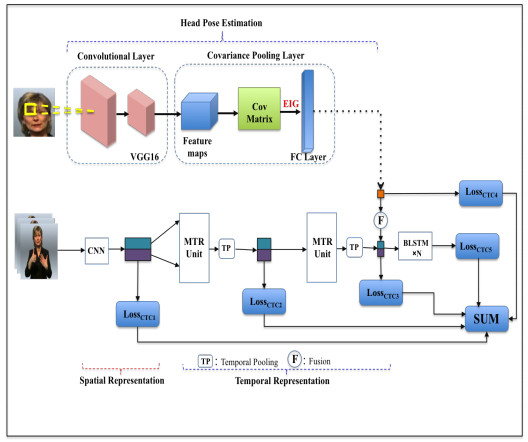
Sign language is regularly adopted by speech-impaired or deaf individuals to convey information; however, it necessitates substantial exertion to acquire either complete knowledge or skill. Sign language recognition (SLR) has the intention to close the gap between the users and the non-users of sign language by identifying signs from video speeches. This is a fundamental but arduous task as sign language is carried out with complex and often fast hand gestures and motions, facial expressions and impressionable body postures. Nevertheless, non-manual features are currently being examined since numerous signs have identical manual components but vary in non-manual components. To this end, we suggest a novel manual and non-manual SLR system (MNM-SLR) using a convolutional neural network (CNN) to get the benefits of multi-cue information towards a significant recognition rate. Specifically, we suggest a model for a deep convolutional, long short-term memory network that simultaneously exploits the non-manual features, which is summarized by utilizing the head pose, as well as a model of the embedded dynamics of manual features. Contrary to other frequent works that focused on depth cameras, multiple camera visuals and electrical gloves, we employed the use of RGB, which allows individuals to communicate with a deaf person through their personal devices. As a result, our framework achieves a high recognition rate with an accuracy of 90.12% on the SIGNUM dataset and 94.87% on RWTH-PHOENIX-Weather 2014 dataset.
Citation: Maher Jebali, Abdesselem Dakhli, Wided Bakari. Deep learning-based sign language recognition system using both manual and non-manual components fusion[J]. AIMS Mathematics, 2024, 9(1): 2105-2122. doi: 10.3934/math.2024105
Sign language is regularly adopted by speech-impaired or deaf individuals to convey information; however, it necessitates substantial exertion to acquire either complete knowledge or skill. Sign language recognition (SLR) has the intention to close the gap between the users and the non-users of sign language by identifying signs from video speeches. This is a fundamental but arduous task as sign language is carried out with complex and often fast hand gestures and motions, facial expressions and impressionable body postures. Nevertheless, non-manual features are currently being examined since numerous signs have identical manual components but vary in non-manual components. To this end, we suggest a novel manual and non-manual SLR system (MNM-SLR) using a convolutional neural network (CNN) to get the benefits of multi-cue information towards a significant recognition rate. Specifically, we suggest a model for a deep convolutional, long short-term memory network that simultaneously exploits the non-manual features, which is summarized by utilizing the head pose, as well as a model of the embedded dynamics of manual features. Contrary to other frequent works that focused on depth cameras, multiple camera visuals and electrical gloves, we employed the use of RGB, which allows individuals to communicate with a deaf person through their personal devices. As a result, our framework achieves a high recognition rate with an accuracy of 90.12% on the SIGNUM dataset and 94.87% on RWTH-PHOENIX-Weather 2014 dataset.

| [1] |
W. C. Stokoe, Sign language structure, Annu. Rev. Anthropol., 9 (1980), 365–390. http://dx.doi.org/10.1146/annurev.an.09.100180.002053 doi: 10.1146/annurev.an.09.100180.002053

|
| [2] | J. Napier, L. Leeson, Sign language in action, London: Palgrave Macmillan, 2016. http://dx.doi.org/10.1057/9781137309778 |
| [3] |
D. Lowe, Object recognition from local scale-invariant features, Proc. IEEE Int. Conf. Comput. Vision, 2 (1999), 1150–1157. http://dx.doi.org/10.1109/ICCV.1999.790410 doi: 10.1109/ICCV.1999.790410
|
| [4] |
Q. Zhu, M. C. Yeh, K. T. Cheng, S. Avidan, Fast human detection using a cascade of histograms of oriented gradients, Proc. IEEE Comput. Soc. Conf. Comput. Vision Pattern Recogn., 2006, 1491–1498. http://dx.doi.org/10.1109/CVPR.2006.119 doi: 10.1109/CVPR.2006.119
|
| [5] |
A. Memiş, S. Albayrak, A Kinect based sign language recognition system using spatio-temporal features, Proc. SPIE Int. Soc. Opt. Eng., 9067 (2013), 179–183. http://dx.doi.org/10.1117/12.2051018 doi: 10.1117/12.2051018
|
| [6] |
O. Sincan, H. Keles, Using motion history images with 3D convolutional networks in isolated sign language recognition, IEEE Access, 10 (2022), 18608–18618. http://dx.doi.org/10.1109/ACCESS.2022.3151362 doi: 10.1109/ACCESS.2022.3151362
|
| [7] |
G. Castro, R. R. Guerra, F. G. Guimarães, Automatic translation of sign language with multi-stream 3D CNN and generation of artificial depth maps, Expert Syst. Appl., 215 (2023), 119394. http://dx.doi.org/10.1016/j.eswa.2022.119394 doi: 10.1016/j.eswa.2022.119394
|
| [8] |
J. Huang, W. G. Zhou, H. G. Li, W. P. Li, Attention-based 3D-CNNs for large-vocabulary sign language recognition, IEEE T. Circ. Syst. Vid., 9 (2018), 2822–2832. http://dx.doi.org/10.1109/TCSVT.2018.2870740 doi: 10.1109/TCSVT.2018.2870740
|
| [9] |
K. Lim, A. Tan, C. P. Lee, S. Tan, Isolated sign language recognition using convolutional neural network hand modelling and hand energy image, Multimed. Tools Appl., 78 (2019), 19917–19944. http://dx.doi.org/10.1007/s11042-019-7263-7 doi: 10.1007/s11042-019-7263-7
|
| [10] |
M. Terreran, M. Lazzaretto, S. Ghidoni, Skeleton-based action and gesture recognition for human-robot collaboration, Intell. Auton. Syst., 577 (2022), 29–45. http://dx.doi.org/10.1007/978-3-031-22216-0_3 doi: 10.1007/978-3-031-22216-0_3
|
| [11] |
L. Roda-Sanchez, C. Garrido-Hidalgo, A. S. García, T. Olivares, A. Fernández-Caballero, Comparison of RGB-D and IMU-based gesture recognition for human-robot interaction in remanufacturing, Int. J. Adv. Manuf. Technol., 124 (2023), 3099–3111. http://dx.doi.org/10.1007/s00170-021-08125-9 doi: 10.1007/s00170-021-08125-9
|
| [12] |
W. Aditya, T. K. Shih, T. Thaipisutikul, A. S. Fitriajie, M. Gochoo, F. Utaminingrum, et al., Novel spatio-temporal continuous sign language recognition using an attentive multi-feature network, Sensors, 22 (2022), 6452. http://dx.doi.org/10.3390/s22176452 doi: 10.3390/s22176452
|
| [13] |
H. Liu, H. Nie, Z. Zhang, Y. F. Li, Anisotropic angle distribution learning for head pose estimation and attention understanding in human-computer interaction, Neurocomputing, 433 (2020), 310–322. http://dx.doi.org/10.1016/j.neucom.2020.09.068 doi: 10.1016/j.neucom.2020.09.068
|
| [14] |
S. Sharma, R. Gupta, A. Kumar, Continuous sign language recognition using isolated signs data and deep transfer learning, J. Amb. Intel. Hum. Comp., 2021, 1–12. http://dx.doi.org/10.1007/s12652-021-03418-z doi: 10.1007/s12652-021-03418-z
|
| [15] |
O. Koller, S. Zargaran, H. Ney, R. Bowden, Deep sign: Enabling robust statistical continuous sign language recognition via hybrid CNN-HMMs, Int. J. Comput. Vision, 126 (2018), 1311–1325. http://dx.doi.org/10.1007/s11263-018-1121-3 doi: 10.1007/s11263-018-1121-3
|
| [16] |
O. Koller, H. Ney, R. Bowden, Deep hand: How to train a CNN on 1 million hand images when your data is continuous and weakly labelled, IEEE Conf. Comput. Vision Pattern Recogn., 2016, 3793–3802. http://dx.doi.org/10.1109/CVPR.2016.412 doi: 10.1109/CVPR.2016.412
|
| [17] | O. Koller, S. Zargaran, H. Ney, R. Bowden, Deep sign: Hybrid CNN-HMM for continuous sign language recognition, Brit. Conf. Mach. Vision, 2016. |
| [18] |
O. Koller, H. Ney, R. Bowden, Re-sign: Re-aligned end-to-end sequence modelling with deep recurrent CNN-HMMs, IEEE Conf. Comput. Vision Pattern Recogn., 2017, 4297–4305. http://dx.doi.org/10.1109/CVPR.2017.364 doi: 10.1109/CVPR.2017.364
|
| [19] |
O. Özdemir, İ. Baytaş, L. Akarun, Multi-cue temporal modeling for skeleton-based sign language recognition, Front. Neurosci., 17 (2023), 1148191. http://dx.doi.org/10.3389/fnins.2023.1148191 doi: 10.3389/fnins.2023.1148191
|
| [20] |
H. Butt, M. R. Raza, M. R. Ramzan, M. J. Ali, M. Haris, Attention-based CNN-RNN Arabic text recognition from natural scene images, Forecasting, 3 (2021), 520–540. http://dx.doi.org/10.3390/forecast3030033 doi: 10.3390/forecast3030033
|
| [21] |
P. P. Roy, P. Kumar, B. G. Kim, An efficient sign language recognition (SLR) system using camshift tracker and hidden markov model (HMM), SN Comput. Sci., 2 (2021), 1–15. http://dx.doi.org/10.1007/s42979-021-00485-z doi: 10.1007/s42979-021-00485-z
|
| [22] |
L. Pigou, A. Oord, S. Dieleman, M. V. Herreweghe, J. Dambre, Beyond temporal pooling: Recurrence and temporal convolutions for gesture recognition in video, Int. J. Comput. Vision, 126 (2018), 430–439. http://dx.doi.org/10.1007/s11263-016-0957-7 doi: 10.1007/s11263-016-0957-7
|
| [23] |
J. Huang, W. G. Zhou, Q. L. Zhang, H. Q. Li, W. P. Li, Video-based sign language recognition without temporal segmentation, Proc. AAAI Conf. Artif. Intell., 32 (2018). http://dx.doi.org/10.1609/aaai.v32i1.11903 doi: 10.1609/aaai.v32i1.11903
|
| [24] |
K. Han, X. Y. Li, Research method of discontinuous-gait image recognition based on human skeleton keypoint extraction, Sensors, 23 (2023), 7274. http://dx.doi.org/10.3390/s23167274 doi: 10.3390/s23167274
|
| [25] |
D. Wategaonkar, R. Pawar, P. Jadhav, T. Patole, R. Jadhav, S. Gupta, Sign gesture interpreter for better communication between a normal and deaf person, J. Pharm. Negat. Result., 2022, 5990–6000. http://dx.doi.org/10.47750/pnr.2022.13.S07.731 doi: 10.47750/pnr.2022.13.S07.731
|
| [26] |
M. Jebali, A. Dakhli, M. Jemni, Vision-based continuous sign language recognition using multimodal sensor fusion, Evol. Syst., 12 (2021), 1031–1044. http://dx.doi.org/10.1007/s12530-020-09365-y doi: 10.1007/s12530-020-09365-y
|
| [27] |
M. Jebali, A. Dakhli, W. Bakari, Deep learning-based sign language recognition system for cognitive development, Cogn. Comput., 2023, 1–13. http://dx.doi.org/10.1007/s12559-023-10182-z doi: 10.1007/s12559-023-10182-z
|
| [28] |
V. Choutas, P. Weinzaepfel, J. Revaud, C. Schmid, PoTion: Pose motion representation for action recognition, Proc. IEEE Conf. Comput. Vision Pattern Recogn., 2018, 7024–7033. http://dx.doi.org/10.1109/CVPR.2018.00734 doi: 10.1109/CVPR.2018.00734
|
| [29] |
S. Yan, Y. Xiong, D. Lin, Spatial temporal graph convolutional networks for skeleton-based action recognition, Proc. AAAI Conf. Artif. Intell., 32 (2018). http://dx.doi.org/10.1609/aaai.v32i1.12328 doi: 10.1609/aaai.v32i1.12328
|
| [30] |
M. Bicego, M. Vázquez-Enríquez, J. L. Alba-Castro, Active class selection for dataset acquisition in sign language recognition, Image Anal. Proc., 2023,303–315. http://dx.doi.org/10.1007/978-3-031-43148-7_26 doi: 10.1007/978-3-031-43148-7_26
|
| [31] |
M. Li, S. Chen, X. Chen, Y. Zhang, Y. Wang, Q. Tian, Actional-structural graph convolutional networks for skeleton-based action recognition, IEEE Conf. Comput. Vision Pattern Recogn., 2019, 3590–3598. http://dx.doi.org/10.1109/CVPR.2019.00371 doi: 10.1109/CVPR.2019.00371
|
| [32] |
Y. F. Song, Z. Zhang, C. Shan, L. Wang, Constructing stronger and faster baselines for skeleton-based action recognition, IEEE T. Pattern Anal., 45 (2022), 1474–1488. http://dx.doi.org/10.1109/TPAMI.2022.3157033 doi: 10.1109/TPAMI.2022.3157033
|
| [33] |
Z. Wu, C. Shen, A. Hengel, Wider or deeper: Revisiting the ResNet model for visual recognition, Pattern Recogn., 90 (2019), 119–133. http://dx.doi.org/10.1016/j.patcog.2019.01.006 doi: 10.1016/j.patcog.2019.01.006
|
| [34] |
N. Takayama, G. Benitez-Garcia, H. Takahashi, Masked batch normalization to improve tracking-based sign language recognition using graph convolutional networks, IEEE Int. Conf. Autom. Face Gesture Recogn., 2021, 1–5. http://dx.doi.org/10.1109/FG52635.2021.9667007 doi: 10.1109/FG52635.2021.9667007
|
| [35] |
Ç. Gökçe, Ç. Özdemir, A. A. Kındıroğlu, L. Akarun, Score-level multi cue fusion for sign language recognition, Eur. Conf. Comput. Vision, 2020,294–309. http://dx.doi.org/10.48550/arXiv.2009.14139 doi: 10.48550/arXiv.2009.14139
|
| [36] |
L. Tarrés, G. I. Gállego, A. Duarte, J. Torres, X. Giró-i-Nieto, Sign language translation from instructional videos, IEEE Conf. Comput. Vision Pattern Recogn. Work., 2023, 5625–5635. http://dx.doi.org/10.1109/CVPRW59228.2023.00596 doi: 10.1109/CVPRW59228.2023.00596
|
| [37] |
O. Sincan, A. Tur, H. Keles, Isolated sign language recognition with multi-scale features using LSTM, Proc. Commun. Appl. Conf., 2019, 1–4. http://dx.doi.org/10.1109/SIU.2019.8806467 doi: 10.1109/SIU.2019.8806467
|
| [38] |
Q. Guo, S. J. Zhang, L. W. Tan, K. Fang, Y. H. Du, Interactive attention and improved GCN for continuous sign language recognition, Biomed. Signal Proces., 85 (2023), 104931. http://dx.doi.org/10.1016/j.bspc.2023.104931 doi: 10.1016/j.bspc.2023.104931
|
| [39] |
Z. Niu, B. Mak, Stochastic fine-grained labeling of multi-state sign glosses for continuous sign language recognition, Eur. Conf. Comput. Vision, 2020,172–186. http://dx.doi.org/10.1007/978-3-030-58517-4_11 doi: 10.1007/978-3-030-58517-4_11
|
| [40] |
A. Hao, Y. Min, X. Chen, Self-mutual distillation learning for continuous sign language recognition, Int. Conf. Comput. Vision, 2021, 11303–11312. http://dx.doi.org/10.1109/ICCV48922.2021.01111 doi: 10.1109/ICCV48922.2021.01111
|
| [41] |
D. Guo, S. Wang, Q. Tian, M. Wang, Dense temporal convolution network for sign language translation, Int. Joint Conf. Artif. Intell., 2019,744–750. http://dx.doi.org/10.24963/ijcai.2019/105 doi: 10.24963/ijcai.2019/105
|
| [42] |
D. Guo, S. G. Tang, M. Wang, Connectionist temporal modeling of video and language: A joint model for translation and sign labeling, Int. Joint Conf. Artif. Intell., 2019,751–757. http://dx.doi.org/10.24963/ijcai.2019/106 doi: 10.24963/ijcai.2019/106
|
| [43] |
I. Papastratis, K. Dimitropoulos, D. Konstantinidis, P. Daras, Continuous sign language recognition through cross-modal alignment of video and text embeddings in a joint-latent space, IEEE Access, 8 (2020), 91170–91180. http://dx.doi.org/10.1109/ACCESS.2020.2993650 doi: 10.1109/ACCESS.2020.2993650
|
| [44] |
M. Parelli, K. Papadimitriou, G. Potamianos, G. Pavlakos, P. Maragos, Spatio-temporal graph convolutional networks for continuous sign language recognition, IEEE Int. Conf. Acous. Speech Signal Proc., 2022, 8457–8461. http://dx.doi.org/10.1109/ICASSP43922.2022.9746971 doi: 10.1109/ICASSP43922.2022.9746971
|
| [45] |
R. Li, L. Meng, Multi-view spatial-temporal network for continuous sign language recognition, Comput. Vision Pattern Recogn, 2022. http://dx.doi.org/10.48550/arXiv.2204.08747 doi: 10.48550/arXiv.2204.08747
|
| [46] |
Z. C. Cui, W. B. Zhang, Z. X. Li, Z. Q. Wang, Spatial-temporal transformer for end-to-end sign language recognition, Complex Intell. Syst., 9 (2023), 4645–4656. http://dx.doi.org/10.1007/s40747-023-00977-w doi: 10.1007/s40747-023-00977-w
|






Figures(7) / Tables(6)

Maher Jebali, Abdesselem Dakhli, Wided Bakari. Deep learning-based sign language recognition system using both manual and non-manual components fusion[J]. AIMS Mathematics, 2024, 9(1): 2105-2122. doi: 10.3934/math.2024105







 DownLoad:
DownLoad: