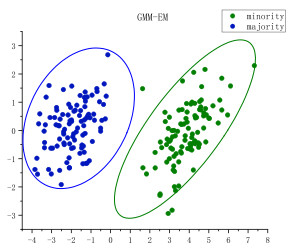
Imbalanced data classification has been a major topic in the machine learning community. Different approaches can be taken to solve the issue in recent years, and researchers have given a lot of attention to data level techniques and algorithm level. However, existing methods often generate samples in specific regions without considering the complexity of imbalanced distributions. This can lead to learning models overemphasizing certain difficult factors in the minority data. In this paper, a Monte Carlo sampling algorithm based on Gaussian Mixture Model (MCS-GMM) is proposed. In MCS-GMM, we utilize the Gaussian mixed model to fit the distribution of the imbalanced data and apply the Monte Carlo algorithm to generate new data. Then, in order to reduce the impact of data overlap, the three sigma rule is used to divide data into four types, and the weight of each minority class instance based on its neighbor and probability density function. Based on experiments conducted on Knowledge Extraction based on Evolutionary Learning datasets, our method has been proven to be effective and outperforms existing approaches such as Synthetic Minority Over-sampling TEchnique.
Citation: Gang Chen, Binjie Hou, Tiangang Lei. A new Monte Carlo sampling method based on Gaussian Mixture Model for imbalanced data classification[J]. Mathematical Biosciences and Engineering, 2023, 20(10): 17866-17885. doi: 10.3934/mbe.2023794
Imbalanced data classification has been a major topic in the machine learning community. Different approaches can be taken to solve the issue in recent years, and researchers have given a lot of attention to data level techniques and algorithm level. However, existing methods often generate samples in specific regions without considering the complexity of imbalanced distributions. This can lead to learning models overemphasizing certain difficult factors in the minority data. In this paper, a Monte Carlo sampling algorithm based on Gaussian Mixture Model (MCS-GMM) is proposed. In MCS-GMM, we utilize the Gaussian mixed model to fit the distribution of the imbalanced data and apply the Monte Carlo algorithm to generate new data. Then, in order to reduce the impact of data overlap, the three sigma rule is used to divide data into four types, and the weight of each minority class instance based on its neighbor and probability density function. Based on experiments conducted on Knowledge Extraction based on Evolutionary Learning datasets, our method has been proven to be effective and outperforms existing approaches such as Synthetic Minority Over-sampling TEchnique.

| [1] |
C. Phua, D. Alahakoon, V. Lee, Minority report in fraud detection: classification of skewed data, ACM SIGKDD Explor. Newsl., 6 (2004), 50–59. https://doi.org/10.1145/1007730.1007738 doi: 10.1145/1007730.1007738

|
| [2] |
B. Krawczyk, M. Galar, L. Jelen, F. Herrera, Evolutionary undersampling boosting for imbalanced classification of breast cancer malignancy, Appl. Soft Comput., 38 (2016), 714–726. https://doi.org/10.1016/j.asoc.2015.08.060 doi: 10.1016/j.asoc.2015.08.060
|
| [3] |
J. Alqatawna, H. Faris, K. Jaradat, M. Al-Zewairi, O. Adwan, Improving knowledge based spam detection methods: The effect of malicious related features in imbalance data distribution, Int. J. Commun. Network Syst. Sci., 8 (2015), 118–129. https://doi.org/10.4236/ijcns.2015.85014 doi: 10.4236/ijcns.2015.85014
|
| [4] |
N. Japkowicz, S. Stephen, The class imbalance problem: A systematic study, Intell. Data Anal., 6 (2002), 429–449. https://doi.org/10.3233/IDA-2002-6504 doi: 10.3233/IDA-2002-6504
|
| [5] | X. Fan, H. Yu, GAMC: An oversampling method based on genetic algorithm and monte carlo method to solve the class imbalance issue in industry, in 2022 International Conference on Industrial IoT, Big Data and Supply Chain (IIoTBDSC), (2022), 127–132. https://doi.org/10.1109/IIoTBDSC57192.2022.00033 |
| [6] | F. Zhang, G. Liu, Z. Li, C. Yan, C. Jang, GMM-based undersampling and its application for credit card fraud detection, in 2019 International Joint Conference on Neural Networks (IJCNN), (2019), 1–8. https://doi.org/10.1109/IJCNN.2019.8852415 |
| [7] |
Y. Yan, Y. Zhu, R. Liu, Y. Zhang, Y. Zhang, L. Zhang, Spatial distribution-based imbalanced undersampling, IEEE Trans. Knowl. Data Eng., 35 (2023), 6376–6391. https://doi.org/10.1109/TKDE.2022.3161537 doi: 10.1109/TKDE.2022.3161537
|
| [8] |
H. Zhu, M. Zhou, G. Liu, Y. Xie, S. Liu, C. Guo, NUS: Noisy-sample-removed undersampling scheme for imbalanced classification and application to credit card fraud detection, IEEE Trans. Comput. Soc. Syst., (2023), 1–12. https://doi.org/10.1109/TCSS.2023.3243925 doi: 10.1109/TCSS.2023.3243925
|
| [9] |
N. V. Chawla, K. W. Bowyer, L. O. Hall, W. P. Kegelmeyer, SMOTE: Synthetic minority over-sampling technique, J. Artif. Intell. Res., 16 (2002), 321–357. https://doi.org/10.1613/jair.953 doi: 10.1613/jair.953
|
| [10] |
A. Fernández, S. Garcia, F. Herrera, N. V. Chawla, SMOTE for learning from imbalanced data: progress and challenges, marking the 15-year anniversary, J. Artif. Intell. Res., 61 (2018), 863–905. https://doi.org/10.1613/jair.1.11192 doi: 10.1613/jair.1.11192
|
| [11] | H. He, Y. Bai, E. A. Garcia, S. Li, ADASYN: Adaptive synthetic sampling approach for imbalanced learning, in 2008 IEEE International Joint Conference on Neural Networks (IEEE World Congress on Computational Intelligence), (2008), 1322–1328. https://doi.org/10.1109/IJCNN.2008.4633969 |
| [12] | H. Han, W. Wang, B. Mao, Borderline-SMOTE: A new over-sampling method in imbalanced data sets learning, in International Conference on Intelligent Computing, 3644 (2005), 878–887. https://doi.org/10.1007/11538059_91 |
| [13] |
G. Douzas, F. Bacao, F. Last, Improving imbalanced learning through a heuristic oversampling method based on k-means and SMOTE, Inf. Sci., 465 (2018), 1–20. https://doi.org/10.1016/j.ins.2018.06.056 doi: 10.1016/j.ins.2018.06.056
|
| [14] |
Y. Yan, Y. Jiang, Z. Zheng, C. Yu, Y. Zhang, Y. Zhang, LDAS: Local density-based adaptive sampling for imbalanced data classification, Expert Syst. Appl., 191 (2022), 116213. https://doi.org/10.1016/j.eswa.2021.116213 doi: 10.1016/j.eswa.2021.116213
|
| [15] |
Y. Xie, M. Qiu, H. Zhang, L. Peng, Z. Chen, Gaussian distribution based oversampling for imbalanced data classification, IEEE Trans. Knowl. Data Eng., 34 (2022), 667–669. https://doi.org/10.1109/TKDE.2020.2985965 doi: 10.1109/TKDE.2020.2985965
|
| [16] | H. Bhagwani, S. Agarwal, A. Kodipalli, R. J. Martis, Targeting class imbalance problem using GAN, in 2021 5th International Conference on Electrical, Electronics, Communication, Computer Technologies and Optimization Techniques (ICEECCOT), (2021), 318–322. https://doi.org/10.1109/ICEECCOT52851.2021.9708011 |
| [17] |
S. Maldonado, C. Vairetti, A. Fernandez, F. Herrera, FW-SMOTE: A feature-weighted oversampling approach for imbalanced classification, Pattern Recognit., 124 (2022), 108511. https://doi.org/10.1016/j.patcog.2021.108511 doi: 10.1016/j.patcog.2021.108511
|
| [18] |
E. Kaya, S. Korkmaz, M. A. Sahman, A. C. Cinar, DEBOHID: A differential evolution based oversampling approach for highly imbalanced datasets, Expert Syst. Appl., 169 (2021), 794–801. https://doi.org/10.1016/j.eswa.2020.114482 doi: 10.1016/j.eswa.2020.114482
|
| [19] |
W. Xie, G. Liang, Z. Dong, B. Tan, B. Zhang, An improved oversampling algorithm based on the samples' selection strategy for classifying imbalanced data, Math. Probl. Eng., 2019 (2019), 3526539. https://doi.org/10.1155/2019/3526539 doi: 10.1155/2019/3526539
|
| [20] |
L. Peng, H. Zhang, B. Yang, Y. Chen, A new approach for imbalanced data classification based on data gravitation, Inf. Sci., 288 (2014), 347–373. https://doi.org/10.1016/j.ins.2014.04.046 doi: 10.1016/j.ins.2014.04.046
|
| [21] |
F. Rahmati, H. Nezamabadi-Pour, B. Nikpour, A gravitational density-based mass sharing method for imbalanced data classification, SN Appl. Sci., 2 (2020). https://doi.org/10.1007/s42452-020-2039-2 doi: 10.1007/s42452-020-2039-2
|
| [22] |
M. Koziarski, B. Krawczyk, M. Wozniak, Radial-Based oversampling for noisy imbalanced data classification, Neurocomputing, 343 (2019), 19–33. https://doi.org/10.1016/j.neucom.2018.04.089 doi: 10.1016/j.neucom.2018.04.089
|
| [23] | C. Bunkhumpornpat, K. Sinapiromsaran, C. Lursinsap, Safe-Level-SMOTE: Safe-Level-Synthetic Minority Over-Sampling TEchnique for handling the class imbalanced problem, in Pacific-Asia Conference on Knowledge Discovery and Data Mining, 5476 (2009), 475–482. https://doi.org/10.1007/978-3-642-01307-2_43 |
| [24] |
Y. Sun, L. Cai, B. Liao, W. Zhu, J. Xu, A robust oversampling approach for class imbalance problem with small disjuncts, IEEE Trans. Knowl. Data Eng., 35 (2023), 5550–5562. https://doi.org/10.1109/TKDE.2022.3161291 doi: 10.1109/TKDE.2022.3161291
|
| [25] |
S. Yin, X. Zhu, C. Jing, Fault detection based on a robust one class support vector machine, Neurocomputing, 145 (2014), 263–268. https://doi.org/10.1016/j.neucom.2014.05.035 doi: 10.1016/j.neucom.2014.05.035
|
| [26] |
B. Scholkopf, J. C. Platt, J. Shawe-Taylor, A. J. Smola, R. C. Williamson, Estimating the support of a high-dimensional distribution, Neural Comput., 13 (2001), 1443–1471. https://doi.org/10.1162/089976601750264965 doi: 10.1162/089976601750264965
|
| [27] |
R. Barandela, R. M. Valdovinos, J. S. Sánchez, New applications of ensembles of classifiers, Pattern Anal. Appl., 6 (2003), 245–256. https://doi.org/10.1007/s10044-003-0192-z doi: 10.1007/s10044-003-0192-z
|
| [28] | C. Li, Classifying imbalanced data using a bagging ensemble variation (BEV), in Proceedings of the 45th annual southeast regional conference, (2007), 203–208. https://doi.org/10.1145/1233341.1233378 |
| [29] |
S. Hido, H. Kashima, Y. Takahashi, Roughly balanced bagging for imbalanced data, Stat. Anal. Data Min., 2 (2009), 412–426. https://doi.org/10.1002/sam.10061 doi: 10.1002/sam.10061
|
| [30] |
B. Chen, S. Xia, Z. Chen, B. Wang, G. Wang, RSMOTE: A self-adaptive robust SMOTE for imbalanced problems with label noise, Inf. Sci., 553 (2021), 397–428. https://doi.org/10.1016/j.ins.2020.10.013 doi: 10.1016/j.ins.2020.10.013
|
| [31] |
H. K. Lee, S. B. Kim, An overlap-sensitive margin classifier for imbalanced and overlapping data, Expert Syst. Appl., 98 (2018), 72–83. https://doi.org/10.1016/j.eswa.2018.01.008 doi: 10.1016/j.eswa.2018.01.008
|
| [32] |
J. Lu, A. Liu, F. Dong, F. Gu, J. Gama, G. Zhang, Learning under concept drift: A review, IEEE Trans. Knowl. Data Eng., 31 (2019), 2346–2363. https://doi.org/10.1109/TKDE.2018.2876857 doi: 10.1109/TKDE.2018.2876857
|
| [33] | M. K. Paul, B. Pal, Gaussian mixture based semi supervised boosting for imbalanced data classification, in 2016 2nd International Conference on Electrical, Computer & Telecommunication Engineering (ICECTE), (2016). |
| [34] |
Y. Xie, L. Peng, Z. Chen, B. Yang, H. Zhang, H. Zhang, Generative learning for imbalanced data using the Gaussian mixed model, Appl. Soft Comput., 79 (2019), 439–451. https://doi.org/10.1016/j.asoc.2019.03.056 doi: 10.1016/j.asoc.2019.03.056
|
| [35] |
A. Shapiro, Monte carlo sampling methods, Handb. Oper. Res. Manage. Sci., 10 (2003), 353–425. https://doi.org/10.1016/S0927-0507(03)10006-0 doi: 10.1002/wics.1314
|
| [36] |
D. P. Kroese, T. Brereton, T. Taimre, Z. I. Botev, Why the Monte Carlo method is so important today, WIREs Comput. Stat., 6 (2014), 386–392. https://doi.org/10.1002/wics.1314 doi: 10.1002/wics.1314
|
| [37] |
S. Bej, N. Davtyan, M. Wolfien, M. Nassar, O. Wolkenhauer, LoRAS: An oversampling approach for imbalanced datasets, Mach. Learn., 110 (2021), 279–301. https://doi.org/10.1007/s10994-020-05913-4 doi: 10.1007/s10994-020-05913-4
|
 mbe-20-10-794 supplementary.zip mbe-20-10-794 supplementary.zip |
 |




Figures(5) / Tables(6)

Gang Chen, Binjie Hou, Tiangang Lei. A new Monte Carlo sampling method based on Gaussian Mixture Model for imbalanced data classification[J]. Mathematical Biosciences and Engineering, 2023, 20(10): 17866-17885. doi: 10.3934/mbe.2023794







 DownLoad:
DownLoad: