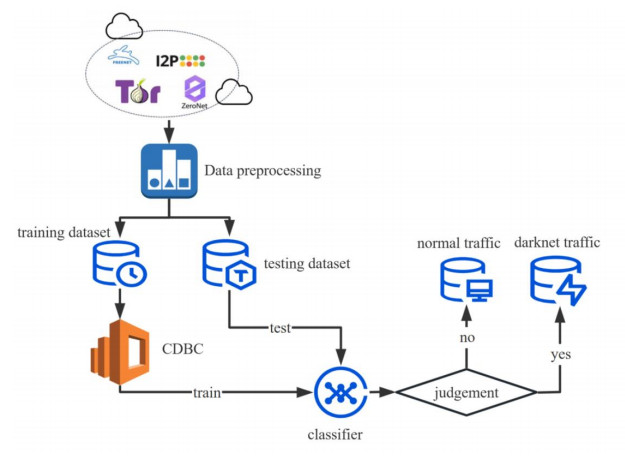
With the development of the Internet, people have paid more attention to privacy protection, and privacy protection technology is widely used. However, it also breeds the darknet, which has become a tool that criminals can exploit, especially in the fields of economic crime and military intelligence. The darknet detection is becoming increasingly important; however, the darknet traffic is seriously unbalanced. The detection is difficult and the accuracy of the detection methods needs to be improved. To overcome these problems, we first propose a novel learning method. The method is the Chebyshev distance based Between-class learning (CDBC), which can learn the spatial distribution of the darknet dataset, and generate "gap data". The gap data can be adopted to optimize the distribution boundaries of the dataset. Second, a novel darknet traffic detection method is proposed. We test the proposed method on the ISCXTor 2016 dataset and the CIC-Darknet 2020 dataset, and the results show that CDBC can help more than 10 existing methods improve accuracy, even up to 99.99%. Compared with other sampling methods, CDBC can also help the classifiers achieve higher recall.
Citation: Binjie Song, Yufei Chang, Minxi Liao, Yuanhang Wang, Jixiang Chen, Nianwang Wang. CDBC: A novel data enhancement method based on improved between-class learning for darknet detection[J]. Mathematical Biosciences and Engineering, 2023, 20(8): 14959-14977. doi: 10.3934/mbe.2023670
With the development of the Internet, people have paid more attention to privacy protection, and privacy protection technology is widely used. However, it also breeds the darknet, which has become a tool that criminals can exploit, especially in the fields of economic crime and military intelligence. The darknet detection is becoming increasingly important; however, the darknet traffic is seriously unbalanced. The detection is difficult and the accuracy of the detection methods needs to be improved. To overcome these problems, we first propose a novel learning method. The method is the Chebyshev distance based Between-class learning (CDBC), which can learn the spatial distribution of the darknet dataset, and generate "gap data". The gap data can be adopted to optimize the distribution boundaries of the dataset. Second, a novel darknet traffic detection method is proposed. We test the proposed method on the ISCXTor 2016 dataset and the CIC-Darknet 2020 dataset, and the results show that CDBC can help more than 10 existing methods improve accuracy, even up to 99.99%. Compared with other sampling methods, CDBC can also help the classifiers achieve higher recall.

| [1] |
A. Montieri, D. Ciuonzo, G. Aceto, A. Pescapé, Anonymity services tor, i2p, jondonym: classifying in the dark (web), IEEE Trans. Dependable Secure Comput., 17 (2018), 662−675. https://doi.org/10.1109/TDSC.2018.2804394 doi: 10.1109/TDSC.2018.2804394

|
| [2] |
Y. Gao, J. Lin, J. Xie, Z. Ning, A real-time defect detection method for digital signal processing of industrial inspection applications, IEEE Trans. Ind. Inf., 17 (2021), 3450−3459. https://doi.org/10.1109/TII.2020.3013277 doi: 10.1109/TII.2020.3013277
|
| [3] |
W. Wang, N. Kumar, J. Chen, Z. Gong, X. Kong, W. Wei, et al., Realizing the potential of the internet of things for smart tourism with 5G and AI, IEEE Network, 34 (2020), 295−301. https://doi.org/10.1109/MNET.011.2000250 doi: 10.1109/MNET.011.2000250
|
| [4] | R. Dingledine, N. Mathewson, P. Syverson, Tor: The second-generation onion router, in 13th USENIX Security Symposium, 2004 (2004), 303−320. https://doi.org/10.1016/0016-0032(45)90142-6 |
| [5] | A. Cuzzocrea, F. Martinelli, F. Mercaldo, G. Vercelli, Tor traffic analysis and detection via machine learning techniques, in 2017 IEEE International Conference on Big Data, 2017 (2017), 4474−4480. https://doi.org/10.1109/BigData.2017.8258487 |
| [6] |
R. Jansen, M. Juarez, R. Galvez, T. Elahi, C. Diaz, Inside job: Applying traffic analysis to measure tor from within, Network Distributed Syst. Security, 2018 (2018). http://dx.doi.org/10.14722/ndss.2018.23261 doi: 10.14722/ndss.2018.23261
|
| [7] | H. Yin, Y. He, I2P anonymous traffic detection and identification, in 2019 5th International Conference on Advanced Computing & Communication Systems, 2019 (2019), 157−162. https://doi.org/10.1109/ICACCS.2019.8728517 |
| [8] |
I. Clarke, O. Sandberg, B. Wiley, Freenet: A distributed anonymous information storage and retrieval system, Des. Privacy Enhancing Technol., 2001 (2001), 46−66. https://doi.org/10.1007/3-540-44702-4_4 doi: 10.1007/3-540-44702-4_4
|
| [9] |
S. Lee, S. H. Shin, B. H. Roh, Classification of freenet traffic flow based on machine learning, J. Commun., 13 (2018), 654−660. https://doi.org/10.12720/jcm.13.11.654-660 doi: 10.12720/jcm.13.11.654-660
|
| [10] | S. Wang, Y. Gao, J. Shi, X. Wang, C. Zhao, Z. Yin, Look deep into the new deep network: A measurement study on the ZeroNet, in Computational Science-ICCS 2020, (2020), 595−608. https://doi.org/10.1007/978-3-030-50371-0_44 |
| [11] | M. Wang, X. Wang, J. Shi, Q. Tan, Y. Gao, M. Chen, et al., Who are in the darknet measurement and analysis of darknet person attributes, in 2018 IEEE Third International Conference on Data Science in Cyberspace, 2018 (2018), 948−955. https://doi.org/10.1109/DSC.2018.00151 |
| [12] |
C. Fachkha, M. Debbabi, Darknet as a source of cyber intelligence: Survey, taxonomy, and characterization, IEEE Commun. Surv. Tutorials, 18 (2015), 1197−1227. https://doi.org/10.1109/COMST.2015.2497690 doi: 10.1109/COMST.2015.2497690
|
| [13] | G. Draper-Gil, A. H. Lashkari, M. S. I. Mamun, A. A. Ghorbani, Characterization of encrypted and VPN traffic using time-related features, in Proceedings of the 2nd International Conference on Information Systems Security and Privacy, 1 (2016), 407−414. https://doi.org/10.5220/0005740704070414 |
| [14] | Y. Hu, F. Zou, L. Li, P. Yi, Traffic classification of user behaviors in tor, i2p, zeronet, freenet, in 2020 IEEE 19th International Conference on Trust, Security and Privacy in Computing and Communications, (2020), 418–424. https://doi.org/10.1109/TrustCom50675.2020.00064 |
| [15] |
R. Rawat, V. Mahor, S. Chirgaiya, R. N. Shaw, A. Ghosh, Analysis of darknet traffic for criminal activities detection using TF-IDF and light gradient boosted machine learning algorithm, Innovations Electr. Electron. Eng., 2021 (2021), 671−681. https://doi.org/10.1007/978-981-16-0749-3_53 doi: 10.1007/978-981-16-0749-3_53
|
| [16] |
Q. A. Al-Haija, M. Krichen, W. A. Elhaija, Machine-learning-based darknet traffic detection system for IoT applications, Electronics, 11 (2022), 556. https://doi.org/10.3390/electronics11040556 doi: 10.3390/electronics11040556
|
| [17] | A. H. Lashkari, G. Kaur, A. Rahali, DIDarknet: A contemporary approach to detect and characterize the darknet traffic using deep image learning, in 2020 the 10th International Conference on Communication and Network Security, (2020), 1−13. https://doi.org/10.1145/3442520.3442521 |
| [18] | C. Liu, L. He, G. Xiong, Z. Cao, Z. Li, FS-Net: A flow sequence network for encrypted traffic classification, in IEEE INFOCOM 2019-IEEE Conference On Computer Communications, (2019), 1171−1179. https://doi.org/10.1109/INFOCOM.2019.8737507 |
| [19] |
M. Lotfollahi, M. J. Siavoshani, R. S. H. Zade, M. Saberian, Deep packet: A novel approach for encrypted traffic classification using deep learning, Soft Comput., 24 (2020), 1999−2012. https://doi.org/10.1007/s00500-019-04030-2 doi: 10.1007/s00500-019-04030-2
|
| [20] | X. Wang, S. Chen, J. Su, App-Net: A hybrid neural network for encrypted mobile traffic classification, in IEEE INFOCOM 2020-IEEE Conference on Computer Communications Workshops, (2020), 424−429. https://doi.org/10.1109/INFOCOMWKSHPS50562.2020.9162891 |
| [21] |
M. B. Sarwar, M. K. Hanif, R. Talib, M. Younas, M. U. Sarwar, DarkDetect: Darknet traffic detection and categorization using modified convolution-long short-term memory, IEEE Access, 9 (2021), 113705−113713. https://doi.org/10.1109/ACCESS.2021.3105000 doi: 10.1109/ACCESS.2021.3105000
|
| [22] |
W. Cai, L. Xie, W. Yang, Y. Li, Y. Gao, T. Wang, DFTNet: Dual-path feature transfer network for weakly supervised medical image segmentation, IEEE/ACM Trans. Comput. Biol. Bioinf., 2022 (2022), 1−12. https://doi.org/10.1109/TCBB.2022.3198284 doi: 10.1109/TCBB.2022.3198284
|
| [23] |
X. Xie, Y. Li, Y. Gao, C. Wu, P. Gao, B. Song, et al., Weakly supervised object localization with soft guidance and channel erasing for auto labelling in autonomous driving systems, ISA Trans., 132 (2023), 39−51. https://doi.org/10.1016/j.isatra.2022.08.003 doi: 10.1016/j.isatra.2022.08.003
|
| [24] |
W. Wang, J. Chen, J. Wang, J. Chen, J. Liu, Z. Gong, Trust-enhanced collaborative filtering for personalized point of interests recommendation, IEEE Trans. Industrial Inf., 16 (2020), 6124−6132. https://doi.org/10.1109/TII.2019.2958696 doi: 10.1109/TII.2019.2958696
|
| [25] | Y. Tokozume, Y. Ushiku, T. Harada, Between-class learning for image classification, in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2018 (2018), 5486−5494, arXiv.1711.10284 |
| [26] |
Y. Gao, J. Chen, H. Miao, B. Song, Y. Lu, W. Pan, Self-learning spatial distribution-based intrusion detection for industrial cyber-physical systems, IEEE Trans. Comput. Social Syst., 9 (2022), 1693−1702. https://doi.org/10.1109/TCSS.2021.3135586 doi: 10.1109/TCSS.2021.3135586
|
| [27] | A. H. Lashkari, G. Draper-Gil, M. S. I. Mamun, A. A. Ghorbani, Characterization of tor traffic using time based features, in Proceedings of the 3rd International Conference on Information Systems Security and Privacy, 2017 (2017), 253−262. https://doi.org/10.5220/0006105602530262 |
| [28] | F. R. Torres, J. A. Carrasco-Ochoa, J. F. Martínez-Trinidad, SMOTE-D a deterministic version of SMOTE, in Mexican Conference on Pattern Recognition, 9703 (2016), 177−188. https://doi.org/10.1007/978-3-319-39393-3_18 |
| [29] |
H. Lee, J. Kim, S. Kim, Gaussian-based SMOTE algorithm for solving skewed class distributions, Int. J. Fuzzy Logic Intell. Syst., 17 (2017), 229−234. https://doi.org/10.5391/IJFIS.2017.17.4.229 doi: 10.5391/IJFIS.2017.17.4.229
|





Figures(6) / Tables(5)

Binjie Song, Yufei Chang, Minxi Liao, Yuanhang Wang, Jixiang Chen, Nianwang Wang. CDBC: A novel data enhancement method based on improved between-class learning for darknet detection[J]. Mathematical Biosciences and Engineering, 2023, 20(8): 14959-14977. doi: 10.3934/mbe.2023670







 DownLoad:
DownLoad: