Citation: Haibo Li, Juncheng Tong. A novel clustering algorithm for time-series data based on precise correlation coefficient matching in the IoT[J]. Mathematical Biosciences and Engineering, 2019, 16(6): 6654-6671. doi: 10.3934/mbe.2019331

| [1] | M. Weiser, R. Gold and J. S. Brown, The origins of ubiquitous computing research at PARC in the late 1980s, IBM Syst. J., 38 (1999), 693–696. |
| [2] | V. A. Memos, K. E. Psannis, Y. Ishibashi, et al., An efficient algorithm for media-based surveillance system (EAMSuS) in IoT smart city framework, Future Gener. Comp. Syst., 83 (2018), 619–628. |
| [3] | S. Tang, D. R. Shelden, C. M. Eastman, et al., A review of building information modeling (BIM) and the internet of things (IoT) devices integration: Present status and future trends, Automat. Const., 101 (2019), 127–139. |
| [4] | T. Baker, A. Taleb-Bendiab, M. Randles, et al., Understanding elasticity of cloud services compositions, In 2012 IEEE Fifth International Conference on Utility and Cloud Computing, Chicago(USA), IEEE, (2012), 231–232. |
| [5] | A. Jula, E. Sundararajan and Z. Othman, Cloud computing service composition: A systematic literature review, Expert Syst. Appl., 41 (2014), 3809–3824. |
| [6] | Q. Wu, G. Ding, Y. Xu, et al., Cognitive internet of things: a new paradigm beyond connection, IEEE Int. Things J., 1 (2014), 129–143. |
| [7] | C. Gomez, S. Chessa, A. Fleury, et al., Internet of Things for enabling smart environments: A technology-centric perspective, J. Ambient Int. Smart Environ., 11 (2019), 23–43. |
| [8] | L. Atzori, A. Iera and G. Morabito, The internet of things: A survey, Comput. Netw., 54 (2010), 2787–2805. |
| [9] | F. Chen, P. Deng, J. F. Wan, et al., Data Mining for the Internet of Things. Literature Review and Challenges, Int. J. Distrib. Sensor Netw., 11 (2015), P431047. |
| [10] | H. Li, Z. Zhang, X. Wang, et al., Electricity consumption behaviour analysis based on time sequence clustering, In 2018 International Conference on Computer Information Engineering and Bioinformatics, Guangzhou(China), IOP Publishing, (2018), 032011. |
| [11] | S. Pravilovic, M. Bilancia, A. Appice, et al., Using multiple time series analysis for geosensor data forecasting, Inf. Sci., 380 (2017), 31–52. |
| [12] | J. Liu, W. Li, J. Wu, et al., Visualizing the intercity correlation of PM2. 5 time series in the Beijing-Tianjin-Hebei region using ground-based air quality monitoring data, PloS One, 13 (2018), e0192614. |
| [13] | J. Soares, P. A. Makar, Y. Aklilu, et al., The use of hierarchical clustering for the design of optimized monitoring networks, Atmos. Chem. Phys., 18 (2018), 6543–6566. |
| [14] | A. Zaslavsky, C. Perera and D. Georgakopoulos, Sensing as a service and big data, In International Conference on Advances in Cloud Computing (ACC-2012), Bangalore(India), Eprint Arxiv, (2012), 21–29. |
| [15] | C. Chang and C. Li, Algebraic secret sharing using privacy homomorphisms for IoT-based healthcare systems, Math. Biosci. Eng., 16 (2019), 3367–3381. |
| [16] | Y. Ren, Y. Leng, Y Cheng, et al., Secure data storage based on blockchain and coding in edge computing, Math. Biosci. Eng., 16 (2019), 1874–1892. |
| [17] | C. Li and B. Palanisamy, Privacy in internet of things: From principles to technologies, IEEE Int. Things J., 6 (2019), 488–505. |
| [18] | A. P. Plageras, K. E. Psannis, C. Stergiou, et al., Efficient IoT-based sensor BIG Data collection–processing and analysis in smart buildings, Future Gener. Comp. Syst., 82 (2018), 349–357. |
| [19] | K. P. Kibiwott, Y. Zhao, J. Kogo, et al., Verifiable fully outsourced attribute-based signcryption system for IoT eHealth big data in cloud computing, Math. Biosci. Eng., 16 (2019), 3561–3594. |
| [20] | S. K. Jensen, T. B. Pedersen and C. Thomsen, Time series management systems: A survey, IEEE T. Knowledge Data Eng., 29 (2017), 2581–2600. |
| [21] | C. Stergiou, K. E. Psannis, A. P. Plageras, et al., Algorithms for efficient digital media transmission over IoT and cloud networking, J. Multimedia Inf. Syst., 5 (2018), 27–34. |
| [22] | K. E. Psannis, C. Stergiou and B. B. Gupta, Advanced media-based smart big data on intelligent cloud systems, IEEE T. Sustain. Comput., 4 (2018), 77–87. |
| [23] | W. Ejaz, M. Naeem, A. Shahid, et al., Efficient energy management for the internet of things in smart cities, IEEE Commun. Mag., 55 (2017), 84–91. |
| [24] | A. F. Mohammad and V. Korosh, Energy management-as-a-service over fog computing platform, IEEE Int. Things J., 3 (2015), 161–169. |
| [25] | F. Adenugba, S. Misra, R. Maskeliūnas, et al., Smart irrigation system for environmental sustainability in Africa: An Internet of Everything (IoE) approach, Math. Biosci. Eng., 16 (2019), 5490–5503. |
| [26] | M. Izal, D. Morató, E. Magaña, et al., Computation of traffic time series for large populations of IoT devices, Sensors, 19 (2019), 78. |
| [27] | Ş. Kolozali, D. Puschmann, M. Bermudez-Edo, et al., On the effect of adaptive and nonadaptive analysis of time-series sensory data, IEEE Int. Things J., 3 (2016), 1084–1098. |
| [28] | R. Salles, P. Mattos, A. M. D. Iorgulescu, et al., Evaluating temporal aggregation for predicting the sea surface temperature of the Atlantic Ocean. Ecol. Inform., 36 (2016), 94–105. |
| [29] | J. Roberts, M. Curran, S. Poynter, et al., Correlation confidence limits for unevenly sampled data, Comput. Geosci., 104 (2017), 120–124. |
| [30] | I. Ozken, D. Eroglu, S. F. Breitenbach, et al., Recurrence plot analysis of irregularly sampled data, Phys. Rev. E., 98 (2018), 052215. |
| [31] | H. Li, K. C. C. Chan, M. Liang, et al., Composition of resource-service chain for cloud manufacturing, IEEE T. Ind. Informat., 12 (2016), 211–219. |
| [32] | H. Li, M. Liang and T. Liang, Optimizing the composition of a resource service chain with inter-organizational collaboration, IEEE T. Ind. Informat., 13 (2017), 1152–1161. |
| [33] | H. Li and T. He, Selecting key feature sequence of resource services in industrial internet of things, IEEE Access, 6 (2018), 72152–72162. |
| [34] | L. Wen, L. Gao, Y. Dong, et al., A negative correlation ensemble transfer learning method for fault diagnosis based on convolutional neural network, Math. Biosci. Eng., 16 (2019), 3311–3330. |
| [35] | Z. Zhang, L. Liu, S. Zhang, et al., A service-based method for multiple sensor streams aggregation in fog computing, Wireless Commun. Mobile Comput., 1 (2018), 1–11. |
| [36] | M. Mehdizadeh, R. Ghazi and M. Ghayeni, Power system security assessment with high wind penetration using the farms models based on their correlation, IET Renew. Power Gener., 12 (2018), 893–900. |
| [37] | Z. Chen, Z. Xue, L. Zhang, et al., Analyzing the correlation and predictability of wind speed series based on mutual information, IEEE T. Electr. Electr. Eng., 13 (2018), 1829–1830. |
| [38] | J. Olauson and M. Bergkvist, Correlation between wind power generation in the European countries, Energy, 114 (2016), 663–670. |
| [39] | F. Wang, A novel coefficient for detecting and quantifying asymmetry of California electricity market based on asymmetric detrended cross-correlation analysis, Chaos Interdiscipl. J. Nonlinear Sci., 26 (2016), 063109. |
| [40] | T. Cui, F. Caravelli and C. Ududec, Correlations and clustering in wholesale electricity markets, Physica A., 492 (2018), 1507–1522. |
| [41] | R. Lin, B Wu and Y Su, An adaptive weighted pearson similarity measurement method for load curve clustering, Energies, 11 (2018), 1–17. |
| [42] | A. Mueen, H. Hamooni and T. Estrada, Time series join on subsequence correlation, In 2014 IEEE International Conference on Data Mining, Shenzhen(China), IEEE Computer Society Press, (2014), 450–459. |
| [43] | Z. Ye, S. Mistry, A. Bouguettaya, et al., Long-term QoS-aware cloud service composition using multivariate time series analysis, IEEE T. Services Comput., 9 (2014), 382–393. |
| [44] | M. Disegna, P. D'Urso and F. Durante, Copula-based fuzzy clustering of spatial time series, Spat. Stat., 21 (2017), 209–225. |
| [45] | J. C. Dunn, Well-separated clusters and optimal fuzzy partitions, J. Cybernetics, 4 (1974), 95–104. |
| [46] | M. Halkidi, Y. Batistakis and M Vazirgiannis, On clustering validation techniques, J. Intell. Inf. Syst., 17 (2001), 107–145. |
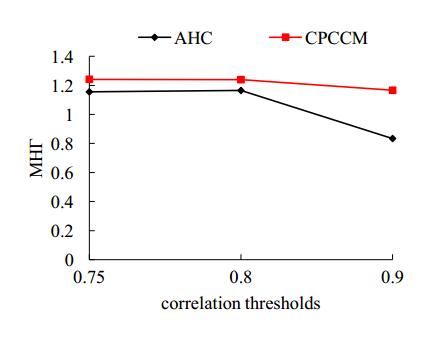
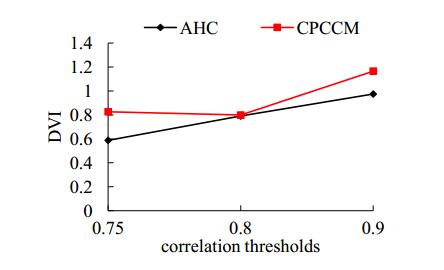
Figures(6) / Tables(4)

Haibo Li, Juncheng Tong. A novel clustering algorithm for time-series data based on precise correlation coefficient matching in the IoT[J]. Mathematical Biosciences and Engineering, 2019, 16(6): 6654-6671. doi: 10.3934/mbe.2019331







 DownLoad:
DownLoad: