujah, Chukwuemeka E Ogbu, Russell S. Kirby. “Is a game really a reason for people to die?” Sentiment and thematic analysis of Twitter-based discourse on Indonesia soccer stampede[J]. AIMS Public Health, 2023, 10(4): 739-754. doi: 10.3934/publichealth.2023050







 DownLoad:
DownLoad: