In order to effectively mitigate the deterioration of pavement and roadbed, the need for extensive repairs and costly reconstruction ought to be minimized. Hence, this study introduces a novel approach towards long-term preservation of asphalt pavement, which conducts in-depth research on pavement maintenance decision-making using the decision tree method. The selection of appropriate decision-making indicators is based on their respective significance and the actual maintenance requirements, from which a comprehensive decision model for asphalt pavement maintenance is developed. By employing the Analytic Hierarchy Process (AHP) and a network-level optimization decision-making approach, this study investigates the allocation of maintenance decisions, structural preservation, optimal combinations of maintenance strategies, and fund allocation schemes. The result is the development of a project-level and network-level structural preservation decision optimization method. Furthermore, a decision-making module is designed to accompany this method, facilitating the visualization of comprehensive data and decision-making plans. This module enhances the effectiveness and efficiency of the decision-making process by providing a user-friendly interface and a clear presentation of data-driven insights and decision outcomes. The case study clearly proved the applicability and rationality of the long-term preservation strategy of structures based on intelligent decision-making, which laid the foundation for the sustainable development of pavement maintenance and development.
Citation: Jiuda Huang, Chao Han, Wuju Wei, Chengjun Zhao. Analysis of long-term maintenance decision for asphalt pavement based on analytic hierarchy process and network level optimization decision[J]. Electronic Research Archive, 2023, 31(9): 5894-5916. doi: 10.3934/era.2023299
In order to effectively mitigate the deterioration of pavement and roadbed, the need for extensive repairs and costly reconstruction ought to be minimized. Hence, this study introduces a novel approach towards long-term preservation of asphalt pavement, which conducts in-depth research on pavement maintenance decision-making using the decision tree method. The selection of appropriate decision-making indicators is based on their respective significance and the actual maintenance requirements, from which a comprehensive decision model for asphalt pavement maintenance is developed. By employing the Analytic Hierarchy Process (AHP) and a network-level optimization decision-making approach, this study investigates the allocation of maintenance decisions, structural preservation, optimal combinations of maintenance strategies, and fund allocation schemes. The result is the development of a project-level and network-level structural preservation decision optimization method. Furthermore, a decision-making module is designed to accompany this method, facilitating the visualization of comprehensive data and decision-making plans. This module enhances the effectiveness and efficiency of the decision-making process by providing a user-friendly interface and a clear presentation of data-driven insights and decision outcomes. The case study clearly proved the applicability and rationality of the long-term preservation strategy of structures based on intelligent decision-making, which laid the foundation for the sustainable development of pavement maintenance and development.

| [1] |
S. A. Mitoulis, D. V. Bompa, S. Argyroudis, Sustainability and climate resilience metrics and trade-offs in transport infrastructure asset recovery, Transp. Res. Part D Transp. Environ., 121 (2023), 103800. https://doi.org/10.1016/j.trd.2023.103800 doi: 10.1016/j.trd.2023.103800

|
| [2] |
N. S. P. Peraka, K. P. Biligiri, Pavement asset management systems and technologies: a review, Autom. Constr., 119 (2020), 103336. https://doi.org/10.1016/j.autcon.2020.103336 doi: 10.1016/j.autcon.2020.103336
|
| [3] | B. Yu, X. Gu, F. Ni, R. Guo, Multi-objective optimization for asphalt pavement maintenance plans at project level: integrating performance, cost and environment, Transp. Res. Part D Transp. Environ., 41 (2015), 64–74. https://doi:10.1016/j.trd.2015.09.016" target="_blank">10.1016/j.trd.2015.09.016">https://doi:10.1016/j.trd.2015.09.016 |
| [4] |
D. Jorge, A. Ferreira, Road network pavement maintenance optimisation using the HDM-4 pavement performance prediction models, Int. J. Pavement Eng., 13 (2012), 39–51. https://doi.org/10.1080/10298436.2011.563851 doi: 10.1080/10298436.2011.563851
|
| [5] |
A. Kazemeini, O. Swei, Identifying environmentally sustainable pavement management strategies via deep reinforcement learning, J. Cleaner Prod., 390 (2023), 136124. https://doi:10.1016/j.jclepro.2023.136124 doi: 10.1016/j.jclepro.2023.136124
|
| [6] |
J. D. Lin, M. C. Ho, A comprehensive analysis on the pavement condition indices of freeways and the establishment of a pavement management system, J. Traffic Transp. Eng., 3 (2016), 456–464. https://doi.org/10.1016/j.jtte.2016.09.003 doi: 10.1016/j.jtte.2016.09.003
|
| [7] |
H. Shon, C. S. Cho, Y. J. Byon, J. Lee, Autonomous condition monitoring-based pavement management system, Autom. Constr., 138 (2022), 104222. https://doi.org/10.1016/j.autcon.2022.104222 doi: 10.1016/j.autcon.2022.104222
|
| [8] |
H. Shon, J. Lee, Integrating multi-scale inspection, maintenance, rehabilitation, and reconstruction decisions into system-level pavement management systems, Transp. Res. Part C Emerging Technol., 131 (2021), 103328. https://doi.org/10.1016/j.trc.2021.103328 doi: 10.1016/j.trc.2021.103328
|
| [9] |
S. Thyagarajan, Pavement management systems, Int. Encycl. Transp., 2021 (2021), 524–530. https://doi.org/10.1016/B978-0-08-102671-7.10378-1 doi: 10.1016/B978-0-08-102671-7.10378-1
|
| [10] |
L. Zhang, W. Gu, Y. J. Byon, J. Lee, Condition-based pavement management systems accounting for model uncertainty and facility heterogeneity with belief updates, Transp. Res. Part C Emerging Technol., 148 (2023), 104054. https://doi.org/10.1016/j.trc.2023.104054 doi: 10.1016/j.trc.2023.104054
|
| [11] |
H. Li, F. Ni, Q. Dong, Y. Zhu, Application of analytic hierarchy process in network level pavement maintenance decision-making, Int. J. Pavement Res. Technol., 11 (2018), 345–354. https://doi.org/10.1016/j.ijprt.2017.09.015 doi: 10.1016/j.ijprt.2017.09.015
|
| [12] |
X. Hu, A. N. M. Faruk, J. Zhang, M. I. Souliman, L. F. Walubita, Effects of tire inclination (turning traffic) and dynamic loading on the pavement stress–strain responses using 3-D finite element modeling, Int. J. Pavement Res. Technol., 10 (2017), 304–314. https://doi.org/10.1016/j.ijprt.2017.04.005 doi: 10.1016/j.ijprt.2017.04.005
|
| [13] |
L. F. Walubita, E. Mahmoud, S. I. Lee, G. Carrasco, J. J. Komba, L. Fuentes, et al., Use of grid reinforcement in HMA overlays – a Texas field case study of highway US 59 in Atlanta District, Constr. Build. Mater., 213 (2019), 325–336. https://doi.org/10.1016/j.conbuildmat.2019.04.072 doi: 10.1016/j.conbuildmat.2019.04.072
|
| [14] |
W. Cao, A. Wang, D. Yu, S. Liu, W. Hou, Establishment and implementation of an asphalt pavement recycling decision system based on the analytic hierarchy process, Resour. Conserv. Recycl., 149 (2019), 738–749. https://doi.org/10.1016/j.resconrec.2019.06.028 doi: 10.1016/j.resconrec.2019.06.028
|
| [15] |
Y. Lu, Y. Ge, G. Zhang, A. Abdulwahab, A. A. Salameh, H. E. Ali, et al., Evaluation of waste management and energy saving for sustainable green building through analytic hierarchy process and artificial neural network model, Chemosphere, 318 (2023), 137708. https://doi.org/10.1016/j.chemosphere.2022.137708 doi: 10.1016/j.chemosphere.2022.137708
|
| [16] |
S. T. Mosissa, S. Zhongwei, W. H. Tsegaye, E. A. Teklemariam, Prioritization of green infrastructure planning principles using analytic hierarchy process: the case of Addis Ababa, Urban For. Urban Greening, 85 (2023), 127965. https://doi.org/10.1016/j.ufug.2023.127965 doi: 10.1016/j.ufug.2023.127965
|
| [17] |
B. Srdjevic, Z. Srdjevic, Prioritisation in the analytic hierarchy process for real and generated comparison matrices, Expert Syst. Appl., 225 (2023), 120015. https://doi.org/10.1016/j.eswa.2023.120015 doi: 10.1016/j.eswa.2023.120015
|
| [18] |
R. Jiang, P. Wu, C. Wu, Selecting the optimal network-level pavement maintenance budget scenario based on sustainable considerations, Transp. Res. Part D Transp. Environ., 97 (2021), 102919. https://doi.org/10.1016/j.trd.2021.102919 doi: 10.1016/j.trd.2021.102919
|
| [19] |
J. M. De la Garza, S. Akyildiz, D. R. Bish, D. A. Krueger, Network-level optimization of pavement maintenance renewal strategies, Adv. Eng. Inf., 25 (2011), 699–712. https://doi.org/10.1016/j.aei.2011.08.002 doi: 10.1016/j.aei.2011.08.002
|
| [20] |
J. Li, G. Yin, X. Wang, W. Yan, Automated decision making in highway pavement preventive maintenance based on deep learning, Autom. Constr., 135 (2022), 104111. https://doi.org/10.1016/j.autcon.2021.104111 doi: 10.1016/j.autcon.2021.104111
|
| [21] |
M. Nasimifar, R. Kamalizadeh, B. Heidary, The available approaches for using traffic speed deflectometer data at network level pavement management system, Measurement, 202 (2022), 111901. https://doi.org/10.1016/j.measurement.2022.111901 doi: 10.1016/j.measurement.2022.111901
|
| [22] |
S. Hanandeh, Introducing mathematical modeling to estimate pavement quality index of flexible pavements based on genetic algorithm and artificial neural networks, Case Stud. Constr. Mater., 16 (2022), e00991. https://doi.org/10.1016/j.cscm.2022.e00991 doi: 10.1016/j.cscm.2022.e00991
|
| [23] |
W. Dong, W. Li, Y. Guo, Z. Sun, F. Qu, R. Liang, et al., Application of intrinsic self-sensing cement-based sensor for traffic detection of human motion and vehicle speed, Constr. Build. Mater., 355 (2022), 129130. https://doi.org/10.1016/j.conbuildmat.2022.129130 doi: 10.1016/j.conbuildmat.2022.129130
|
| [24] |
T. Wang, S. Faßbender, W. Dong, C. Schulze, M. Oeser, P. Liu, Sensitive surface layer: a review on conductive and piezoresistive pavement materials with carbon-based additives, Constr. Build. Mater. , 387 (2023), 131611. https://doi.org/10.1016/j.conbuildmat.2023.131611 doi: 10.1016/j.conbuildmat.2023.131611
|
| [25] |
X. Wang, Y. Zhong, Reflective crack in semi-rigid base asphalt pavement under temperature-traffic coupled dynamics using XFEM, Constr. Build. Mater. , 214 (2019), 280–289. https://doi.org/10.1016/j.conbuildmat.2019.04.125 doi: 10.1016/j.conbuildmat.2019.04.125
|
| [26] |
X. Xia, D. Han, Y. Zhao, Y. Xie, Z. Zhou, J. Wang, Investigation of asphalt pavement crack propagation based on micromechanical finite element: a case study, Case Stud. Constr. Mater., 19 (2023), e02247. https://doi.org/10.1016/j.cscm.2023.e02247 doi: 10.1016/j.cscm.2023.e02247
|
| [27] | Z. Chen, D. Wang, Numerical analysis of a multi-objective maintenance decision-making model for sustainable highway networks: integrating the GDE3 method, LCA and LCCA, Energy Build., 290 (2023), 113096. https://doi.org/10.1016/j.enbuild.2023.113096 |
| [28] | M. Montoya-Alcaraz, A. Mungaray-Moctezuma, L. García, Sustainable road maintenance planning in developing countries based on pavement management systems: case study in Baja California, México, Sustainability, 12 (2020), 36. https://doi.org/10.3390/su12010036 |
| [29] |
S. M. Piryonesi, T. E. El-Diraby, Examining the relationship between two road performance indicators: pavement condition index and international roughness index, Transp. Geotech., 26 (2021), 100441. https://doi.org/10.1016/j.trgeo.2020.100441 doi: 10.1016/j.trgeo.2020.100441
|
| [30] | Y. Sun, M. Hu, W. Zhou, W. Xu, Multiobjective optimization for pavement network maintenance and rehabilitation programming: a case study in Shanghai, China, Math. Probl. Eng., 2020 (2020), 3109156. https://doi.org/10.1155/2020/3109156 |
| [31] |
W. Chen, M. Zheng, Multi-objective optimization for pavement maintenance and rehabilitation decision-making: a critical review and future directions, Autom. Constr., 130 (2021), 103840. https://doi.org/10.1016/j.autcon.2021.103840 doi: 10.1016/j.autcon.2021.103840
|
| [32] |
J. Fang, F. Y. Partovi, Criteria determination of analytic hierarchy process using a topic model, Expert Syst. Appl., 169 (2021), 114306. https://doi.org/10.1016/j.eswa.2020.114306 doi: 10.1016/j.eswa.2020.114306
|
| [33] |
M. Hafez, K. Ksaibati, R. Atadero, Pavement maintenance practices of low-volume roads and potential enhancement: the regional experience of Colorado pavement management system, Int. J. Pavement Eng., 22 (2019), 718–731. https://doi.org/10.1080/10298436.2019.1643021 doi: 10.1080/10298436.2019.1643021
|
| [34] |
J. Santos, S. Bressi, V. Cerezo, D. L. Presti, SUP & R DSS: a sustainability-based decision support system for road pavements, J. Cleaner Prod., 206 (2019), 524–540. https://doi.org/10.1016/j.jclepro.2018.08.308 doi: 10.1016/j.jclepro.2018.08.308
|
| [35] |
L. Fuentes, R. Camargo, G. Martínez-Arguelles, J. J. Komba, B. Naik, L. F. Walubita, Pavement serviceability evaluation using whole body vibration techniques: a case study for urban roads, Int. J. Pavement Eng., 22 (2019), 1238–1249. https://doi.org/10.1080/10298436.2019.1672872 doi: 10.1080/10298436.2019.1672872
|
| [36] |
L. Fuentes, K. Taborda, X. Hu, E. Horak, T. Bai, L. F. Walubita, A probabilistic approach to detect structural problems in flexible pavement sections at network level assessment, Int. J. Pavement Eng., 23 (2020), 1867–1880. https://doi.org/10.1080/10298436.2020.1828586 doi: 10.1080/10298436.2020.1828586
|
| [37] |
F. Zhou, X. Hu, S. Hu, L. F. Walubita, T. Scullion, Incorporation of crack propagation in the M-E fatigue cracking prediction, Road Mater. Pavement Des., 9 (2011), 433–465. https://doi.org/10.1080/14680629.2008.9690178 doi: 10.1080/14680629.2008.9690178
|
| [38] |
R. M. Khalifa, S. Yacout, S. Bassetto, Developing machine-learning regression model with logical analysis of data (LAD), Comput. Ind. Eng., 151 (2021), 106947. https://doi.org/10.1016/j.cie.2020.106947 doi: 10.1016/j.cie.2020.106947
|
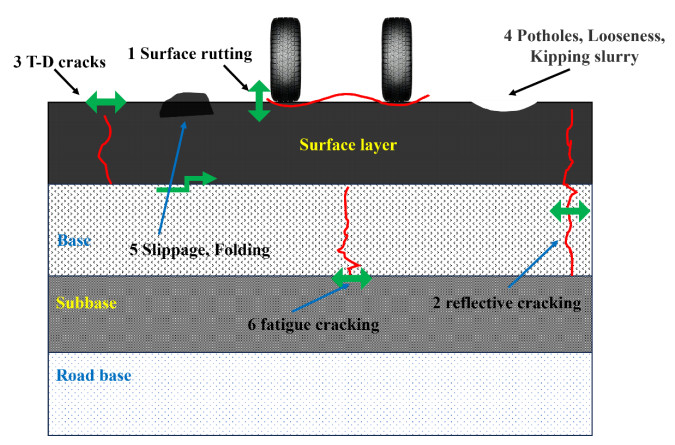







Figures(8) / Tables(12)
Jiuda Huang, Chao Han, Wuju Wei, Chengjun Zhao. Analysis of long-term maintenance decision for asphalt pavement based on analytic hierarchy process and network level optimization decision[J]. Electronic Research Archive, 2023, 31(9): 5894-5916. doi: 10.3934/era.2023299







 DownLoad:
DownLoad: