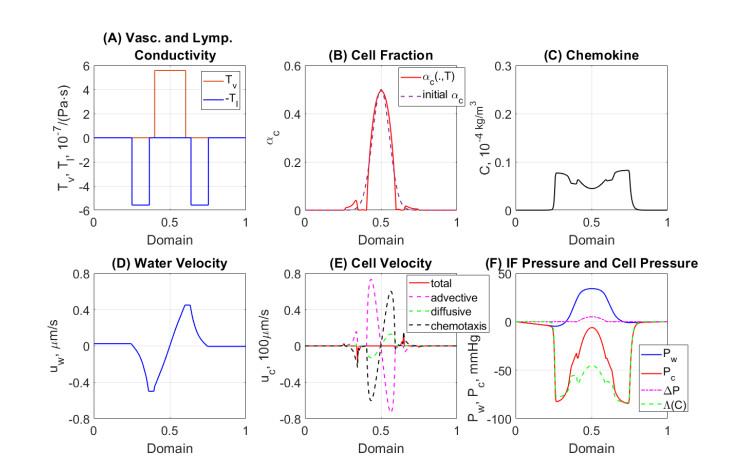
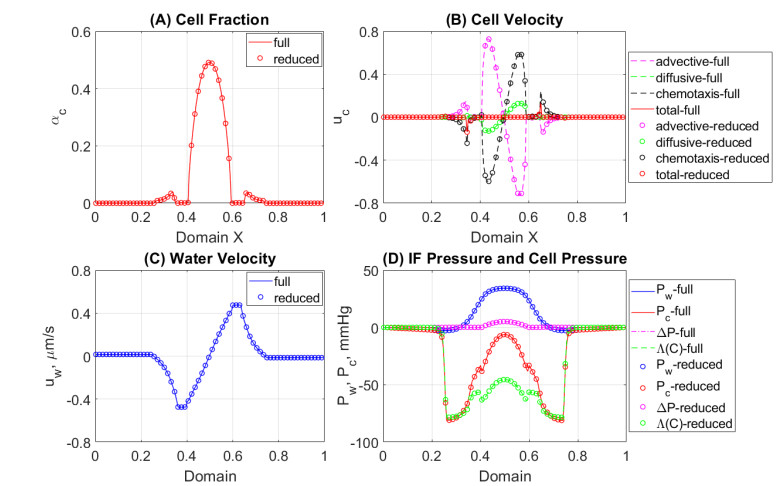
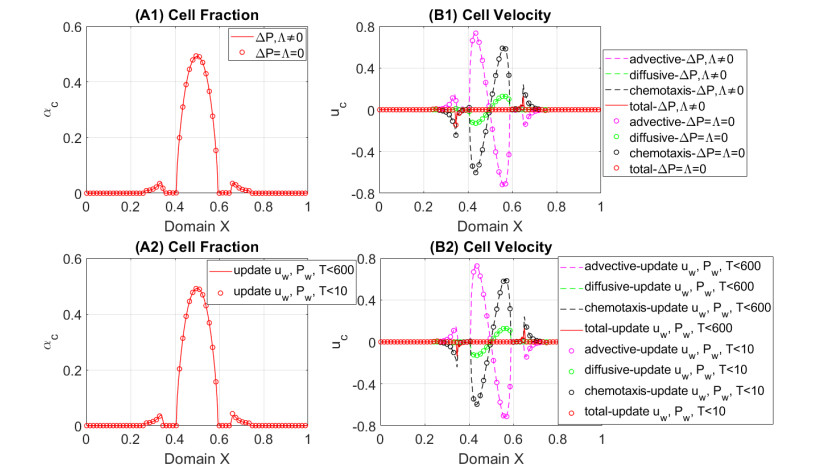
In this work we explore a recently proposed biphasic cell-fluid chemotaxis-Stokes model which is able to represent two competing cancer cell migration mechanisms reported from experimental studies. Both mechanisms depend on the fluid flow but in a completely different way. One mechanism depends on chemical signaling and leads to migration in the downstream direction. The other depends on mechnical signaling and triggers cancer cells to go upstream. The primary objective of this paper is to explore an alternative numerical discretization of this model by borrowing ideas from [Qiao et al. (2020), M3AS 30]. Numerical investigations give insight into which parameters that are critical for the ability to generate aggressive cancer cell behavior in terms of detachment of cancer cells from the primary tumor and creation of isolated groups of cancer cells close to the lymphatic vessels. The secondary objective is to propose a reduced model by exploiting the fact that the fluid velocity field is largely dictated by the draining fluid from the leaky tumor vasculature and collecting peritumoral lymphatics and is more weakly coupled to the cell phase. This suggests that the fluid flow equations to a certain extent might be decoupled from the cell phase equations. The resulting model, which represents a counterpart of the much studied chemotaxis-Stokes model model proposed by [Tuval, et al. (2005), PNAS 102], is explored by numerical experiments in a one-dimensional tumor setting. We find that the model largely coincides with the original as assessed through numerical solutions computed by discrete schemes. This model might be more amenable for further explorations and analysis. We also investigate how to exploit the weaker coupling between cell phase dynamics and fluid dynamics to do more efficient calculations with fewer updates of the fluid pressure and velocity field.
Citation: Yangyang Qiao, Qing Li, Steinar Evje. On the numerical discretization of a tumor progression model driven by competing migration mechanisms[J]. Mathematics in Engineering, 2022, 4(6): 1-24. doi: 10.3934/mine.2022046
In this work we explore a recently proposed biphasic cell-fluid chemotaxis-Stokes model which is able to represent two competing cancer cell migration mechanisms reported from experimental studies. Both mechanisms depend on the fluid flow but in a completely different way. One mechanism depends on chemical signaling and leads to migration in the downstream direction. The other depends on mechnical signaling and triggers cancer cells to go upstream. The primary objective of this paper is to explore an alternative numerical discretization of this model by borrowing ideas from [Qiao et al. (2020), M3AS 30]. Numerical investigations give insight into which parameters that are critical for the ability to generate aggressive cancer cell behavior in terms of detachment of cancer cells from the primary tumor and creation of isolated groups of cancer cells close to the lymphatic vessels. The secondary objective is to propose a reduced model by exploiting the fact that the fluid velocity field is largely dictated by the draining fluid from the leaky tumor vasculature and collecting peritumoral lymphatics and is more weakly coupled to the cell phase. This suggests that the fluid flow equations to a certain extent might be decoupled from the cell phase equations. The resulting model, which represents a counterpart of the much studied chemotaxis-Stokes model model proposed by [Tuval, et al. (2005), PNAS 102], is explored by numerical experiments in a one-dimensional tumor setting. We find that the model largely coincides with the original as assessed through numerical solutions computed by discrete schemes. This model might be more amenable for further explorations and analysis. We also investigate how to exploit the weaker coupling between cell phase dynamics and fluid dynamics to do more efficient calculations with fewer updates of the fluid pressure and velocity field.

| [1] |
T. Black, Global very weak solutions to a chemotaxis-fluid system with nonlinear diffusion, SIAM J. Math. Anal., 50 (2018), 4087–4116. doi: 10.1137/17M1159488

|
| [2] |
H. M. Byrne, M. R. Owen, A new interpretation of the Keller-Segel model based on multiphase modelling, J. Math. Biol., 49 (2004), 604–626. doi: 10.1007/s00285-004-0276-4
|
| [3] |
X. Cao, Fluid interaction does not affect the critical exponent in a three-dimensional Keller-Segel-Stokes model, Z. Angew. Math. Phys., 71 (2020), 61. doi: 10.1007/s00033-020-1285-x
|
| [4] |
A. Chhetri, J. V. Rispoli, S. A. Lelievre, 3D cell culture for the study of microenvironment-mediated mechanostimuli to the cell nucleus: An important step for cancer research, Front. Mol. Biosci., 8 (2021), 628386. doi: 10.3389/fmolb.2021.628386
|
| [5] | D. A. Drew, S. L. Passman, Theory of multicomponent fluids, Springer, 1999. |
| [6] | M. Di Francesco, A. Lorz, P. Markowich, Chemotaxis-fluid coupled model for swimming bacteria with nonlinear diffusion: global existence and asymptotic behavior, DCDS, 28 (2010) 1437–1453. |
| [7] |
S. Evje, An integrative multiphase model for cancer cell migration under influence of physical cues from the microenvironment, Chem. Eng. Sci., 165 (2017), 240–259. doi: 10.1016/j.ces.2017.02.045
|
| [8] |
S. Evje, J. O. Waldeland, How tumor cells can make use of interstitial fluid flow in a strategy for metastasis, Cell. Mol. Bioeng., 12 (2019), 227–254. doi: 10.1007/s12195-019-00569-0
|
| [9] |
S. Evje, H. Wen, A Stokes two-fluid model for cell migration that can account for physical cues in the microenvironment, SIAM J. Math. Anal., 50 (2018), 86–118. doi: 10.1137/16M1078185
|
| [10] |
S. Evje, M. Winkler, Mathematical analysis of two competing cancer cell migration mechanisms driven by interstitial fluid flow, J. Nonlinear Sci., 30 (2020), 1809–1847. doi: 10.1007/s00332-020-09625-w
|
| [11] |
G. Follain, D. Herrmann, S. Harlepp, V. Hyenne, N. Osmani, S. C. Warren, et al., Fluids and their mechanics in tumour transit: shaping metastasis, Nat. Rev. Cancer, 20 (2020), 107–124. doi: 10.1038/s41568-019-0221-x
|
| [12] |
U. Haessler, J. C. M. Teo, D. Foretay, P. Renaud, M. A. Swartz, Migration dynamics of breast cancer cells in a tunable 3D interstitial flow chamber, Integr. Biol., 4 (2012), 401–409. doi: 10.1039/c1ib00128k
|
| [13] |
A. Lorz, Coupled Keller-Segel-Stokes model: global existence for small initial data and blow-up delay, Commun. Math. Sci., 10 (2012), 555–574. doi: 10.4310/CMS.2012.v10.n2.a7
|
| [14] | S. Mishra, A machine learning framework for data driven acceleration of computations of differential equations, Math. Eng., 1 (2019), 118–146. |
| [15] |
J. A. Pedersen, S. Lichter, M. A. Swartz, Cells in 3D matrices under interstitial flow: effects of extracellular matrix alignment on cell shear stress and drag forces, J. Biomech., 43 (2010), 900–905. doi: 10.1016/j.jbiomech.2009.11.007
|
| [16] |
W. J. Polacheck, J. L. Charest, R. D. Kamm, Interstitial flow influences direction of tumor cell migration through competing mechanisms, Proc. Natl. Acad. Sci. U.S.A., 108 (2011), 11115–11120. doi: 10.1073/pnas.1103581108
|
| [17] |
W. J. Polacheck, A. E. German, A. Mammoto, D. E. Ingber, R. D. Kamm, Mechanotransduction of fluid stresses governs 3D cell migration, Proc. Natl. Acad. Sci. U.S.A., 111 (2014), 2447–2452. doi: 10.1073/pnas.1316848111
|
| [18] |
Y. Qiao, P. Ø. Andersen, S. Evje, D. C. Standnes, A mixture theory approach to model co-and counter-current two-phase flow in porous media accounting for viscous coupling, Adv. Water Resour., 112 (2018), 170–188. doi: 10.1016/j.advwatres.2017.12.016
|
| [19] |
Y. Qiao, S. Evje, A general cell–fluid {N}avier-{S}tokes model with inclusion of chemotaxis, Math. Models Methods Appl. Sci., 30 (2020), 1167–1215. doi: 10.1142/S0218202520400096
|
| [20] |
Y. Qiao, S. Evje, A compressible viscous three-phase model for porous media flow based on the theory of mixtures, Adv. Water Resour., 141 (2020), 103599. doi: 10.1016/j.advwatres.2020.103599
|
| [21] |
Y. Qiao, H. Wen, S. Evje, Viscous two-phase flow in porous media driven by source terms: analysis and numerics, SIAM J. Math Anal., 51 (2019), 5103–5140. doi: 10.1137/19M1252491
|
| [22] |
K. R. Rajagopal, On a hierarchy of approximate models for flows of incompressible fluids through porous solids, Math. Models Methods Appl. Sci., 17 (2007), 215–252. doi: 10.1142/S0218202507001899
|
| [23] |
G. S. Rosalem, E. B. L. Casas, T. P. Lima, L. A. Gonzalez-Torres, A mechanobiological model to study upstream cell migration guided by tensotaxis, Biomech. Mod. Mech., 19 (2020), 1537–1549. doi: 10.1007/s10237-020-01289-5
|
| [24] |
J. D. Shields, M. E. Fleury, C. Yong, A. A. Tomei, G. J. Randolph, M. A. Swartz, Autologous chemotaxis as a mechanism of tumor cell homing to lymphatics via interstitial flow and autocrine CCR7 signaling, Cancer Cell, 11 (2007), 526–538. doi: 10.1016/j.ccr.2007.04.020
|
| [25] |
D. C. Standnes, S. Evje, P. Ø. Andersen, A novel relative permeability model based on mixture theory approach accounting for solid–fluid and fluid–fluid interactions, Tran. Por. Med., 119 (2017), 707–738. doi: 10.1007/s11242-017-0907-z
|
| [26] |
M. A. Swartz, M. E. Fleury, Interstitial flow and its effects in soft tissues, Annu. Rev. Biomed. Eng., 9 (2007), 229–256. doi: 10.1146/annurev.bioeng.9.060906.151850
|
| [27] |
Y. Tao, M. Winkler, Global existence and boundedness in a Keller-Segel-Stokes model with arbitrary porous medium diffusion, DCDS, 32 (2012), 1901–1914. doi: 10.3934/dcds.2012.32.1901
|
| [28] |
Y. Tao, M. Winkler, Locally bounded global solutions in a three-dimensional chemotaxis-Stokes system with nonlinear diffusion, Ann. Inst. H. Poincaré Anal. Non Linéaire, 30 (2013), 157–178. doi: 10.1016/j.anihpc.2012.07.002
|
| [29] |
I. Tuval, L. Cisneros, C. Dombrowski, C. W. Wolgemuth, J. O. Kessler, R. E. Goldstein, Bacterial swimming and oxygen transport near contact lines, Proc. Natl. Acad. Sci. U.S.A., 102 (2005), 2277–2282. doi: 10.1073/pnas.0406724102
|
| [30] |
J. O. Waldeland, S. Evje, A multiphase model for exploring cancer cell migration driven by autologous chemotaxis, Chem. Eng. Sci., 191 (2018), 268–287. doi: 10.1016/j.ces.2018.06.076
|
| [31] |
J. O. Waldeland, S. Evje, Competing tumor cell migration mechanisms caused by interstitial fluid flow, J. Biomech., 81 (2018), 22–35. doi: 10.1016/j.jbiomech.2018.09.011
|
| [32] |
H. Wiig, M. A. Swartz, Interstitial fluid and lymph formation and transport: physiological regulation and roles in inflammation and cancer, Physiol Rev., 92 (2012), 1005–1060. doi: 10.1152/physrev.00037.2011
|
| [33] |
M. Winkler, Stabilization in a two-dimensional chemotaxis-Navier-Stokes system, Arch. Rational Mech. Anal., 211 (2014), 455–487. doi: 10.1007/s00205-013-0678-9
|
| [34] |
M. Winkler, Does fluid interaction affect regularity in the three-dimensional Keller-Segel system with saturated sensitivity?, J. Math. Fluid Mech., 20 (2018), 1889–1909. doi: 10.1007/s00021-018-0395-0
|
| [35] |
M. Winkler, Small-mass solutions in the two-dimensional Keller-Segel system coupled to the Navier–Stokes equations, SIAM J. Math. Anal., 52 (2020), 2041–2080. doi: 10.1137/19M1264199
|
| [36] |
M. Winkler, Global weak solutions in a three-dimensional Keller-Segel-Navier-Stokes system with gradient-dependent flux limitation, Nonlinear Anal. Real, 59 (2021), 103257. doi: 10.1016/j.nonrwa.2020.103257
|
| [37] | Y. S. Wu, Multiphase fluid flow in porous and fractured reservoirs, Elsevier, 2016. |
| [38] |
H. Zhou, P. Lei, T. P. Padera, Progression of metastasis through lymphatic system, Cells, 10 (2021), 627. doi: 10.3390/cells10030627
|
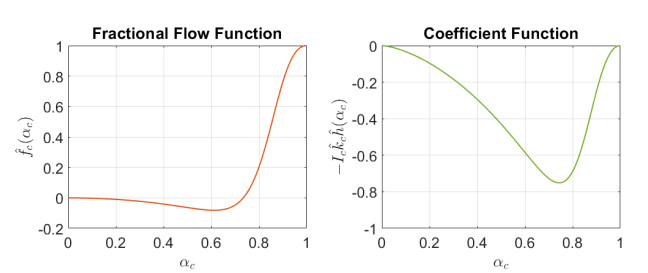
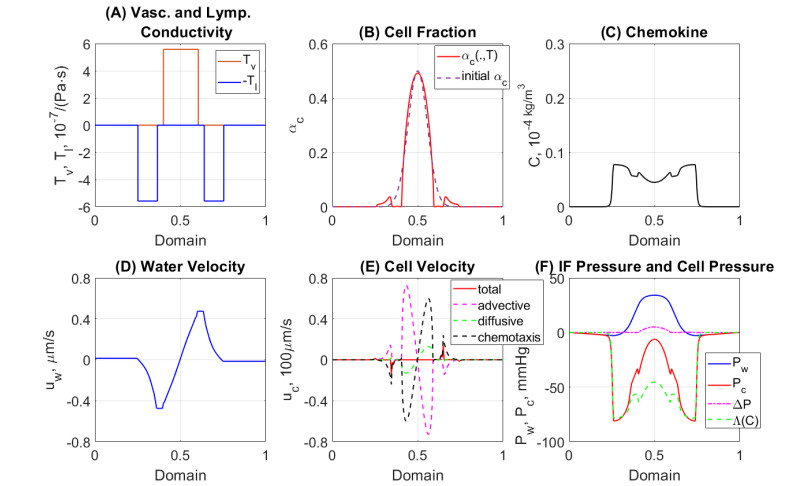
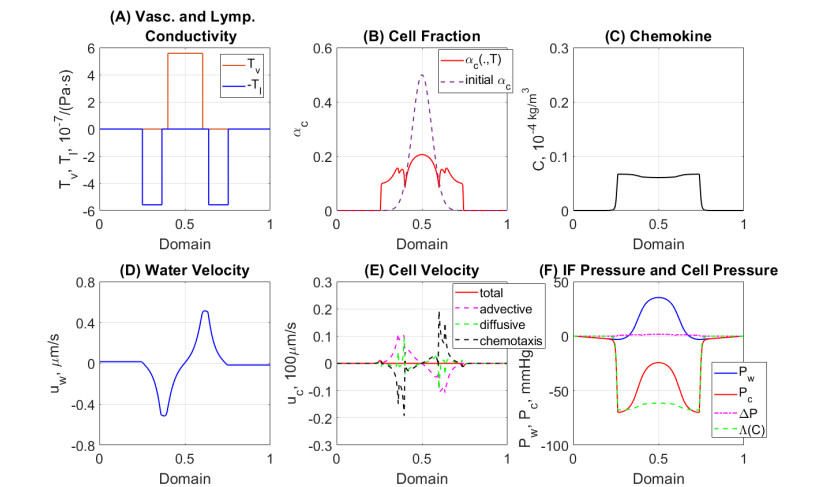
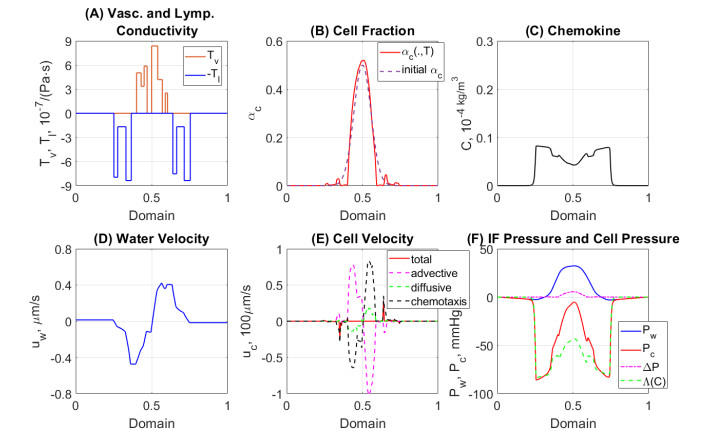
Figures(7) / Tables(1)

Yangyang Qiao, Qing Li, Steinar Evje. On the numerical discretization of a tumor progression model driven by competing migration mechanisms[J]. Mathematics in Engineering, 2022, 4(6): 1-24. doi: 10.3934/mine.2022046







 DownLoad:
DownLoad: