Citation: Xin Liu, Yingyuan Xiao, Xu Jiao, Wenguang Zheng, Zihao Ling. A novel Kalman Filter based shilling attack detection algorithm[J]. Mathematical Biosciences and Engineering, 2020, 17(2): 1558-1577. doi: 10.3934/mbe.2020081

| [1] | P. A. Chirita, W. Nejdl and C. Zamfir, Preventing shilling attacks in online recommender systems, 2005 ACM International Workshop on Web Information and Data Management (WIDM), 2005. Available from: https://dlnext.acm.org/doi/abs/10.1145/1147376.1147387. |
| [2] | R. Burke, B. Mobasher, C. Williams and R. Bhaumik, Classification features for attack detection in collaborative recommender systems, 2006 ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD), 2006. Available from: https://dlnext.acm.org/doi/proceedings/10.1145/1150402. |
| [3] | C. A. Williams, B. Mobasher and R. Burke, Defending recommender systems: detection of profile injection attacks, SOCA, 1 (2007), 157-170. |
| [4] | B. Mehta, Unsupervised shilling detection for collaborative filtering, 2007 National Conference on Artificial Intelligence, 2007. Available from: https://www.aaai.org/Library/AAAI/2007/aaai07-222.php. |
| [5] | F. Peng, X. Zeng, H. Deng and L. Liu, Unsupervised detection of shilling attack for recommender system based on feature subset, Comput. Eng., 40 (2014), 109-114. |
| [6] | Z. Zhang and S. R. Kulkarni, Graph-based detection of shilling attacks in recommender systems, 2013 IEEE International Workshop on Machine Learning for Signal Processing (MLSP), 2013. Available from: https://ieeexplore.ieee.org/xpl/conhome/6648476/proceeding. |
| [7] | Z. Wu, J. Cao, B. Mao and Y. Wang, Semi-SAD: Applying semi-supervised learning to shilling attack detection, 2011 ACM Conference on Recommender Systems (RecSys), 2011. Available from: https://dlnext.acm.org/doi/proceedings/10.1145/2043932. |
| [8] | C. Lv and W. Wang, Semi-supervised shilling attacks detection method based on SVM-KNN, Comput. Eng. Appl., 49 (2013), 7-10. |
| [9] | M. Gao, Q. Yuan, B. Ling and Q. Xiong, Detection of abnormal item based on time intervals for recommender systems, Sci. World J., 2014 (2014), 1-8. |
| [10] | Z. Yang and Z. Cai, Detecting abnormal profiles in collaborative filtering recommender systems, J. Intell. Inf. Syst., 48 (2017), 499-518. |
| [11] | W. Bhebe and O. P. Kogeda, Shilling attack detection in collaborative recommender systems using a meta learning strategy, 2015 International Conference on Emerging Trends in Networks and Computer Communications (ETNCC), 2015. Available from: https://ieeexplore.ieee.org/xpl/conhome/7164876/proceeding. |
| [12] | W. Zhou, J. Wen, Q. Xiong, M. Gao and J. Zeng, SVM-TIA a shilling attack detection method based on SVM and target item analysis in recommender systems, Neurocomputing, 210 (2016), 197-205. |
| [13] | M. O'Mahony, N. Hurley, N. Kushmerick and G. Silvestre, Collaborative recommendation: A robustness analysis, ACM Trans. Internet. Technol., 4 (2004), 344-377. |
| [14] | B. Mobasher, R. Burke, R. Bhaumik and C. Williams, Toward trustworthy recommender systems: An analysis of attack models and algorithm robustness, ACM Trans. Internet. Technol., 7 (2007), 23-60. |
| [15] | R. T. Sikora and K. Chauhan, Estimating sequential bias in online reviews: A Kalman Filtering approach, Knowledge-Based Syst., 27(2012), 314-321. |
| [16] | K. Inuzuka, T. Hayashi and T. Takagi, Recommendation system based on prediction of user preference changes, 2016 IEEE/WIC/ACM International Conference on Web Intelligence (WI), 2016. Available from: https://ieeexplore.ieee.org/xpl/conhome/7814734/proceeding. |
| [17] | C. Williams and B. Mobasher, Profile injection attack detection for securing collaborative recommender systems, DePaul Univ. CTI Technol. Repo., 2006 (2006), 1-47. |
| [18] | K. Fang and J. Wang, Shilling attacks detection algorithm based on nonnegative matrix factorization, Comput. Eng. Appl., 53 (2017), 150-154. |
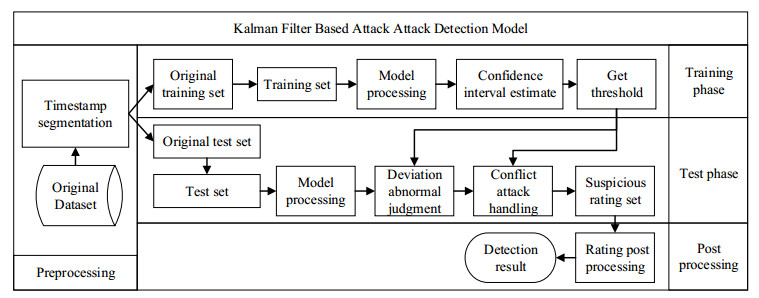
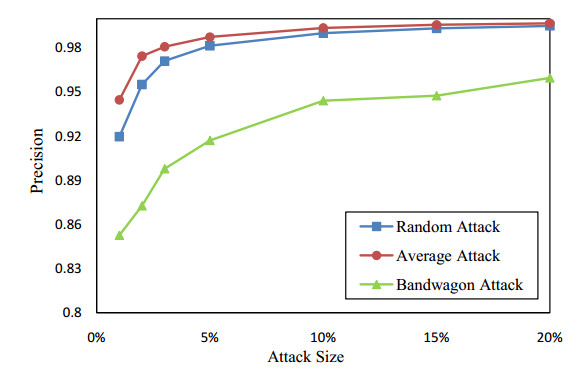
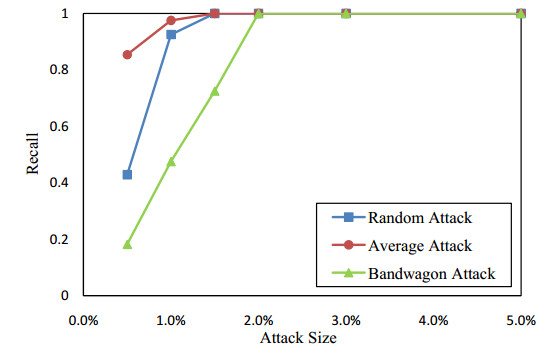
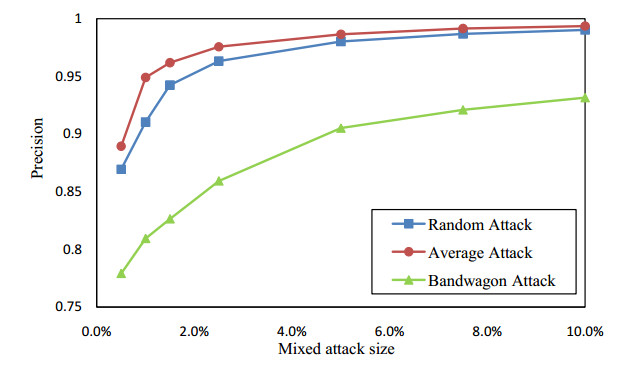
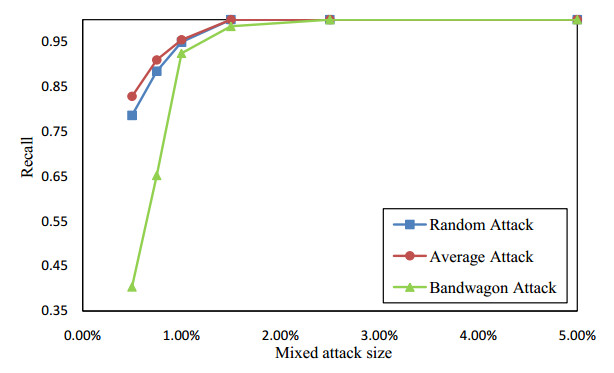
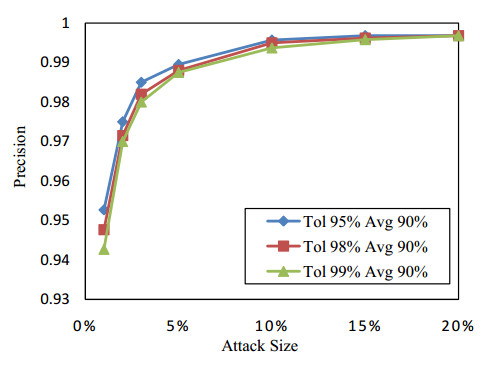
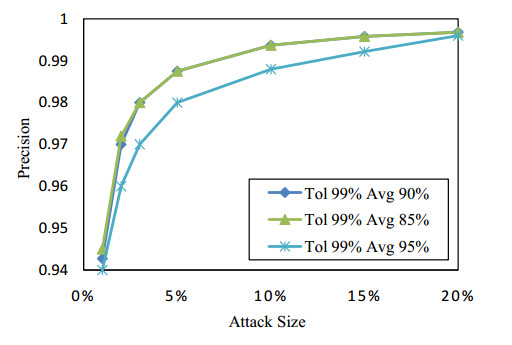
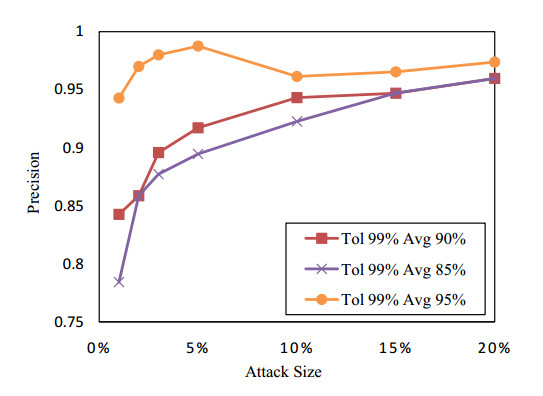
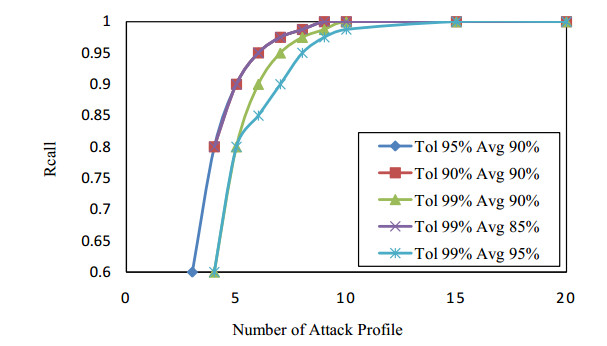
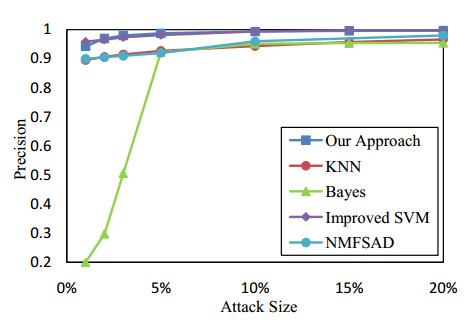
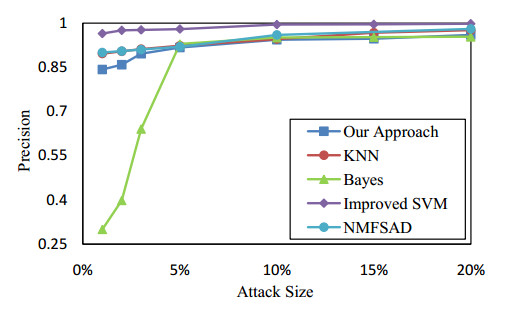
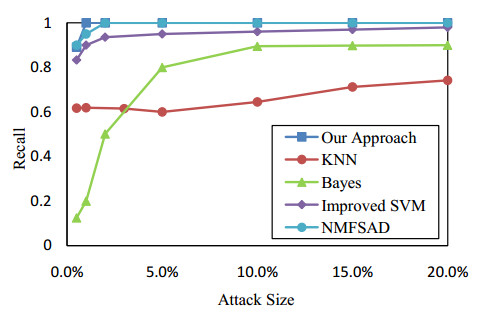
Figures(13) / Tables(2)

Xin Liu, Yingyuan Xiao, Xu Jiao, Wenguang Zheng, Zihao Ling. A novel Kalman Filter based shilling attack detection algorithm[J]. Mathematical Biosciences and Engineering, 2020, 17(2): 1558-1577. doi: 10.3934/mbe.2020081







 DownLoad:
DownLoad: