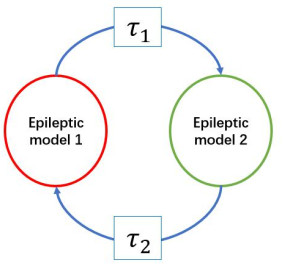
Epilepsy is considered as a brain network disease. Epileptic computational models are developed to simulate the electrophysiological process of seizure. Some studies have shown that the epileptic network based on those models can be used to predict the surgical outcome of patients with drug-resistant epilepsy. Most studies focused on the causal relationship between electrophysiological signals of different brain regions and its impact on seizure onset, and there is no knowledge about how time delay of electrophysiological signal transmitted between those regions related to seizure onset. In this study, we proposed an epileptic model with time delay between network nodes, and analyzed whether the time delay between nodes of epileptic network can cause seizure like event. Our results showed that the time delay between nodes may drive the network from normal state to seizure-like event through Hopf bifurcation. The time delay between nodes of epileptic computational network alone may induce seizure-like event. Our analysis suggested that the time delay of electrophysiological signals transmitted between different regions may be an important factor for seizure happening, which provide a deeper understanding of the epilepsy, and a potential new path for epilepsy treatment.
Citation: Yulin Guan, Xue Zhang. Dynamics of a coupled epileptic network with time delay[J]. Mathematical Modelling and Control, 2022, 2(1): 13-23. doi: 10.3934/mmc.2022003
Epilepsy is considered as a brain network disease. Epileptic computational models are developed to simulate the electrophysiological process of seizure. Some studies have shown that the epileptic network based on those models can be used to predict the surgical outcome of patients with drug-resistant epilepsy. Most studies focused on the causal relationship between electrophysiological signals of different brain regions and its impact on seizure onset, and there is no knowledge about how time delay of electrophysiological signal transmitted between those regions related to seizure onset. In this study, we proposed an epileptic model with time delay between network nodes, and analyzed whether the time delay between nodes of epileptic network can cause seizure like event. Our results showed that the time delay between nodes may drive the network from normal state to seizure-like event through Hopf bifurcation. The time delay between nodes of epileptic computational network alone may induce seizure-like event. Our analysis suggested that the time delay of electrophysiological signals transmitted between different regions may be an important factor for seizure happening, which provide a deeper understanding of the epilepsy, and a potential new path for epilepsy treatment.

| [1] |
M. Brodie, S. Barry, G. Bamagous, J. D. Norrie, P. Kwan, Patterns of treatment response in newly diagnosed epilepsy, Neurology, 78 (2012), 1548–1554. https://doi.org/10.1212/WNL.0b013e3182563b19 doi: 10.1212/WNL.0b013e3182563b19

|
| [2] |
P. Perucca, F. Dubeau, J. Gotman, Intracranial electroencephalographic seizure-onset patterns: effect of underlying pathology, Brain, 137 (2014), 183–196. https://doi.org/10.1093/brain/awt299 doi: 10.1093/brain/awt299
|
| [3] |
G. Bettus, E. Guedj, F. Joyeux, S. Confort‐Gouny, E. Soulier, V. Laguitton, et al., Decreased basal fMRI functional connectivity in epileptogenic networks and contralateral compensatory mechanisms, Hum. Brain Mapp., 30 (2009), 1580–1591. https://doi.org/10.1002/hbm.20625 doi: 10.1002/hbm.20625
|
| [4] |
B. Ridley, C. Rousseau, J. Wirsich, A. Le Troter, E. Soulier, S. Confort-Gouny, et al., Nodal approach reveals differential impact of lateralized focal epilepsies on hub reorganization, NeuroImage, 118 (2015), 39–48. https://doi.org/10.1016/j.jprot.2014.11.012 doi: 10.1016/j.jprot.2014.11.012
|
| [5] | J. Premysl, C. Marco, J. John, Modern concepts of focal epileptic networks, International Review of Neurobiology, 2014. |
| [6] |
D. Cosandier-Rimélé, F. Bartolomei, I. Merlet, P. Chauvel, F. Wendling, Recording of fast activity at the onset of partial seizures: Depth EEG vs. scalp EEG, NeuroImage, 59 (2012), 3474–3487. https://doi.org/10.1016/j.neuroimage.2011.11.045 doi: 10.1016/j.neuroimage.2011.11.045
|
| [7] |
M. A. Kramer, W. Truccolo, U. T. Eden, K. Q. Lepage, L. R. Hochberg, E. N. Eskandar, et al., Human seizures self-terminate across spatial scales via a critical transition, Proceedings of the National Academy of Sciences, 109 (2012), 21116–21121. https://doi.org/10.1073/pnas.1210047110 doi: 10.1073/pnas.1210047110
|
| [8] |
T. Proix, F. Bartolomei, P. Chauvel, C. Bernard, V. K. Jirsa, Permittivity coupling across brain regions determines seizure recruitment in partial epilepsy, The Journal of Neuroscience, 34 (2014), 15009–15021. https://doi.org/10.1523/JNEUROSCI.1570-14.2014 doi: 10.1523/JNEUROSCI.1570-14.2014
|
| [9] |
M. Ahmadi, D. Hagler, C. McDonald, E. S. Tecoma, V. J. Iragui, A. M. Dale, et al., Side matters: diffusion tensor imaging tractography in left and right temporal lobe epilepsy, Am. J. Neuroradiol., 30 (2009), 1740–1747. https://doi.org/10.3174/ajnr.A1650 doi: 10.3174/ajnr.A1650
|
| [10] |
T. Proix, V. K. Jirsa, F. Bartolomei, M. Guye, W. Truccolo, Predicting the spatiotemporal diversity of seizure propagation and termination in human focal epilepsy, Nat. Commun., 9 (2018), 1–15. https://doi.org/10.1038/s41467-018-02973-y doi: 10.1038/s41467-018-02973-y
|
| [11] |
V. Jirsa, K. Jantzen, A. Fuchs, J. S. Kelso, Spatiotemporal forward solution of the EEG and MEG using network modeling, IEEE T. Med. Imag., 21 (2002), 493–504. https://doi.org/10.1109/TMI.2002.1009385 doi: 10.1109/TMI.2002.1009385
|
| [12] |
F. Wendling, F. Bartolomei, J. Bellanger, P. Chauvel, Epileptic fast activity can be explained by a model of impaired GABAergic dendritic inhibition, Eur. J. Neurosci., 15 (2002), 1499–1508. https://doi.org/10.1046/j.1460-9568.2002.01985.x doi: 10.1046/j.1460-9568.2002.01985.x
|
| [13] |
S. Kalitzin, D. Velis, F. Silva, Stimulation-based anticipation and control of state transitions in the epileptic brain, Epilepsy Behav., 17 (2009), 310–323. https://doi.org/10.3200/DEMO.17.4.310-323 doi: 10.3200/DEMO.17.4.310-323
|
| [14] | P. R. Bauer, R. D. Thijs, R. J. Lamberts, D. N. Velis, G. H. Visser, E. A. Tolner, et al., Dynamics of convulsive seizure termination and postictal generalized EEG suppression, Brain, 140 (2017), 655–668. |
| [15] |
V. K. Jirsa, W. C. Stacey, P. P. Quilichini, A. I. Ivanov, C. Bernard, On the nature of seizure dynamics, Brain, 137 (2014), 2210–2230. https://doi.org/10.1093/brain/awu133 doi: 10.1093/brain/awu133
|
| [16] |
T. Proix, F. Bartolomei, M. Guye, V. Jirsa, Individual brain structure and modelling predict seizure propagation, Revue Neurologique, 174 (2018), S177. https://doi.org/10.1016/j.neurol.2018.02.047 doi: 10.1016/j.neurol.2018.02.047
|
| [17] |
F. Bartolomei, P. Chauvel, F. Wendling, Spatio-temporal dynamics of neuronal networks in partial epilepsy, Revue neurologique, 161 (2005), 767–780. https://doi.org/10.1016/S0035-3787(05)85136-7 doi: 10.1016/S0035-3787(05)85136-7
|
| [18] |
K. Bandt, P. Besson, B. Ridley, F. Pizzo, R. Carron, J. Regis, et al., Connectivity strength, time lag structure and the epilepsy network in resting-state fMRI, NeuroImage: Clinical, 24 (2019), 102035. https://doi.org/10.1016/j.nicl.2019.102035 doi: 10.1016/j.nicl.2019.102035
|
| [19] |
H. Zhang, P. Xiao, Seizure Dynamics of Coupled Oscillators with Epileptor Field Model, Int. J. Bifurcat. Chaos, 28 (2018), 1850041. https://doi.org/10.1142/S0218127418500414 doi: 10.1142/S0218127418500414
|
| [20] | K. Schneider, Theory and Applications of Hopf Bifurcation, Applied Mathematics and Mechanics, Applied Mathematics and Mechanics, 62 (1981), 713–714. |
| [21] |
H. Wang, Y. Huang, D. Coman, R. Munbodh, R. Dhaher, H.P. Zaveri, et al., Network evolution in mesial temporal lobe epilepsy revealed by diffusion tensor imaging, Epilepsia, 58 (2017), 824–834. https://doi.org/10.1111/epi.13731 doi: 10.1111/epi.13731
|
| [22] |
L. Peraza, A. Asghar, G. Green, D. M. Halliday, Volume conduction effects in brain network inference from electroencephalographic recordings using phase lag index, J. Neurosci. Meth., 207 (2012), 189–199. https://doi.org/10.1016/j.jneumeth.2012.04.007 doi: 10.1016/j.jneumeth.2012.04.007
|






Figures(7)
Yulin Guan, Xue Zhang. Dynamics of a coupled epileptic network with time delay[J]. Mathematical Modelling and Control, 2022, 2(1): 13-23. doi: 10.3934/mmc.2022003







 DownLoad:
DownLoad: