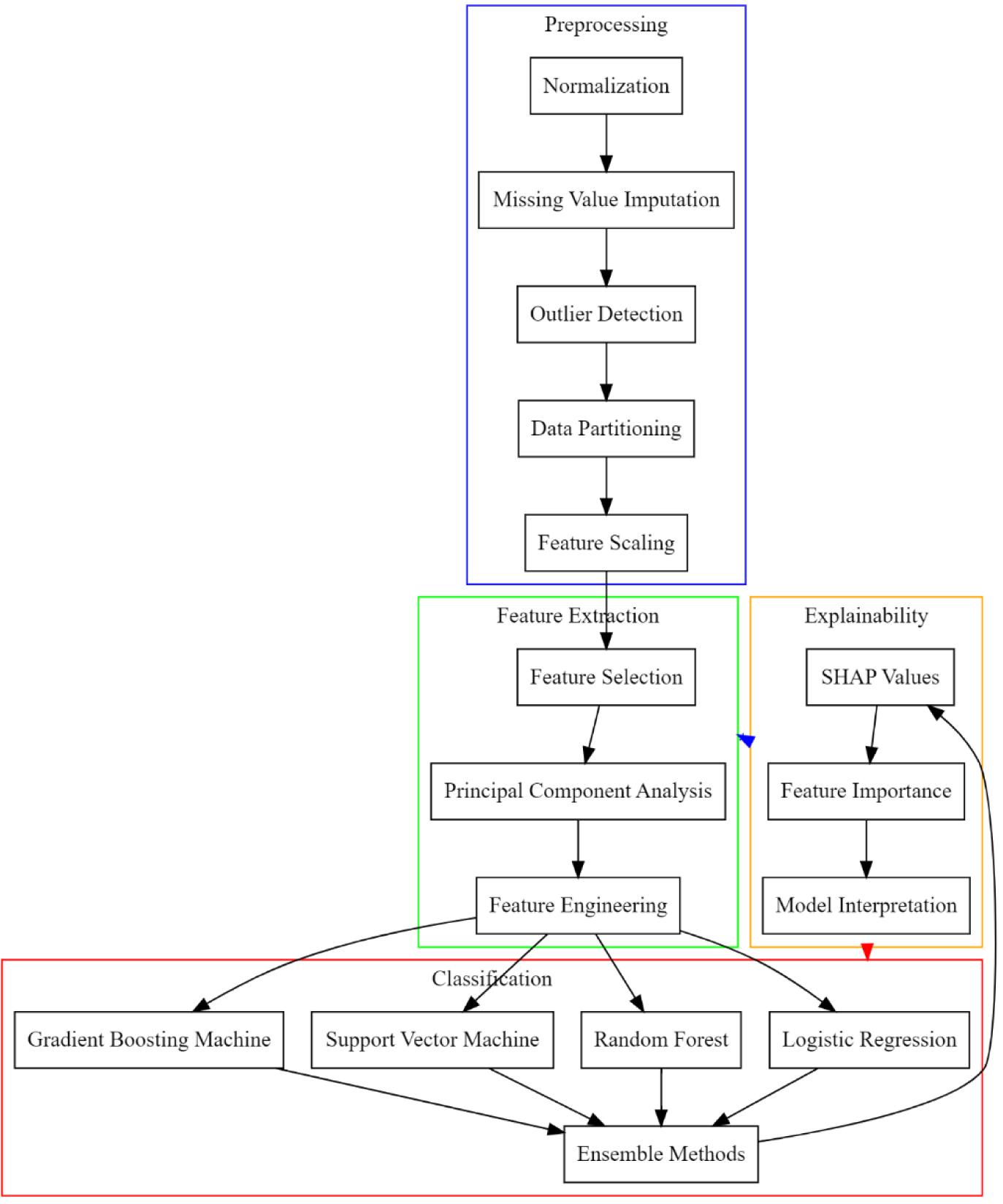
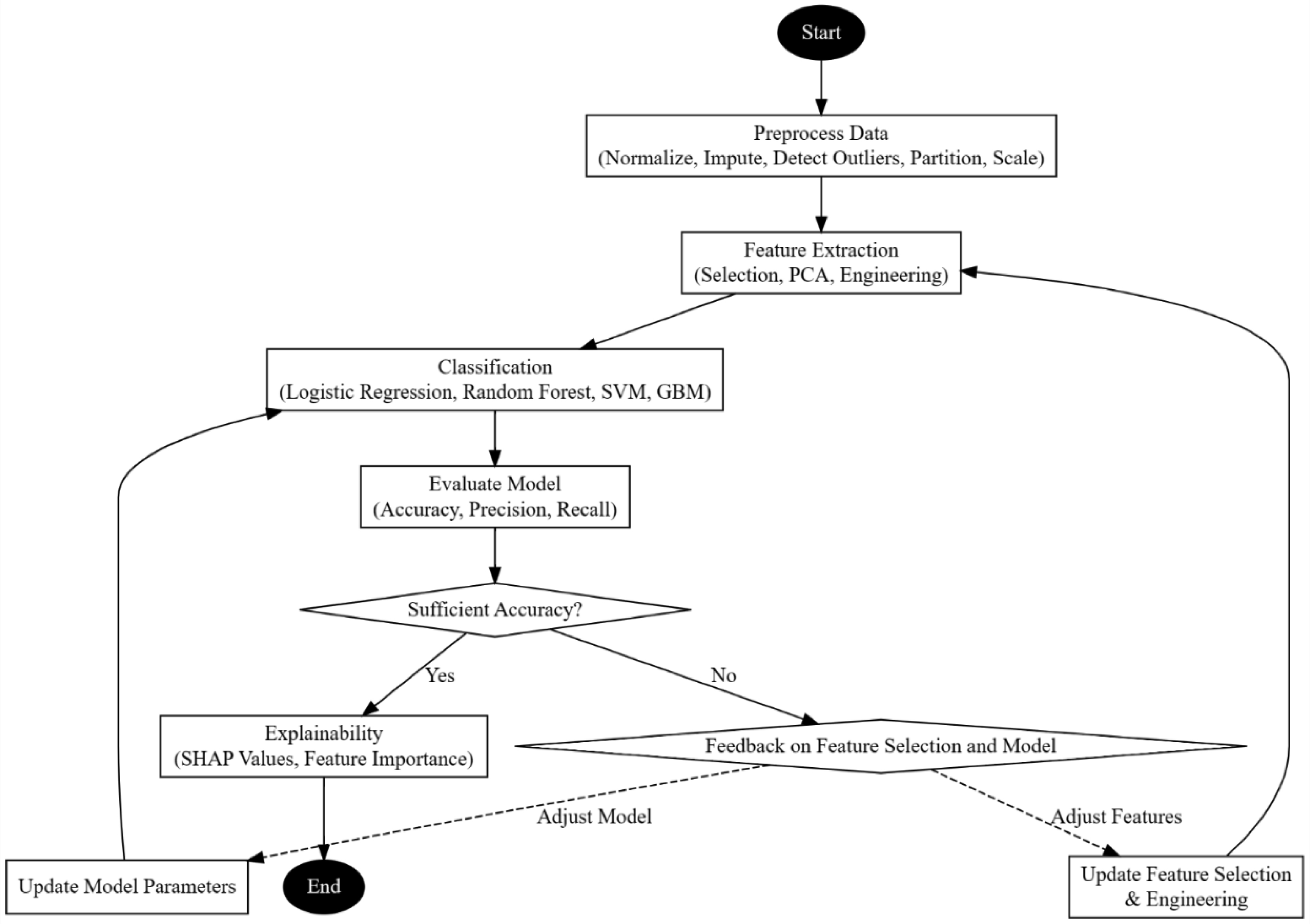
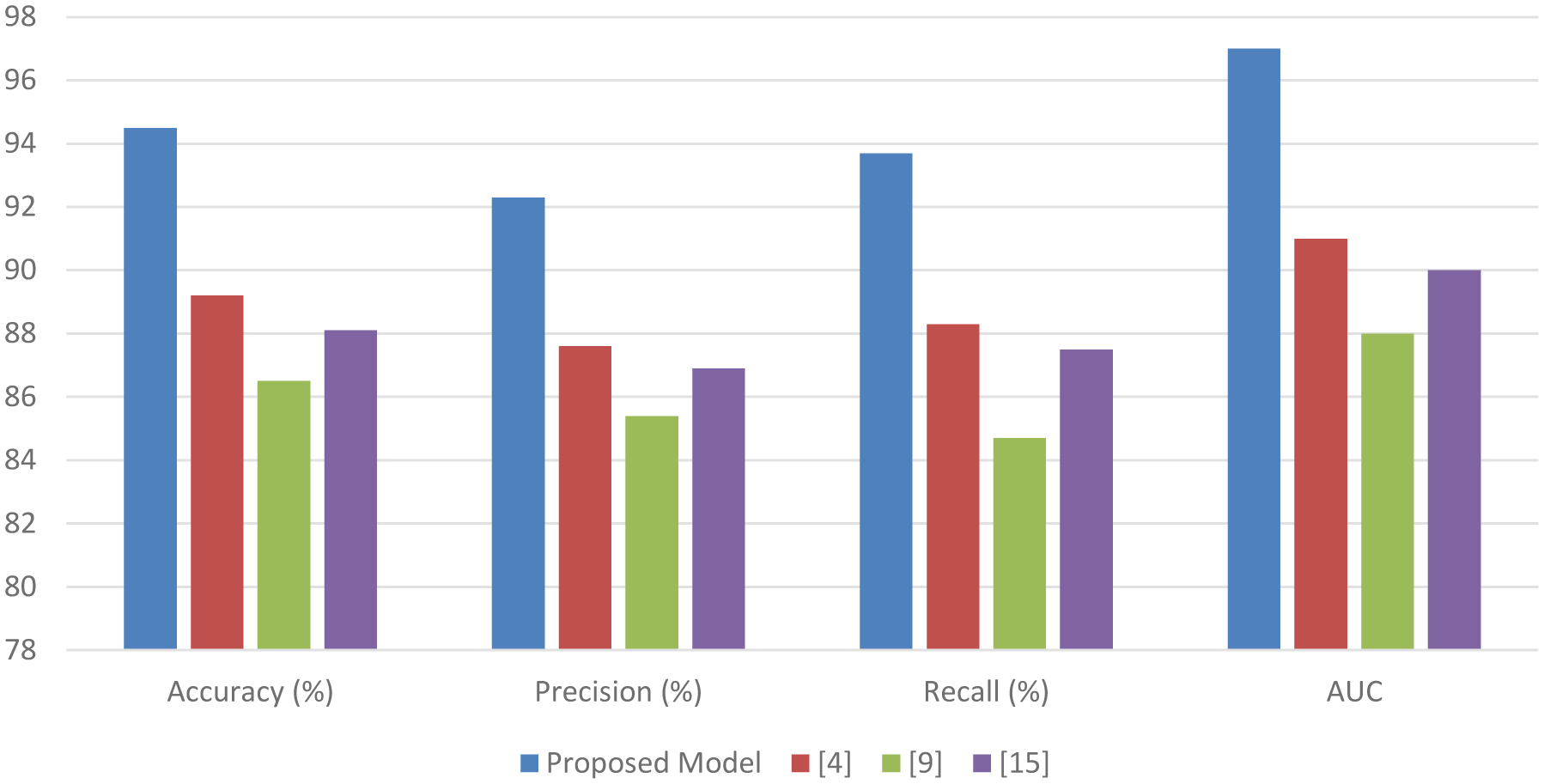
The escalating prevalence and acute manifestations of Acute Coronary Syndrome (ACS) necessitate advanced early detection mechanisms. Traditional methodologies exhibit limitations in predictive accuracy, sensitivity, and timeliness, thus hindering effective intervention and patient care management. This study introduces a comprehensive machine learning-based approach to surmount these constraints, thereby enhancing early ACS prediction capabilities for different scenarios. Addressing data integrity, the methodology encompasses rigorous data preprocessing techniques, including advanced missing value imputation and outlier detection, to ensure dataset reliability. Feature selection is meticulously conducted through a recursive feature elimination and correlation analysis, thereby distilling critical predictive indicators from extensive clinical datasets. The study harnesses diverse algorithms—Support Vector Machines, Logistic Regression, Gradient Boosting Machines, and Deep Forest—tailored for nuanced ACS detection, balancing simplicity with computational depth to optimize performance metrics. The proposed model exhibits a superior predictive proficiency, as evidenced by significant improvements in precision, accuracy, recall, and reduced prediction delay compared to the existing approaches. The Logistic Regression coefficients and the SHapley Additive exPlanations (SHAP) values provide interpretative insights into the risk factor significance, facilitating personalized patient risk assessments. Furthermore, the study pioneers a clinically applicable risk scoring system, which is thoroughly evaluated through sensitivity, specificity, and positive predictive value metrics. Implications of this research extend beyond theoretical advancement, offering tangible enhancements in ACS predictive analytics. The enhanced model promises improved patient outcomes through timely and accurate ACS detection, thus optimizing healthcare resource allocation. Future research directions are identified, which advocate for the exploration of novel risk factors and the application of cutting-edge machine learning techniques to foster inclusivity and adaptability in diverse healthcare settings.
Citation: Shital Hajare, Rajendra Rewatkar, K.T.V. Reddy. Design of an iterative method for enhanced early prediction of acute coronary syndrome using XAI analysis[J]. AIMS Bioengineering, 2024, 11(3): 301-322. doi: 10.3934/bioeng.2024016
The escalating prevalence and acute manifestations of Acute Coronary Syndrome (ACS) necessitate advanced early detection mechanisms. Traditional methodologies exhibit limitations in predictive accuracy, sensitivity, and timeliness, thus hindering effective intervention and patient care management. This study introduces a comprehensive machine learning-based approach to surmount these constraints, thereby enhancing early ACS prediction capabilities for different scenarios. Addressing data integrity, the methodology encompasses rigorous data preprocessing techniques, including advanced missing value imputation and outlier detection, to ensure dataset reliability. Feature selection is meticulously conducted through a recursive feature elimination and correlation analysis, thereby distilling critical predictive indicators from extensive clinical datasets. The study harnesses diverse algorithms—Support Vector Machines, Logistic Regression, Gradient Boosting Machines, and Deep Forest—tailored for nuanced ACS detection, balancing simplicity with computational depth to optimize performance metrics. The proposed model exhibits a superior predictive proficiency, as evidenced by significant improvements in precision, accuracy, recall, and reduced prediction delay compared to the existing approaches. The Logistic Regression coefficients and the SHapley Additive exPlanations (SHAP) values provide interpretative insights into the risk factor significance, facilitating personalized patient risk assessments. Furthermore, the study pioneers a clinically applicable risk scoring system, which is thoroughly evaluated through sensitivity, specificity, and positive predictive value metrics. Implications of this research extend beyond theoretical advancement, offering tangible enhancements in ACS predictive analytics. The enhanced model promises improved patient outcomes through timely and accurate ACS detection, thus optimizing healthcare resource allocation. Future research directions are identified, which advocate for the exploration of novel risk factors and the application of cutting-edge machine learning techniques to foster inclusivity and adaptability in diverse healthcare settings.

| [1] |
Sahoo HS, Ingraham NE, Silverman GM, et al. (2022) Towards fairness and interpretability: Clinical decision support for acute coronary syndrome. 21st IEEE International Conference on Machine Learning and Applications (ICMLA) : 882-886. https://doi.org/10.1109/ICMLA55696.2022.00146 
|
| [2] |
Jamthikar AD, Gupta D, Mantella LE, et al. (2022) Ensemble machine learning and its validation for prediction of coronary artery disease and acute coronary syndrome using focused carotid ultrasound. IEEE T Instrum Meas 71: 1-10. http://dx.doi.org/10.1109/TIM.2021.3139693
|
| [3] | Kumar DK, Kavitha S (2023) Secondary prevention of acute coronary syndrome using data science analysis and profile representation. 2023 International Conference on Recent Advances in Science and Engineering Technology (ICRASET) : 1-6. http://dx.doi.org/10.1109/ICRASET59632.2023.10420312 |
| [4] |
Zheng H, Sherazi SWA, Lee JY (2021) A stacking ensemble prediction model for the occurrences of major adverse cardiovascular events in patients with acute coronary syndrome on imbalanced data. IEEE Access 9: 113692-113704. http://dx.doi.org/10.1109/ACCESS.2021.3099795
|
| [5] |
García-García A., Prieto-Egido I, Guerrero-Curieses A, et al. (2021) Data science analysis and profile representation applied to secondary prevention of acute coronary syndrome. IEEE Access 9: 78607-78620. http://dx.doi.org/10.1109/ACCESS.2021.3083523
|
| [6] | Khalaf F, Baskaran SS (2023) Predicting acute respiratory failure using fuzzy classifier. 2023 International Conference on IT Innovation and Knowledge Discovery (ITIKD) : 1-4. https://doi.org/10.1109/ITIKD56332.2023.10099746 |
| [7] | Chaniotakis V, Koumakis L, Kondylakis H, et al. (2021) Predictive analytics based on open source technologies for acute respiratory distress syndrome. IEEE 34th International Symposium on Computer-Based Medical Systems (CBMS) : 68-73. http://dx.doi.org/10.1109/CBMS52027.2021.00019 |
| [8] | Kabdullin A, Kabdullin M, Naizabayeva L (2021) Optimizing neural network performance to predict coronary heart disease. IEEE International Conference on Smart Information Systems and Technologies (SIST) : 1-4. https://doi.org/10.1109/SIST50301.2021.9465925 |
| [9] | Manjunathan N, Girirajan S, Jaganathan D (2022) Cardiovascular disease prediction using enhanced support vector machine algorithm. 6th International Conference on Computing Methodologies and Communication (ICCMC) : 295-302. https://doi.org/10.1109/ICCMC53470.2022.9753916 |
| [10] |
Chiorean IA, Amico B, Combi C, et al. (2021) A reproducible ETL approach for window-based prediction of acute kidney injury in critical care unit and some preliminary results with support vector machines. 2021 IEEE International Conference on Bioinformatics and Biomedicine (BIBM) : 3532-3539. https://doi.org/10.1109/BIBM52615.2021.9669143
|
| [11] | Noushin T, Jeong J, Lee JB JB (2023) Real-time monitoring of inflammation in metabolic syndrome with electrochemical detection of tyramine level in urine. 2023 IEEE Sensors : 1-4. https://doi.org/10.1109/SENSORS56945.2023.10325228 |
| [12] | Chen S, Zheng R, Wang T, et al. (2022) Deterministic learning-based west syndrome analysis and seizure detection on ECG. IEEE T Circuits-II 69: 4603-4607. https://doi.org/10.1109/TCSII.2022.3188162 |
| [13] | Lyu L, Wang W, Lin Y, et al. (2023) Dronedarone's efficacy in preventing arrhythmias during myocardial ischemia or short QT syndrome: A computational study. 2023 Computing in Cardiology (CinC) : 1-4. https://doi.org/10.22489/CinC.2023.224 |
| [14] | Ezilarasan MR, Sathyasri B, MuthuKumaran D (2023) IoT based detection and monitoring for coronary artery disease. 9th International Conference on Smart Structures and Systems (ICSSS) : 1-5. https://doi.org/10.1109/ICSSS58085.2023.10407838 |
| [15] | Aggarwal S, Pandey K (2023) PCOS diagnosis with commonly known diseases using hybrid machine learning algorithms. 6th International Conference on Contemporary Computing and Informatics (IC3I) : 1658-1662. https://doi.org/10.1109/IC3I59117.2023.10397717 |
| [16] |
Dembovskiy M, Nikulina S, Kosorukov A (2021) Development of a biotechnical magnetopletysmography system for monitoring respiratory rate and heart rate. 2021 Ural Symposium on Biomedical Engineering, Radioelectronics and Information Technology (USBEREIT) : 0016-0019. http://dx.doi.org/10.1109/USBEREIT51232.2021.9455107
|
| [17] | Chauhan A, Naga KS, Hasija Y (2021) Pharmacogenomics based study for liraglutide and metfromin (PCOS drugs) efficacy in populations across the globe. 12th International Conference on Computing Communication and Networking Technologies (ICCCNT) : 1-6. https://doi.org/10.1109/ICCCNT51525.2021.9579679 |
| [18] | Lam JY, Kanegaye JT, Xu E, et al. (2023) A deep learning framework for image-based screening of kawasaki disease. 45th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC) : 1-4. http://dx.doi.org/10.1109/EMBC40787.2023.10340801 |
| [19] | de Chazal P, Sadr N, Dissanayake H, et al. (2021) Predicting cardiovascular outcomes using the respiratory event desaturation transient area derived from overnight sleep studies. 43rd Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC) : 5496-5499. https://doi.org/10.1109/EMBC46164.2021.9630610 |
| [20] | Romero D, Jané R (2022) Detecting obstructive apnea episodes using dynamic bayesian networks and ECG-based time-series. 44th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC) : 3273-3276. https://doi.org/10.1109/EMBC48229.2022.9870930 |
| [21] | Anishchenko L, Lobanova V, Bochkarev M, et al. (2021) Two-channel bioradar system for sleep-disordered breathing detection. International Conference on e-Health and Bioengineering (EHB) : 1-4. https://doi.org/10.1109/EHB52898.2021.9657681 |
| [22] | Piljugin O, Badarin A, Antipov V, et al. (2022) Analysis of eye-tracking data during the Sternberg working memory task in subjects with asthenic syndrome. 6th Scientific School Dynamics of Complex Networks and their Applications (DCNA) : 219-222. https://doi.org/10.1109/DCNA56428.2022.9923207 |
| [23] | Tenekeci S, Isik Z (2022) Integrative biological network analysis to identify shared genes in metabolic disorders. IEEE ACM T Comput Bi 19: 522-530. https://doi.org/10.1109/TCBB.2020.2993301 |
| [24] |
Junejo AR, Li X (2021) A systematic analysis: Molecular information in viral disease using deep learning auto encoder. International Conference on Computer, Blockchain and Financial Development (CBFD) : 281-285. https://doi.org/10.1109/CBFD52659.2021.00063
|
| [25] | Rajeyyagari S, Gopal R, Saravanan P, et al. (2023) A novel enhanced krill herd optimization based quality prediction for health care services. International Conference on Computer Science and Emerging Technologies (CSET) : 1-7. http://dx.doi.org/10.1109/CSET58993.2023.10346965 |
| [26] | Zhang H, Fu B, Su K, et al. (2023) Long-term sleep respiratory monitoring by dual-channel flexible wearable system and deep learning-aided analysis. IEEE T Instrum Meas 72: 1-9. https://doi.org/10.1109/TIM.2023.3289535 |
| [27] |
De Filippo O, Cammann VL, Pancotti C, et al. (2023) Machine learning-based prediction of in-hospital death for patients with takotsubo syndrome: The InterTAK-ML model. Eur J Heart Fail 25: 2299-2311. http://dx.doi.org/10.1002/ejhf.2983
|
Figures(3) / Tables(6)

Shital Hajare, Rajendra Rewatkar, K.T.V. Reddy. Design of an iterative method for enhanced early prediction of acute coronary syndrome using XAI analysis[J]. AIMS Bioengineering, 2024, 11(3): 301-322. doi: 10.3934/bioeng.2024016







 DownLoad:
DownLoad: