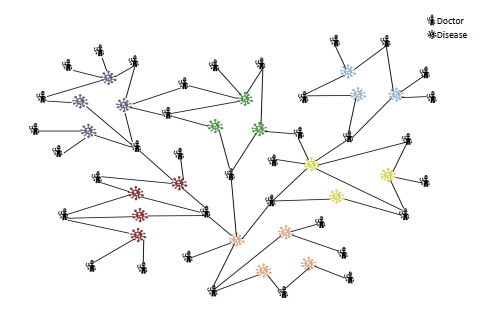
With the development of online medical service platform, patients can find more medical information resources and obtain better medical treatment. However, it is difficult for patients to discover the most suitable doctors from the complex information resources. Therefore, the analysis and mining of Electronic Health Record(EHR) is very important for patients' timely and accurate treatment. Discovering the most suitable doctor is actually predicting the exact performance of the doctor for a specific disease. We believe that "a curative/bad treatment is likely to be caused by a good/bad doctor, and a good/bad doctor has a higher/lower evaluation by the patient(s)". In this paper, we propose a novel approach named SeekDoc, which is to seek the most effective doctor for a specific disease. Specifically, we build a doctor-disease heterogeneous information network and collect patients reviews and rating records for doctors. Then, we embed the comprehensive comment data for doctors and the constructed heterogeneous information network. Next, we use the autoencoder mechanism to learn the embedded features, which is an effective learning algorithm for constructing the latent feature representation in an unsupervised manner. After this learning, the latent features are input into the extreme gradient boosting (XGBoost) algorithm to improve their detection capabilities. Finally, extensive experiments show that our method can effectively and efficiently predict the doctor's experience score for specific diseases and has good performance compared with other algorithms.
Citation: Lu Jiang, Shasha Xie, Yuqi Wang, Xin Xu, Xiaosa Zhao, Ye Zhang, Jianan Wang, Lihong Hu. SeekDoc: Seeking eligible doctors from electronic health record[J]. Mathematical Biosciences and Engineering, 2021, 18(5): 5347-5363. doi: 10.3934/mbe.2021271
With the development of online medical service platform, patients can find more medical information resources and obtain better medical treatment. However, it is difficult for patients to discover the most suitable doctors from the complex information resources. Therefore, the analysis and mining of Electronic Health Record(EHR) is very important for patients' timely and accurate treatment. Discovering the most suitable doctor is actually predicting the exact performance of the doctor for a specific disease. We believe that "a curative/bad treatment is likely to be caused by a good/bad doctor, and a good/bad doctor has a higher/lower evaluation by the patient(s)". In this paper, we propose a novel approach named SeekDoc, which is to seek the most effective doctor for a specific disease. Specifically, we build a doctor-disease heterogeneous information network and collect patients reviews and rating records for doctors. Then, we embed the comprehensive comment data for doctors and the constructed heterogeneous information network. Next, we use the autoencoder mechanism to learn the embedded features, which is an effective learning algorithm for constructing the latent feature representation in an unsupervised manner. After this learning, the latent features are input into the extreme gradient boosting (XGBoost) algorithm to improve their detection capabilities. Finally, extensive experiments show that our method can effectively and efficiently predict the doctor's experience score for specific diseases and has good performance compared with other algorithms.

| [1] |
M. E. J. Newman, The structure and function of complex networks, SIAM Rev., 45 (2003), 167–256. doi: 10.1137/S003614450342480

|
| [2] | L. Jiang, P. Wang, K. Cheng, K. Liu, M. Yin, B. Jin Y. Fu, et al., EduHawkes: A Neural Hawkes Process Approach for Online Study Behavior Modeling, Proceedings of the 2021 SIAM International Conference on Data Mining (SDM), 2021. |
| [3] | A. Hosseini, T. Chen, W. Wu, Y. Sun, M. Sarrafzadeh, Heteromed: Heterogeneous information network for medical diagnosis, Proceedings of the 27th ACM International Conference on Information and Knowledge Management, 2018. |
| [4] | X. Yu, X. Ren, Y. Sun, Q. Gu, B. Sturt, U. Khandelwal, et al., Personalized entity recommendation: A heterogeneous information network approach, Proceedings of the 7th ACM international conference on Web search and data mining, 2014. |
| [5] | M. Yousefi-Azar, V. Varadharajan, L. Hamey, U. Tupakula, Autoencoder-based feature learning for cyber security applications, 2017 International joint conference on neural networks (IJCNN), 2017. |
| [6] | Y. Lecun, Y. Bengio, G. Hinton, Deep learning, Nature, 521 (2015), 436. |
| [7] | T. Chen, C. Guestrin, Xgboost: A scalable tree boosting system, Proceedings of the 22nd acm sigkdd international conference on knowledge discovery and data mining, 2016. |
| [8] | T. Chen, T. He, M. Benesty, V. Khotilovich, Y. Tang, Xgboost: extreme gradient boosting, R Package Version, 1 (2015), 1–4. |
| [9] | Y. Goldberg, O. Levy, word2vec Explained: deriving Mikolov et al.'s negative-sampling word-embedding method, preprint, arXiv: 1402.3722. |
| [10] | A. Grover, J. Leskovec, node2vec: Scalable feature learning for networks, Proceedings of the 22nd ACM SIGKDD international conference on Knowledge discovery and data mining, 2016. |
| [11] | V. Nair, G. E. Hinton, Rectified linear units improve restricted boltzmann machines, Proceedings of the 27th international conference on machine learning (ICML-10), 2010. |
| [12] | Y. Li, Z. Zhang, Z. Teng, X. Liu, Predamyl-mlp: Prediction of amyloid proteins using multilayer perceptron, Comput. Math. Methods Med., 2020 (2020). |
| [13] |
I. Mihaylov, M. Nisheva, D. Vassilev, Application of machine learning models for survival prognosis in breast cancer studies, Information, 10 (2019), 93. doi: 10.3390/info10030093
|
| [14] |
M. L. Gadebe, Smartphone nave bayes human activity recognition using personalized datasets, J. Adv. Comput. Intell. Intell. Inf., 24 (2020), 685–702. doi: 10.20965/jaciii.2020.p0685
|
| [15] | J. T. Chien, Nonnegative matrix factorization, Source Sep. Mach. Learn., 2019 (2019), 161–229. |
| [16] | X. Xu, Y. Fu, H. Xiong, B. Jin, X. Li, S. Hu, et al., Dr. right!: Embedding-based adaptively-weighted mixture multi-classification model for finding right doctors with healthcare experience data, 2018 IEEE International Conference on Data Mining (ICDM), 2018. |
| [17] | M. Tokic, G. Palm, Value-difference based exploration: adaptive control between epsilon-greedy and softmax, in Annual Conference on Artificial Intelligence, Springer, 2011. |
| [18] | E. Choi, M. T. Bahadori, L. Song, W. F. Stewart, J. Sun, Gram: graph-based attention model for healthcare representation learning, Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, 2017. |
| [19] | E. Choi, M. T. Bahadori, E. Searles, C. Coffey, J. Sun, Multi-layer representation learning for medical concepts, Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, 2016. |
| [20] | A. Bagheri, T. K. J. Groenhof, W. B. Veldhuis, P. A. de Jong, F. W. Asselbergs, D. L. Oberski, Multimodal learning for cardiovascular risk prediction using EHR data, preprint, arXiv: 2008.11979. |
| [21] | H. Suresh, J. J. Gong, J. V. Guttag, Learning tasks for multitask learning: Heterogenous patient populations in the icu, Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, 2018. |
| [22] |
Y. Zhang, M. Chen, D. Huang, D. Wu, Y. Li, idoctor: Personalized and professionalized medical recommendations based on hybrid matrix factorization, Future Gene. Comput. Syst., 66 (2017), 30–35. doi: 10.1016/j.future.2015.12.001
|
| [23] | J. Ling, C. C. Yang, User recommendation in healthcare social media by assessing user similarity in heterogeneous network, Artif. Intell. Med., 81 (2017), S0933365717301185. |
| [24] |
C. Xu, J. Wang, L. Zhu, C. Zhang, K. Sharif, PPMR: A privacy-preserving online medical service recommendation scheme in ehealthcare system, IEEE Int. Things J., 6 (2019), 5665–5673. doi: 10.1109/JIOT.2019.2904728
|
| [25] | Y. Yan, G. Yu, X. Yan, Online doctor recommendation with convolutional neural network and sparse inputs, Comput. Intell. Neurosci., 2020 (2020). |
| [26] |
B. Jin, C. Che, Z. Liu, S. Zhang, X. Yin, X. P. Wei, Predicting the risk of heart failure with ehr sequential data modeling, IEEE Access, 6 (2018), 9256–9261. doi: 10.1109/ACCESS.2017.2789324
|
| [27] | L. Chen, X. Li, J. Han, Medrank: discovering influential medical treatments from literature by information network analysis, Proceedings of the Twenty-Fourth Australasian Database Conference, 2013. |
| [28] | R. M. A. Mateo, B. D. Gerardo, J. Lee, Healthcare expert system based on the group cooperation model, The 2007 International Conference on Intelligent Pervasive Computing (IPC 2007), 2007. |
| [29] | J. Zhang, C. Xia, C. Zhang, L. Cui, Y. Fu, S. Y. Philip, Bl-mne: emerging heterogeneous social network embedding through broad learning with aligned autoencoder, 2017 IEEE International Conference on Data Mining (ICDM), 2017. |
| [30] | Y. Bengio, P. Lamblin, D. Popovici, H. Larochelle, U. Montreal, Greedy layer-wise training of deep networks, Adv. Neural Inf. Proc. Syst., 19 (2007), 153–160. |
| [31] | I. Goodfellow, H. Lee, Q. V. Le, A. Saxe, A. Y. Ng, Measuring invariances in deep networks, in Adv. Neural Inf. Proc. Syst., 22 (2009), 646–654. |
| [32] |
D. Xiong, J. Zeng, H. Gong, A deep learning framework for improving long-range residue-residue contact prediction using a hierarchical strategy, Bioinformatics, 33 (2017), 2675–2683. doi: 10.1093/bioinformatics/btx296
|
| [33] | M. Gumus, M. S. Kiran, Crude oil price forecasting using xgboost, 2017 International Conference on Computer Science and Engineering (UBMK), 2017. |






Figures(7) / Tables(2)

Lu Jiang, Shasha Xie, Yuqi Wang, Xin Xu, Xiaosa Zhao, Ye Zhang, Jianan Wang, Lihong Hu. SeekDoc: Seeking eligible doctors from electronic health record[J]. Mathematical Biosciences and Engineering, 2021, 18(5): 5347-5363. doi: 10.3934/mbe.2021271







 DownLoad:
DownLoad: