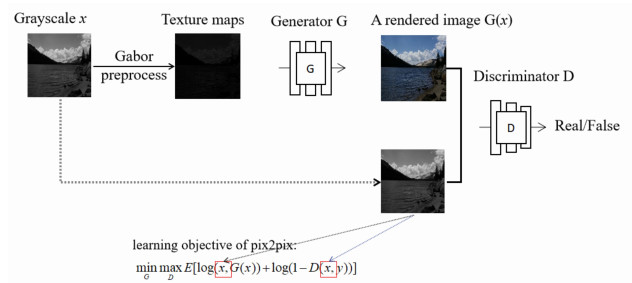
In recent years, with the development of deep learning, image color rendering method has become a research hotspot once again. To overcome the detail problems of color overstepping and boundary blurring in the robust image color rendering method, as well as the problems of unstable training based on generative adversarial networks, we propose an color rendering method using Gabor filter based improved pix2pix for robust image. Firstly, the multi-direction/multi-scale selection characteristic of Gabor filter is used to preprocess the image to be rendered, which can retain the detailed features of the image while preprocessing to avoid the loss of features. Moreover, among the Gabor texture feature maps with 6 scales and 4 directions, the texture map with the scale of 7 and the direction of 0° has the comparable rendering performance. Finally, by improving the loss function of pix2pix model and adding the penalty term, not only the training can be stabilized, but also the ideal color image can be obtained. To reflect image color rendering quality of different models more objectively, PSNR and SSIM indexes are adopted to evaluate the rendered images. The experimental results of the proposed method show that the robust image rendered by this method has better visual performance and reduces the influence of light and noise on the image to a certain extent.
Citation: Hong-an Li, Min Zhang, Zhenhua Yu, Zhanli Li, Na Li. An improved pix2pix model based on Gabor filter for robust color image rendering[J]. Mathematical Biosciences and Engineering, 2022, 19(1): 86-101. doi: 10.3934/mbe.2022004
In recent years, with the development of deep learning, image color rendering method has become a research hotspot once again. To overcome the detail problems of color overstepping and boundary blurring in the robust image color rendering method, as well as the problems of unstable training based on generative adversarial networks, we propose an color rendering method using Gabor filter based improved pix2pix for robust image. Firstly, the multi-direction/multi-scale selection characteristic of Gabor filter is used to preprocess the image to be rendered, which can retain the detailed features of the image while preprocessing to avoid the loss of features. Moreover, among the Gabor texture feature maps with 6 scales and 4 directions, the texture map with the scale of 7 and the direction of 0° has the comparable rendering performance. Finally, by improving the loss function of pix2pix model and adding the penalty term, not only the training can be stabilized, but also the ideal color image can be obtained. To reflect image color rendering quality of different models more objectively, PSNR and SSIM indexes are adopted to evaluate the rendered images. The experimental results of the proposed method show that the robust image rendered by this method has better visual performance and reduces the influence of light and noise on the image to a certain extent.

| [1] |
M. Wang, G. W. Yang, S. M. Hu, S. T. Yau, A. Shamir, Write-a-video: Computational video montage from themed text, ACM Trans. Graphics, 38 (2019), 1–13. doi: 10.1145/3355089.3356520. doi: 10.1145/3355089.3356520

|
| [2] | R. Yi, Y. J. Liu, Y. K. Lai, P. L. Rosin, Apdrawinggan: Generating artistic portrait drawings from face photos with hierarchical gans, in 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), (2019), 10743–10752. |
| [3] | T. Yuan, Y. Wang, K. Xu, R. R. Martin, S. M. Hu, Two-layer qr codes, IEEE Trans. Image Process., 28 (2019), 4413–4428. doi: 10.1109/TIP.2019.2908490. |
| [4] | H. Li, Q. Zheng, J. Zhang, Z. Du, Z. Li, B. Kang, Pix2pix-based grayscale image coloring method, J. Comput. Aided Comput. Graphics, 33 (2021), 929–938. |
| [5] |
H. Li, M. Zhang, K. Yu, X. Qi, J. Tong, A displacement estimated method for real time tissue ultrasound elastography, Mobile Netw. Appl., 26 (2021), 1–10. doi: 10.1007/s11036-021-01735-3. doi: 10.1007/s11036-021-01735-3
|
| [6] |
T. Welsh, M. Ashikhmin, K. Mueller, Transferring color to greyscale images, ACM Trans. Graph., 21 (2002), 277–280. doi: 10.1145/566570.566576. doi: 10.1145/566570.566576
|
| [7] | Y. Jing, Z. J. Chen, Analysis and research of globally matching color transfer algorithms in different color spaces, Comput. Eng. Appl., (2007), 45–54. |
| [8] | S. F. Yin, C. L. Cao, H. Yang, Q. Tan, Q. He, Y. Ling, et al., Color contrast enhancent method to imprrove target detectability in night vision fusion, J. Infrared Milli. Waves, 28 (2009), 281–284. |
| [9] | M. W. Xu, Y. F. Li, N. Chen, S. Zhang, P. Xiong, Z. Tang, et al., Coloration of the low light level and infrared image using multi-scale fusion and nonlinear color transfer technique, Infrared Techn., 34 (2012), 722–728. |
| [10] | Z. P, M. G. Xue, C. C. Liu, Night vision image color fusion method using color transfer and contrast enhancement, J. Graphics, 35 (2014), 864–868. |
| [11] | R. Zhang, J. Zhu, P. Isola, X. Geng, A. S. Lin, T. Yu, et al., Real-time user-guided image colorization with learned deep priors, preprint, arXiv: 1705.02999. |
| [12] | Z. Cheng, Q. Yang, B. Sheng, Deep colorization, preprint, arXiv: 1605.00075. |
| [13] | K. Nazeri, E. Ng, M. Ebrahimi, Image colorization using generative adversarial networks, in International Conference on Articulated Motion and Deformable Objects, (2018), 85–94. doi: 10.1007/978-3-319-94544-69. |
| [14] |
H. Li, Q. Zheng, W. Yan, R. Tao, X. Qi, Z. Wen, Image super-resolution reconstruction for secure data transmission in internet of things environment, Math. Biosci. Eng., 18 (2021), 6652–6671. doi: 10.3934/mbe.2021330. doi: 10.3934/mbe.2021330
|
| [15] |
H. A. Li, Q. Zheng, X. Qi, W. Yan, Z. Wen, N. Li, et al., Neural network-based mapping mining of image style transfer in big data systems, Comput. Intell. Neurosci., 21 (2021), 1–11. doi: 10.1155/2021/8387382. doi: 10.1155/2021/8387382
|
| [16] |
C. Xiao, C. Han, Z. Zhang, J. Qin, T. Wong, G. Han, et al., Example-based colourization via dense encoding pyramids, Comput. Graph. Forum, 12 (2019), 20–33. doi: 10.1111/cgf.13659. doi: 10.1111/cgf.13659
|
| [17] |
S. S. Huang, H. Fu, S. M. Hu, Structure guided interior scene synthesis via graph matching, Graph. Models, 85 (2016), 46–55. doi: 10.1016/j.gmod.2016.03.004. doi: 10.1016/j.gmod.2016.03.004
|
| [18] |
Y. Liu, K. Xu, L. Yan, Adaptive brdf mriented multiple importance sampling of many lights, Comput. Graph. Forum, 38 (2019), 123–133. doi: 10.1111/cgf.13776. doi: 10.1111/cgf.13776
|
| [19] | S. S. Huang, H. Fu, L. Wei, S. M. Hu, Support substructures: Support-induced part-level structural representation, 22 (2015), 2024–36. doi: 10.1109/TVCG.2015.2473845. |
| [20] | G. Larsson, M. Maire, G. Shakhnarovich, Learning representations for automatic colorization, in European Conference on Computer Vision, Springer International Publishing, (2016), 577–593. doi: 10.1007/978-3-319-46493-035. |
| [21] |
I. H. Iizuka S, Simo-Serra E, Let there be color!: Joint end-to-end learning of global and local image priors for automatic image colorization with simultaneous classification, ACM Trans. Graph., 35 (2016), 577–593. doi: 10.1145/2897824.2925974. doi: 10.1145/2897824.2925974
|
| [22] |
R. Zhang, P. Isola, A. A. Efros, Colorful image colorization, Comput. Vision Pattern Recogn., 9907 (2016), 649–666. doi: 10.1007/978-3-319-46487-940. doi: 10.1007/978-3-319-46487-940
|
| [23] |
C. Li, J. Guo, C. Guo, Emerging from water: Underwater image color correction based on weakly supervised color transfer, IEEE Signal Proc. Lett., 25 (2018), 323–327. doi: 10.1109/LSP.2018.2792050. doi: 10.1109/LSP.2018.2792050
|
| [24] |
R. Zhou, C. Tan, P. Fan, Quantum multidimensional color image scaling using nearest-neighbor interpolation based on the extension of frqi, Mod. Phys. Lett. B, 31 (2017), 175–184. doi: 10.1142/s0217984917501846. doi: 10.1142/s0217984917501846
|
| [25] |
E. Reinhard, M. Adhikhmin, B. Gooch, P. Shirley, Color transfer between images, IEEE Comput. Graph. Appl., 21 (2001), 34–41. doi: 10.1109/38.946629. doi: 10.1109/38.946629
|
| [26] | P. Isola, J. Zhu, T. Zhou, A. A. Efro, Image-to-image translation with conditional adversarial networks, in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, (2016), 1125–1134. doi: arXiv-1611.07004. |
| [27] | L. Tao, Review on gabor expansion and transform, J. Anhui Univ., 41 (2017), 2–13. |
| [28] | R. Yi, Y. J. Liu, Y. K. Lai, P. L. Rosin, Unpaired portrait drawing generation via asymmetric cycle mapping, in 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), (2020), 8214–8222. doi: 10.1109/CVPR42600.2020.00824. |
| [29] |
Z. H. Wang, Z. Z. Wang, Robust cell segmentation based on gradient detection, Gabor filtering and morphological erosion, Biomed. Signal Proces. Control, 65 (2021), 1–13. doi: 10.1016/j.bspc.2020.102390. doi: 10.1016/j.bspc.2020.102390
|
| [30] | V. Kouni, H. Rauhut, Star DGT: a robust gabor transform for speech denoising, preprint, arXiv: 2104.14468. |
| [31] |
Y. Chen, L. Zhu, P. Ghamisi, X. Jia, G. Li, L. Tang, Hyperspectral Images Classification With Gabor Filtering and Convolutional Neural Network, IEEE Geosci. Remote Sens. Lett., 14 (2020), 2355–2359. doi: 10.1109/LGRS.2017.2764915. doi: 10.1109/LGRS.2017.2764915
|
| [32] | H. W. Sino, Indrabayu, I. S. Areni, Face recognition of low-resolution video using gabor filter and adaptive histogram equalization, in 2019 International Conference of Artificial Intelligence and Information Technology (ICAIIT), (2019), 417–421. doi: 10.1109/ICAIIT.2019.8834558. |
| [33] | X. Lin, X. Lin, X. Dai, Design of two-dimensional gabor filters and implementation of iris recognition system, Telev. technol., 35 (2011), 109–112. |
| [34] | I. J. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, et al., Generative adversarial networks, Adv. Neural Inform. Proc. Sys., 3 (2014), 2672–2680, . |
| [35] | X. Mao, Q. Li, H. Xie, R. Y. K. Lau, Z. Wang, S. P. Smolley, Least squares generative adversarial networks, in Proceedings of the IEEE International Conference on Computer Vision, (2016), 2813–2821. |
| [36] | I. Gulrajani, F. Ahmed, M. Arjovsky, V. Dumoulin, A. Courville, Improved training of wasserstein gans, preprint, arXiv: 1704.00028. |
| [37] | Z. Zhang, M. R. Sabuncu, Generalized cross entropy loss for training deep neural networks with noisy labels, in 32nd Conference on Neural Information Processing Systems (NeurIPS), (2018), 1–14. |
| [38] | M. Arjovsky, S. Chintala, L. Bottou, Wasserstein gan, preprint, arXiv: 1701.07875. |
| [39] |
F. Duan, S. Yin, P. Song, W. Zhang, H. Yokoi, Automatic welding defect detection of x-ray images by using cascade adaboost with penalty term, IEEE Access, 7 (2019), 125929–125938. doi: 10.1109/ACCESS.2019.2927258. doi: 10.1109/ACCESS.2019.2927258
|
| [40] | CycleGAN/datasets, Summer2winter, 2000. Available from: https://people.eecs.berkeley.edu/taesungpark/CycleGAN/datasets. |
| [41] | Z. Wang, A. C. Bovik, H. R. Sheikh, E. P. Simoncelli, Image quality assessment : From error visibility to structural similarity, IEEE Trans. Image Process., (2004), 600–612. doi: 10.1109/TIP.2003.819861. |
| [42] | A. Horé, D. Ziou, Image quality metrics: Psnr vs. ssim, in International Conference on Pattern Recognition, (2010), 2366–2369. doi: 10.1109/ICPR.2010.579. |








Figures(9) / Tables(10)

Hong-an Li, Min Zhang, Zhenhua Yu, Zhanli Li, Na Li. An improved pix2pix model based on Gabor filter for robust color image rendering[J]. Mathematical Biosciences and Engineering, 2022, 19(1): 86-101. doi: 10.3934/mbe.2022004







 DownLoad:
DownLoad: