Citation: Xinglong Yin, Lei Liu, Huaxiao Liu, Qi Wu. Heterogeneous cross-project defect prediction with multiple source projects based on transfer learning[J]. Mathematical Biosciences and Engineering, 2020, 17(2): 1020-1040. doi: 10.3934/mbe.2020054

| [1] | J. Nam, S. J. Pan and S. Kim, Transfer defect learning, 2013 35th International Conference on Software Engineering (ICSE), 2013, 382-391. Available from: https://ieeexplore_ieee.xilesou.top/abstract/document/6606584. |
| [2] | X. Y. Jing, S. Ying, Z. W. Zhang, et al., Dictionary learning based software defect prediction, Proceedings of the 36th International Conference on Software Engineering, ACM, 2014, 414-423. Available from: https://dl_acm.xilesou.top/citation.cfm?id=2568320. |
| [3] | Z. Mahmood, D. Bowes, P. C. R. Lane, et al., What is the Impact of Imbalance on Software Defect Prediction Performance?, Proceedings of the 11th International Conference on Predictive Models and Data Analytics in Software Engineering, ACM, 2015. Available from: https://dl_acm.xilesou.top/citation.cfm?id=2810150. |
| [4] | C. Tantithamthavorn, Towards a better understanding of the impact of experimental components on defect prediction modeling, 2016 IEEE/ACM 38th International Conference on Software Engineering Companion (ICSE-C), 2016, 867-870. Available from: https://ieeexplore_ieee.xilesou.top/abstract/document/7883423. |
| [5] | B. Turhan, T. Menzies, A. B. Bener, et al., On the relative value of cross-company and within-company data for defect prediction, Empirical Software Eng., 14 (2009), 540-578. |
| [6] | Y. Ma, G. Luo, X. Zeng, et al., Transfer learning for cross-company software defect prediction, Inf. Software Technol., 54 (2012), 248-256. |
| [7] | G. Canfora, A. De Lucia, M. Di Penta, et al., Multi-objective cross-project defect prediction, 2013 IEEE Sixth International Conference on Software Testing, Verification and Validation, 2013, 252-261. Available from: https://ieeexplore_ieee.xilesou.top/abstract/document/6569737. |
| [8] | F. Peters, T. Menzies and A. Marcus, Better cross company defect prediction, Proceedings of the 10th Working Conference on Mining Software Repositories, 2013, 409-418. Available from: https://dl_acm.xilesou.top/citation.cfm?id=2487161. |
| [9] | L. Chen, B. Fang, Z. Shang, et al., Negative samples reduction in cross-company software defects prediction, Inf. Software Technol., 62 (2015), 67-77. |
| [10] | J. Nam and S. Kim, Heterogeneous defect prediction, Proceedings of the 2015 10th joint meeting on foundations of software engineering, ACM, 2015, 508-519. Available from: https://dl_acm.xilesou.top/citation.cfm?id=2786814. |
| [11] | X. Jing, F. Wu, X. Dong, et al., Heterogeneous cross-company defect prediction by unified metric representation and CCA-based transfer learning, Proceedings of the 2015 10th Joint Meeting on Foundations of Software Engineering, ACM, 2015, 496-507. Available from: https://dl_acm.xilesou.top/citation.cfm?id=2786813. |
| [12] | M. H. Halstead, Elements of Software Science, Elsevier Science, New York, 1977. |
| [13] | T. J. McCabe, A complexity measure, IEEE Trans. Software Eng., 4 (1976), 308-320. |
| [14] | S. R. Chidamber and C. F. Kemerer, A metrics suite for object oriented design, IEEE Trans. Software Eng., 20 (1994), 476-493. |
| [15] | T. L. Graves, A. F. Karr, J. S. Marron, et al., Predicting fault incidence using software change history, IEEE Trans. Software Eng., 26 (2000), 653-661. |
| [16] | K. O. Elish and M. O. Elish, Predicting defect-prone software modules using support vector machines, J. Syst. Software, 81 (2008), 649-660. |
| [17] | A. S. Andreou and E. Papatheocharous, Software cost estimation using fuzzy decision trees, 2008 23rd IEEE/ACM International Conference on Automated Software Engineering, 2008, 371-374. Available from: https://ieeexplore_ieee.xilesou.top/abstract/document/4639344. |
| [18] | N. Bettenburg, M. Nagappan and A. E. Hassan, Think locally, act globally: Improving defect and effort prediction models, 2012 9th IEEE Working Conference on Mining Software Repositories (MSR), 2012, 60-69. Available from: https://ieeexplore_ieee.xilesou.top/abstract/document/6224300. |
| [19] | S. J. Pan and Q. Yang, A Survey on Transfer Learning, IEEE Trans. Knowl. Data Eng., 22 (2010), 1345-1359. |
| [20] | H. F. Chang and A. Mockus, Constructing universal version history, Proceedings of the 2006 international workshop on Mining software repositories, 2006, 76-79. Available from: https://dl_acm.xilesou.top/citation.cfm?id=1138002. |
| [21] | T. Menzies, B. Caglayan, E. Kocaguneli, et al., The promise repository of empirical software engineering data, 2012 (2012). |
| [22] | M. Shepperd, Q. Song, Z. Sun, et al., Data quality: Some comments on the NASA software defect datasets, IEEE Trans. Software Eng., 39 (2013), 1208-1215. |
| [23] | M. D'Ambros, M. Lanza, R. Robbes, An extensive comparison of bug prediction approaches, 2010 7th IEEE Working Conference on Mining Software Repositories (MSR 2010), 2010, 31-41. Available from: https://ieeexplore_ieee.xilesou.top/abstract/document/5463279. |
| [24] | R. Wu, H. Zhang, S. Kim, et al., Relink: Recovering links between bugs and changes, Proceedings of the 19th ACM SIGSOFT symposium and the 13th European conference on Foundations of software engineering, ACM, 2011, 15-25. Available from: https://dl_acm.xilesou.top/citation.cfm?id=2025120. |
| [25] | S. Zhong, T. M. Khoshgoftaar and N. Seliya, Unsupervised Learning for Expert-Based Software Quality Estimation, HASE, 2004, 149-155. Available from: http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.89.1471&rep=rep1&type=pdf. |
| [26] | P. S. Bishnu and V. Bhattacherjee, Software fault prediction using quad tree-based k-means clustering algorithm, IEEE Trans. Knowl. Data Eng., 24 (2012), 1146-1150. |
| [27] | G. Abaei, Z. Rezaei and A. Selamat, Fault prediction by utilizing self-organizing Map and Threshold, 2013 IEEE International Conference on Control System, Computing and Engineering, 2013, 465-470. Available from: https://ieeexplore_ieee.xilesou.top/abstract/document/6720010. |
| [28] | J. Nam and S. Kim, CLAMI: Defect Prediction on Unlabeled Datasets (T), 2015 30th IEEE/ACM International Conference on Automated Software Engineering (ASE), 2015, 452-463. Available from: https://ieeexplore_ieee.xilesou.top/abstract/document/7372033. |
| [29] | F. Zhang, Q. Zheng, Y. Zou, et al., Cross-project defect prediction using a connectivity-based unsupervised classifier, Proceedings of the 38th International Conference on Software Engineering, ACM, 2016, 309-320. |
| [30] | J. Han, J. Pei and M. Kamber, Data Mining: Concepts and Techniques, Elsevier, 2012. |
| [31] | A. B. A. Graf and S. Borer, Normalization in support vector machines, Joint Pattern Recognition Symposium, Springer, Berlin, Heidelberg, 2001, 277-282. |
| [32] | M. Harel and S. Mannor, Learning from multiple outlooks, arXiv preprint arXiv1005.0027, 2010. |
| [33] | L. Yang, L. P. Jing, J. Yu, et al., Heterogeneous transductive transfer learning algorithm, J. Software, 26 (2015), 2762-2780 (in Chinese). |
| [34] | J. C. Gower and G. B. Dijksterhuis, Procrustes problems, Oxford University Press on Demand, 2004. |
| [35] | F. Wilcoxon, Individual comparisons by ranking methods, Breakthroughs in Statistics, Springer Series in Statistics (Perspectives in Statistics), Springer, New York, 1992, 196-202. |
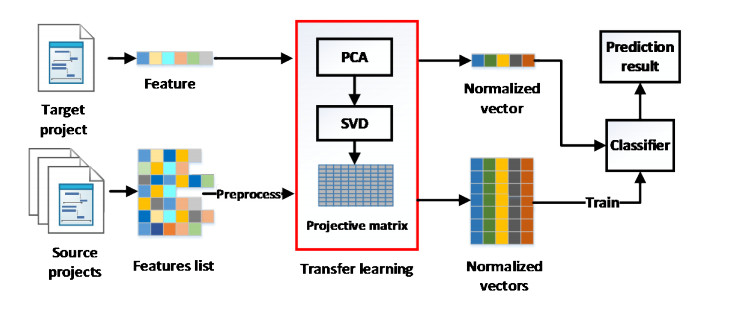
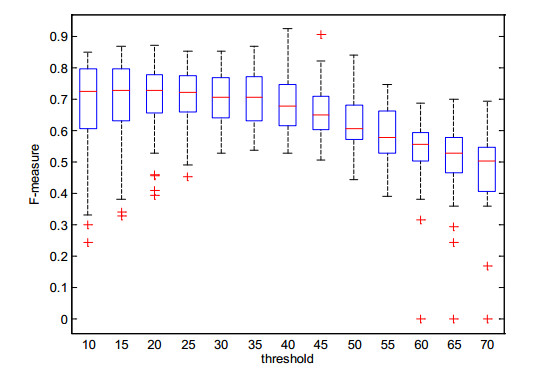
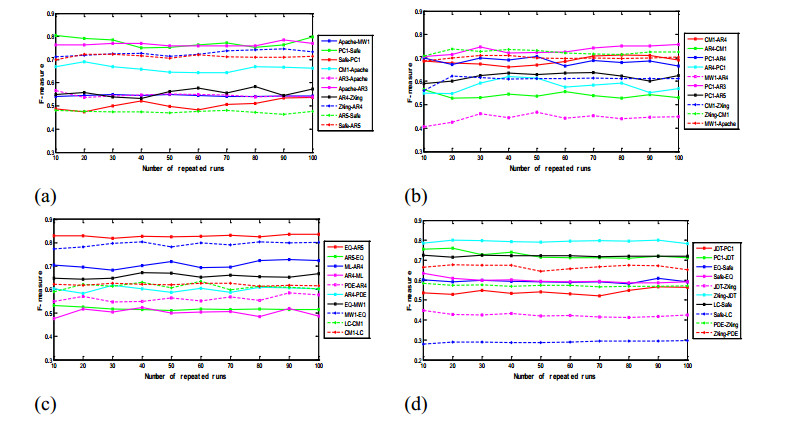
Figures(3) / Tables(10)

Xinglong Yin, Lei Liu, Huaxiao Liu, Qi Wu. Heterogeneous cross-project defect prediction with multiple source projects based on transfer learning[J]. Mathematical Biosciences and Engineering, 2020, 17(2): 1020-1040. doi: 10.3934/mbe.2020054







 DownLoad:
DownLoad: