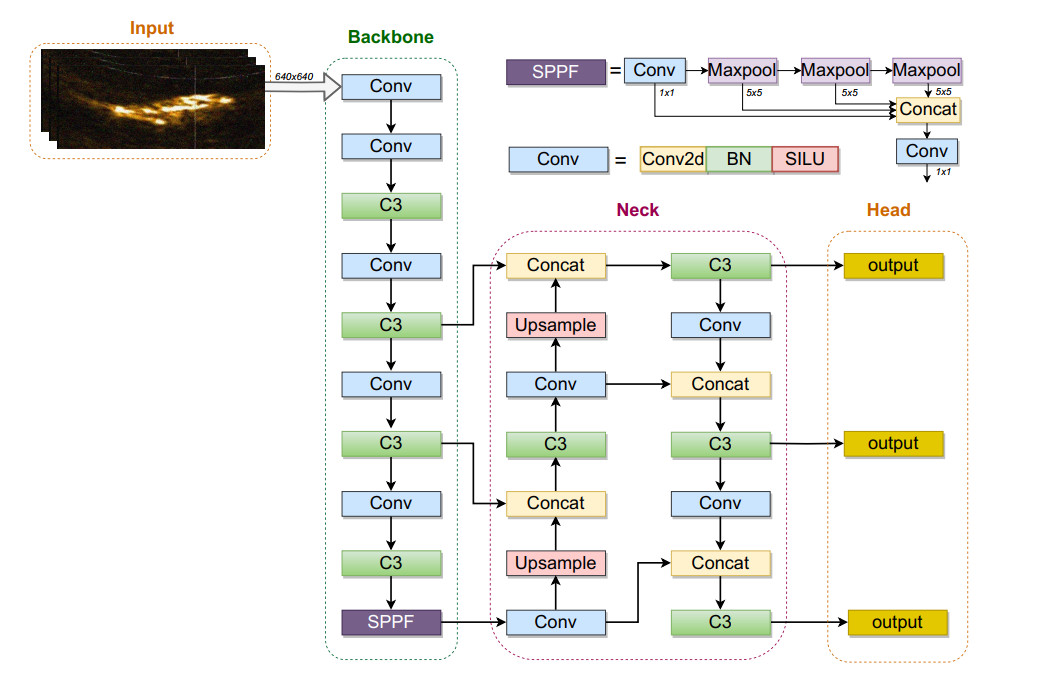
Fish stock assessment is crucial for sustainable marine fisheries management in rangeland ecosystems. To address the challenges posed by the overfishing of offshore fish species and facilitate comprehensive deep-sea resource evaluation, this paper introduces an improved fish sonar image detection algorithm based on the you only look once algorithm, version 5 (YOLOv5). Sonar image noise often results in blurred targets and indistinct features, thereby reducing the precision of object detection. Thus, a C3N module is incorporated into the neck component, where depth-separable convolution and an inverse bottleneck layer structure are integrated to lessen feature information loss during downsampling and forward propagation. Furthermore, lowercase shallow feature layer is introduced in the network prediction layer to enhance feature extraction for pixels larger than $ 4 \times 4 $. Additionally, normalized weighted distance based on a Gaussian distribution is combined with Intersection over Union (IoU) during gradient descent to improve small target detection and mitigate the IoU's scale sensitivity. Finally, traditional non-maximum suppression (NMS) is replaced with soft-NMS, reducing missed detections due to occlusion and overlapping fish targets that are common in sonar datasets. Experiments show that the improved model surpasses the original model and YOLOv3 with gains in precision, recall and mean average precision of 2.3%, 4.7% and 2.7%, respectively, and 2.5%, 6.3% and 6.7%, respectively. These findings confirm the method's effectiveness in raising sonar image detection accuracy, which is consistent with model comparisons. Given Unmanned Underwater Vehicle advancements, this method holds the potential to support fish culture decision-making and facilitate fish stock resource assessment.
Citation: Bowen Xing, Min Sun, Minyang Ding, Chuang Han. Fish sonar image recognition algorithm based on improved YOLOv5[J]. Mathematical Biosciences and Engineering, 2024, 21(1): 1321-1341. doi: 10.3934/mbe.2024057
Fish stock assessment is crucial for sustainable marine fisheries management in rangeland ecosystems. To address the challenges posed by the overfishing of offshore fish species and facilitate comprehensive deep-sea resource evaluation, this paper introduces an improved fish sonar image detection algorithm based on the you only look once algorithm, version 5 (YOLOv5). Sonar image noise often results in blurred targets and indistinct features, thereby reducing the precision of object detection. Thus, a C3N module is incorporated into the neck component, where depth-separable convolution and an inverse bottleneck layer structure are integrated to lessen feature information loss during downsampling and forward propagation. Furthermore, lowercase shallow feature layer is introduced in the network prediction layer to enhance feature extraction for pixels larger than $ 4 \times 4 $. Additionally, normalized weighted distance based on a Gaussian distribution is combined with Intersection over Union (IoU) during gradient descent to improve small target detection and mitigate the IoU's scale sensitivity. Finally, traditional non-maximum suppression (NMS) is replaced with soft-NMS, reducing missed detections due to occlusion and overlapping fish targets that are common in sonar datasets. Experiments show that the improved model surpasses the original model and YOLOv3 with gains in precision, recall and mean average precision of 2.3%, 4.7% and 2.7%, respectively, and 2.5%, 6.3% and 6.7%, respectively. These findings confirm the method's effectiveness in raising sonar image detection accuracy, which is consistent with model comparisons. Given Unmanned Underwater Vehicle advancements, this method holds the potential to support fish culture decision-making and facilitate fish stock resource assessment.

| [1] | FAO, The state of world fisheries and aquaculture 2016: Opportunities and challenges, Rome: Food and Agriculture Organization of the United Nations, (2007). |
| [2] | FAO, The state of world fisheries and aquaculture 2022: Towards blue transformation, Food and Agriculture Organization of the United Nations, (2022). |
| [3] | FAO, The State of World Fisheries and Aquaculture, Food and Agriculture Organization of the United Nations, (2018). |
| [4] | J. Álvarez, J. M. F. Real, F. Guarner, M. Gueimonde, J. M. Rodríguez, M. S. de Pipaon, et al., Microbiota intestinal y salud, Gastroenterología y Hepatología, 44 (2021), 519–535. https://doi.org/10.1016/j.gastrohep.2021.01.009 |
| [5] |
R. Lulijwa, E. J. Rupia, A. C. Alfaro, Antibiotic use in aquaculture, policies and regulation, health and environmental risks: A review of the top 15 major producers, Rev. Aquacult., 12 (2020), 640–663. https://doi.org/10.1111/raq.12344 doi: 10.1111/raq.12344

|
| [6] | J. D. Sachs, C. Kroll, G. Lafortune, G. Fuller, F. Woelm, Sustainable Development Report 2022, Cambridge University Press, 2022. https://doi.org/10.1017/9781009210058 |
| [7] | National oceanic and atmospheric administration, Natl. Weather Serv., (2012), 1950–2011. |
| [8] | F. Yang, Z. Du, Z. Wu, Object recognizing on sonar image based on histogram and geometric feature, Mar. Sci. Bull. Tianjin, 25 (2006), 64. |
| [9] | R. Girshick, J. Donahue, T. Darrell, J. Malik, Rich feature hierarchies for accurate object detection and semantic segmentation, in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, (2014), 580–587. https://doi.org/10.1109/CVPR.2014.81 |
| [10] | R. Girshick, Fast R-CNN, in Proceedings of the IEEE International Conference on Computer Vision, (2015), 1440–1448. https://doi.org/10.1109/ICCV.2015.169 |
| [11] | S. Ren, K. He, R. Girshick, J. Sun, Faster R-CNN: Towards real-time object detection with region proposal networks, Adv. Neural Inf. Process. Syst., 28 (2015). |
| [12] |
K. He, X. Zhang, S. Ren, J. Sun, Spatial pyramid pooling in deep convolutional networks for visual recognition, IEEE Trans. Pattern Anal. Machine Intell., 37 (2015), 1904–1916. https://doi.org/10.1109/TPAMI.2015.2389824 doi: 10.1109/TPAMI.2015.2389824
|
| [13] | K. He, G. Gkioxari, P. Dollár, R. Girshick, Mask R-CNN, in Proceedings of the IEEE International Conference on Computer Vision, (2017), 2961–2969. |
| [14] | J. Redmon, S. Divvala, R. Girshick, A. Farhadi, You only look once: Unified, real-time object detection, in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, (2016), 779–788. https://doi.org/10.1109/CVPR.2016.91 |
| [15] | J. Redmon, A. Farhadi, Yolo9000: Better, faster, stronger, in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, (2017), 7263–7271. |
| [16] | J. Redmon, A. Farhadi, Yolov3: An incremental improvement, preprint, arXiv: 1804.02767. |
| [17] | A. Bochkovskiy, C. Y. Wang, H. Y. M. Liao, Yolov4: Optimal speed and accuracy of object detection, preprint, arXiv: 2004.10934. |
| [18] | C. Li, L. Li, H. Jiang, K. Weng, Y. Geng, L. Li, et al., Yolov6: A single-stage object detection framework for industrial applications, preprint, arXiv: 2209.02976. |
| [19] | C. Y. Wang, A. Bochkovskiy, H. Y. M. Liao, Yolov7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors, in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, (2023), 7464–7475. |
| [20] |
K. Tong, Y. Wu, F. Zhou, Recent advances in small object detection based on deep learning: A review, Image Vision Comput., 97 (2020), 103910. https://doi.org/10.1016/j.imavis.2020.103910 doi: 10.1016/j.imavis.2020.103910
|
| [21] |
I. Karoui, I. Quidu, M. Legris, Automatic sea-surface obstacle detection and tracking in forward-looking sonar image sequences, IEEE Trans. Geosci. Remote Sens., 53 (2015), 4661–4669. https://doi.org/10.1109/TGRS.2015.2405672 doi: 10.1109/TGRS.2015.2405672
|
| [22] |
X. Wang, Q. Li, J. Yin, X. Han, W. Hao, An adaptive denoising and detection approach for underwater sonar image, Remote Sens., 11 (2019), 396. https://doi.org/10.3390/rs11040396 doi: 10.3390/rs11040396
|
| [23] |
T. Yulin, S. Jin, G. Bian, Y. Zhang, Shipwreck target recognition in side-scan sonar images by improved yolov3 model based on transfer learning, IEEE Access, 8 (2020), 173450–173460. https://doi.org/10.1109/ACCESS.2020.3024813 doi: 10.1109/ACCESS.2020.3024813
|
| [24] |
Y. Yu, J. Zhao, Q. Gong, C. Huang, G. Zheng, J. Ma, Real-time underwater maritime object detection in side-scan sonar images based on transformer-yolov5, Remote Sens., 13 (2021), 3555. https://doi.org/10.3390/rs13183555 doi: 10.3390/rs13183555
|
| [25] |
T. Jin, X. Yang, Monotonicity theorem for the uncertain fractional differential equation and application to uncertain financial market, Math. Comput. Simul., 190 (2021), 203–221. https://doi.org/10.1016/j.matcom.2021.05.018 doi: 10.1016/j.matcom.2021.05.018
|
| [26] |
J. Yang, Y. Zhang, T. Jin, Z. Lei, Y. Todo, S. Gao, Maximum lyapunov exponent-based multiple chaotic slime mold algorithm for real-world optimization, Sci. Rep., 13 (2023), 12744. https://doi.org/10.1038/s41598-023-40080-1 doi: 10.1038/s41598-023-40080-1
|
| [27] | S. Liu, L. Qi, H. Qin, J. Shi, J. Jia, Path aggregation network for instance segmentation, in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, (2018), 8759–8768. https://doi.org/10.1109/CVPR.2018.00913 |
| [28] | T. Y. Lin, P. Dollár, R. Girshick, K. He, B. Hariharan, S. Belongie, Feature pyramid networks for object detection, in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, (2017), 2117–2125. |
| [29] | Z. Liu, H. Mao, C. Y. Wu, C. Feichtenhofer, T. Darrell, S. Xie, A convnet for the 2020s, in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, (2022), 11976–11986. https://doi.org/10.1109/CVPR52688.2022.01167 |
| [30] | K. He, X. Zhang, S. Ren, J. Sun, Deep residual learning for image recognition, in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, (2016), 770–778. |
| [31] | Z. Liu, Y. Lin, Y. Cao, H. Hu, Y. Wei, Z. Zhang, et al., Swin transformer: Hierarchical vision transformer using shifted windows, in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2021, 10012–10022. https://doi.org/10.1109/ICCV48922.2021.00986 |
| [32] | M. Sandler, A. Howard, M. Zhu, A. Zhmoginov, L. C. Chen, Mobilenetv2: Inverted residuals and linear bottlenecks, in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, (2018), 4510–4520. https://doi.org/10.1109/CVPR.2018.00474 |
| [33] | J. Wang, C. Xu, W. Yang, L. Yu, A normalized gaussian wasserstein distance for tiny object detection, preprint, arXiv: 2110.13389. |
| [34] | N. Bodla, B. Singh, R. Chellappa, L. S. Davis, Soft-nms–improving object detection with one line of code, in Proceedings of the IEEE International Conference on Computer Vision, 2017, 5561–5569. https://doi.org/10.1109/ICCV.2017.593 |
| [35] | A. Kumar, S. S. Sodhi, Comparative analysis of gaussian filter, median filter and denoise autoenocoder, in 2020 7th International Conference on Computing for Sustainable Global Development, (2020), 45–51. https://doi.org/10.23919/INDIACom49435.2020.9083712 |









Figures(10) / Tables(4)

Bowen Xing, Min Sun, Minyang Ding, Chuang Han. Fish sonar image recognition algorithm based on improved YOLOv5[J]. Mathematical Biosciences and Engineering, 2024, 21(1): 1321-1341. doi: 10.3934/mbe.2024057







 DownLoad:
DownLoad: