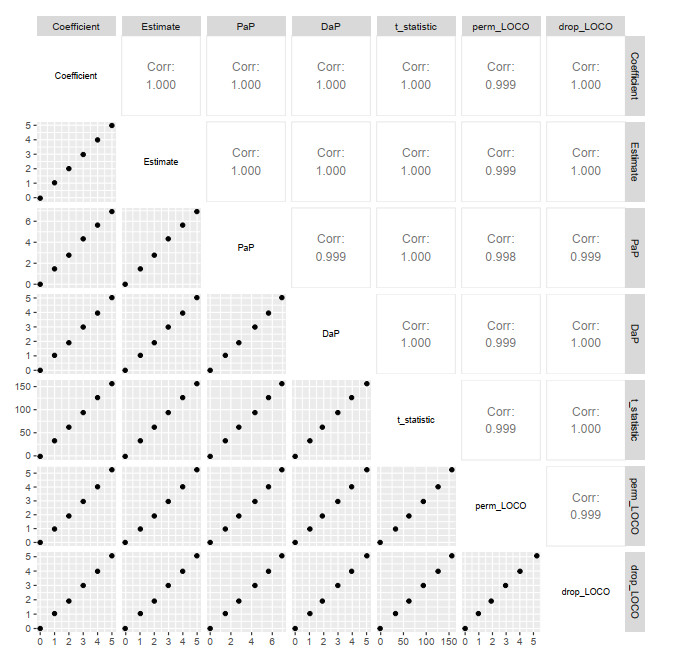
Permutation techniques have been used extensively in machine learning algorithms for evaluating variable importance. In ordinary regression, however, variables are often removed to gauge their importance. In this paper, we compared the results for permuting variables to removing variables in regression to assess relations between these two methods. We compared permute-and-predict (PaP) methods with leave-one-covariate-out (LOCO) techniques. We also compared these results with conventional metrics such as regression coefficient estimates, t-statistics, and random forest out-of-bag (OOB) PaP importance. Our results indicate that permutation importance metrics are practically equivalent to those obtained from removing variables in a regression setting. We demonstrate a strong association between the PaP metrics, true coefficients, and regression-estimated coefficients. We also show a strong relation between the LOCO metrics and the regression t-statistics. Finally, we illustrate that manual PaP methods are not equivalent to the OOB PaP technique and suggest prioritizing the use of manual PaP methods on validation data.
Citation: Kelvyn Bladen, D. Richard Cutler. Assessing agreement between permutation and dropout variable importance methods for regression and random forest models[J]. Electronic Research Archive, 2024, 32(7): 4495-4514. doi: 10.3934/era.2024203
Permutation techniques have been used extensively in machine learning algorithms for evaluating variable importance. In ordinary regression, however, variables are often removed to gauge their importance. In this paper, we compared the results for permuting variables to removing variables in regression to assess relations between these two methods. We compared permute-and-predict (PaP) methods with leave-one-covariate-out (LOCO) techniques. We also compared these results with conventional metrics such as regression coefficient estimates, t-statistics, and random forest out-of-bag (OOB) PaP importance. Our results indicate that permutation importance metrics are practically equivalent to those obtained from removing variables in a regression setting. We demonstrate a strong association between the PaP metrics, true coefficients, and regression-estimated coefficients. We also show a strong relation between the LOCO metrics and the regression t-statistics. Finally, we illustrate that manual PaP methods are not equivalent to the OOB PaP technique and suggest prioritizing the use of manual PaP methods on validation data.

| [1] | W. Kruskal, R. Majors, Concepts of relative importance in recent scientific literature, Am. Stat., 43 (1989), 2–6. |
| [2] | C. Achen, Interpreting and Using Regression, Sage, 29 (1982). |
| [3] |
R. Tibshirani, Regression shrinkage and selection via the lasso, J. R. Stat. Soc. B, 58 (1996), 267–288. https://doi.org/10.1111/j.2517-6161.1996.tb02080.x doi: 10.1111/j.2517-6161.1996.tb02080.x

|
| [4] |
H. Zou, T. Hastie, Regularization and variable selection via the elastic net, J. R. Stat. Soc. B, 67 (2005), 301–320. https://doi.org/10.1111/j.1467-9868.2005.00503.x doi: 10.1111/j.1467-9868.2005.00503.x
|
| [5] | J. Pratt, Dividing the indivisible: using simple symmetry to partition variance explained, in Proceedings of the Second International Tampere Conference in Statistics, (1987), 245–260. |
| [6] | L. Breiman, Random forests, Mach. Learn., 45 (2001), 5–32. https://doi.org/10.1023/A: 1010933404324 |
| [7] |
C. Strobl, A. Boulesteix, T. Kneib, T. Augustin, A. Zeileis, Conditional variable importance for random forests, BMC Bioinf., 9 (2008), 1–11. https://doi.org/10.1186/1471-2105-9-307 doi: 10.1186/1471-2105-9-307
|
| [8] | K. Bladen, Contributions to Random Forest Variable Importance with Applications in R, MS thesis, Utah State University, 2022. |
| [9] |
G. Hooker, L. Mentch, S. Zhou, Unrestricted permutation forces extrapolation: variable importance requires at least one more model, or there is no free variable importance, Stat. Comput., 31 (2021), 1–16. https://doi.org/10.1007/s11222-021-10057-z doi: 10.1007/s11222-021-10057-z
|
| [10] |
J. Lei, M. G'Sell, A. Rinaldo, R. Tibshirani, L. Wasserman, Distribution-free predictive inference for regression, J. Am. Stat. Assoc., 113 (2018), 1094–1111. https://doi.org/10.1080/01621459.2017.1307116 doi: 10.1080/01621459.2017.1307116
|
| [11] | R. Barber, E. Candès, Controlling the false discovery rate via knockoffs, Ann. Stat., 43 (2015), 2055–2085. |
| [12] |
E. Candès, Y. Fan, L. Janson, J. Lv, Panning for gold: 'model-X' knockoffs for high dimensional controlled variable selection, J. R. Stat. Soc. B, 80 (2018), 551–577. https://doi.org/10.1111/rssb.12265 doi: 10.1111/rssb.12265
|
| [13] |
C. Ye, Y. Yang, Y. Yang, Sparsity oriented importance learning for high-dimensional linear regression, J. Am. Stat. Assoc., 113 (2018), 1797–1812. https://doi.org/10.1080/01621459.2017.1377080 doi: 10.1080/01621459.2017.1377080
|
| [14] |
D. Apley, J. Zhu, Visualizing the effects of predictor variables in black box supervised learning models, J. R. Stat. Soc. B, 82 (2020), 1059–1086. https://doi.org/10.1111/rssb.12377 doi: 10.1111/rssb.12377
|
| [15] |
A. Goldstein, A. Kapelner, J. Bleich, E. Pitkin, Peeking inside the black box: visualizing statistical learning with plots of individual conditional expectation, J. Comput. Graphical Stat., 24 (2015), 44–65. https://doi.org/10.1080/10618600.2014.907095 doi: 10.1080/10618600.2014.907095
|
| [16] | B. Greenwell, B. Boehmke, A. McCarthy, A simple and effective model-based variable importance measure, preprint, arXiv: 1805.04755, 2018. |









Figures(10)
Kelvyn Bladen, D. Richard Cutler. Assessing agreement between permutation and dropout variable importance methods for regression and random forest models[J]. Electronic Research Archive, 2024, 32(7): 4495-4514. doi: 10.3934/era.2024203







 DownLoad:
DownLoad: