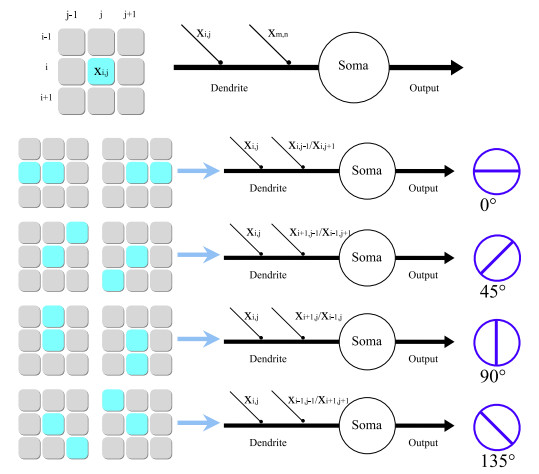
As the most studied sensory system, the visual system plays an important role in our understanding of brain functions. Biological researchers have divided the nerve cells in the retina into dozens of visual channels carrying various characteristics based on visual features. Although orientation-selective cells have been identified in the retinas of various animals, the specific neural circuits of such cells have been controversial. In this study, a new simple and efficient orientation detection model based on the perceptron is proposed to restore the neural circuitry of orientation-selective cells in the retina. The performance of this model is experimentally compared with that of the convolutional neural network for image orientation recognition, and the results verify that the proposed model offers very good orientation detection. The proposed perceptron-based orientation detection model provides a new perspective to explain the neural circuits of orientation-selective cells.
Citation: Fenggang Yuan, Cheng Tang, Zheng Tang, Yuki Todo. A model of amacrine cells for orientation detection[J]. Electronic Research Archive, 2023, 31(4): 1998-2018. doi: 10.3934/era.2023103
As the most studied sensory system, the visual system plays an important role in our understanding of brain functions. Biological researchers have divided the nerve cells in the retina into dozens of visual channels carrying various characteristics based on visual features. Although orientation-selective cells have been identified in the retinas of various animals, the specific neural circuits of such cells have been controversial. In this study, a new simple and efficient orientation detection model based on the perceptron is proposed to restore the neural circuitry of orientation-selective cells in the retina. The performance of this model is experimentally compared with that of the convolutional neural network for image orientation recognition, and the results verify that the proposed model offers very good orientation detection. The proposed perceptron-based orientation detection model provides a new perspective to explain the neural circuits of orientation-selective cells.

| [1] | D. Milner, M. Goodale, The Visual Brain in Action, OUP Oxford, 2006. https://doi.org/10.1093/acprof:oso/9780198524724.001.0001 |
| [2] | S. T. Fiske, S. E. Taylor, Social Cognition, Mcgraw-Hill Book Company, 1991. |
| [3] | M. J. Tovée, An Introduction to the Visual System, Cambridge University Press, 1996. |
| [4] |
D. C. Burr, M. C. Morrone, J. Ross, Selective suppression of the magnocellular visual pathway during saccadic eye movements, Nature, 371 (1994), 511–513. https://doi.org/10.1038/371511a0 doi: 10.1038/371511a0

|
| [5] |
T. Soldatos, D. Karakitsos, K. Chatzimichail, M. Papathanasiou, A. Gouliamos, A. Karabinis, Optic nerve sonography in the diagnostic evaluation of adult brain injury, Crit. Care, 12 (2008), R67. https://doi.org/10.1186/cc6897 doi: 10.1186/cc6897
|
| [6] |
A. Kaneko, Receptive field organization of bipolar and amacrine cells in the goldfish retina, J. Physiol., 235 (1973), 133–153. https://doi.org/10.1113/jphysiol.1973.sp010381 doi: 10.1113/jphysiol.1973.sp010381
|
| [7] |
D. I. Vaney, B. Sivyer, W. R. Taylor, Direction selectivity in the retina: symmetry and asymmetry in structure and function, Nat. Rev. Neurosci., 13 (2012), 194–208. https://doi.org/10.1038/nrn3165 doi: 10.1038/nrn3165
|
| [8] |
T. Baden, P. Berens, K. Franke, M. R. Rosón, M. Bethge, T. Euler, The functional diversity of retinal ganglion cells in the mouse, Nature, 529 (2016), 345–350. https://doi.org/10.1038/nature16468 doi: 10.1038/nature16468
|
| [9] |
H. R. Maturana, S. Frenk, Directional movement and horizontal edge detectors in the pigeon retina, Science, 142 (1963), 977–979. https://doi.org/10.1126/science.142.3594.977 doi: 10.1126/science.142.3594.977
|
| [10] |
W. R. Levick, Receptive fields and trigger features of ganglion cells in the visual streak of the rabbit's retina, J. Physiol., 188 (1967), 285–307. https://doi.org/10.1113/jphysiol.1967.sp008140 doi: 10.1113/jphysiol.1967.sp008140
|
| [11] |
D. H. Hubel, T. N. Wiesel, Receptive fields, binocular interaction and functional architecture in the cat's visual cortex, J. Physiol., 160 (1962), 106–154. https://doi.org/10.1113/jphysiol.1962.sp006837 doi: 10.1113/jphysiol.1962.sp006837
|
| [12] |
W. R. Levick, L. N. Thibos, Orientation bias of cat retinal ganglion cells, Nature, 286 (1980), 389–390. https://doi.org/10.1038/286389a0 doi: 10.1038/286389a0
|
| [13] |
W. R. Levick, L. N. Thibos, Analysis of orientation bias in cat retina, J. Physiol., 329 (1982), 243–261. https://doi.org/10.1113/jphysiol.1982.sp014301 doi: 10.1113/jphysiol.1982.sp014301
|
| [14] |
L. N. Thibos, W. R. Levick, Orientation bias of brisk-transient y-cells of the cat retina for drifting and alternating gratings, Exp. Brain Res., 58 (1985), 1–10. https://doi.org/10.1007/BF00238948 doi: 10.1007/BF00238948
|
| [15] |
E. Sernagor, N. M. Grzywacz, Emergence of complex receptive field properties of ganglion cells in the developing turtle retina, J. Neurophysiol., 73 (1995), 1355–1364. https://doi.org/10.1152/jn.1995.73.4.1355 doi: 10.1152/jn.1995.73.4.1355
|
| [16] |
J. H. Marshel, A. P. Kaye, I. Nauhaus, E. M. Callaway, Anterior-posterior direction opponency in the superficial mouse lateral geniculate nucleus, Neuron, 76 (2012), 713–720. https://doi.org/10.1016/j.neuron.2012.09.021 doi: 10.1016/j.neuron.2012.09.021
|
| [17] |
D. M. Piscopo, R. N. El-Danaf, A. D. Huberman, C. M. Niell, Diverse visual features encoded in mouse lateral geniculate nucleus, J. Neurophysiol., 33 (2013), 4642–4656. https://doi.org/10.1523/JNEUROSCI.5187-12.2013 doi: 10.1523/JNEUROSCI.5187-12.2013
|
| [18] |
B. Scholl, A. Y. Y. Tan, J. Corey, N. J. Priebe, Emergence of orientation selectivity in the mammalian visual pathway, J. Neurophysiol., 33 (2013), 10616–10624. https://doi.org/10.1523/JNEUROSCI.0404-13.2013 doi: 10.1523/JNEUROSCI.0404-13.2013
|
| [19] |
I. Damjanović, E. Maximova, V. Maximov, On the organization of receptive fields of orientation-selective units recorded in the fish tectum, J. Integr. Neurosci., 8 (2009), 323–344. https://doi.org/10.1142/S0219635209002174 doi: 10.1142/S0219635209002174
|
| [20] |
J. Johnston, H. Ding, S. H. Seibel, F. Esposti, L. Lagnado, Rapid mapping of visual receptive fields by filtered back projection: application to multi-neuronal electrophysiology and imaging, J. Neurophysiol., 592 (2014), 4839–4854. https://doi.org/10.1113/jphysiol.2014.276642 doi: 10.1113/jphysiol.2014.276642
|
| [21] |
N. Nikolaou, A. S. Lowe, A. S. Walker, F. Abbas, P. R. Hunter, I. D. Thompson, et al., Parametric functional maps of visual inputs to the tectum, Neuron, 76 (2012), 317–324. https://doi.org/10.1016/j.neuron.2012.08.040 doi: 10.1016/j.neuron.2012.08.040
|
| [22] |
A. S. Lowe, N. Nikolaou, P. R. Hunter, I. D. Thompson, M. P. Meyer, A systems-based dissection of retinal inputs to the zebrafish tectum reveals different rules for different functional classes during development, J. Neurophysiol., 33 (2013), 13946–13956. https://doi.org/10.1523/JNEUROSCI.1866-13.2013 doi: 10.1523/JNEUROSCI.1866-13.2013
|
| [23] |
P. Antinucci, N. Nikolaou, M. P. Meyer, R. Hindges, Teneurin-3 specifies morphological and functional connectivity of retinal ganglion cells in the vertebrate visual system, Cell Rep., 5 (2013), 582–592. https://doi.org/10.1016/j.celrep.2013.09.045 doi: 10.1016/j.celrep.2013.09.045
|
| [24] |
P. Antinucci, O. Suleyman, C. Monfries, R. Hindges, Neural mechanisms generating orientation selectivity in the retina, Curr. Biol., 26 (2016), 1802–1815. https://doi.org/10.1016/j.cub.2016.05.035 doi: 10.1016/j.cub.2016.05.035
|
| [25] |
S. A. Bloomfield, Two types of orientation-sensitive responses of amacrine cells in the mammalian retina, Nature, 350 (1991), 347–350. https://doi.org/10.1038/350347a0 doi: 10.1038/350347a0
|
| [26] |
S. A. Bloomfield, Orientation-sensitive amacrine and ganglion cells in the rabbit retina, J. Neurophysiol., 71 (1994), 1672–1691. https://doi.org/10.1152/jn.1994.71.5.1672 doi: 10.1152/jn.1994.71.5.1672
|
| [27] |
R. Nelson, E. V. F. Jr, H. Kolb, Intracellular staining reveals different levels of stratification for on-and off-center ganglion cells in cat retina, J. Neurophysiol., 41 (1978), 472–483. https://doi.org/10.1152/jn.1978.41.2.472 doi: 10.1152/jn.1978.41.2.472
|
| [28] | F. Rosenblatt, The Perceptron, A perceiving and Recognizing Automaton Project Para, Cornell Aeronautical Laboratory, 1957. |
| [29] |
J. R. Huguenard, Low-threshold calcium currents in central nervous system neurons, Annu. Rev. Physiol., 58 (1996), 329–348. https://doi.org/10.1146/annurev.ph.58.030196.001553 doi: 10.1146/annurev.ph.58.030196.001553
|
| [30] |
A. Borst, T. Euler, Seeing things in motion: models, circuits, and mechanisms, Neuron, 71 (2011), 974–994. https://doi.org/10.1016/j.neuron.2011.08.031 doi: 10.1016/j.neuron.2011.08.031
|
| [31] | A. B. Watson, G. Y. Yang, J. A. Solomon, J. D. Villasenor, Visual thresholds for wavelet quantization error, in Hum. Vision Electron. Imaging, 2657 (1996), 382–392. https://doi.org/10.1117/12.238735 |
| [32] |
S. Lawrence, C. L. Giles, A. C. Tsoi, A. D. Back, Face recognition: a convolutional neural-network approach, IEEE Trans. Neural Networks, 8 (1997), 98–113. https://doi.org/10.1109/72.554195 doi: 10.1109/72.554195
|
| [33] |
F. A. Gerritsen, P. W. Verbeek, Implementation of cellular-logic operators using 33 convolution and table lookup hardware, Comput. Vision Graphics Image Process., 27 (1984), 115–123. https://doi.org/10.1016/0734-189X(84)90086-0 doi: 10.1016/0734-189X(84)90086-0
|
| [34] | M. Liang, X. Hu, Recurrent convolutional neural network for object recognition, in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), (2015), 3367–3375. Available from: https://openaccess.thecvf.com/content_cvpr_2015/html/Liang_Recurrent_Convolutional_Neural_2015_CVPR_paper.html. |
| [35] | K. Fukushima, S. Miyake, Neocognitron: a self-organizing neural network model for a mechanism of visual pattern recognition, in Competition and Cooperation in Neural Nets, (1982), 267–285. https://doi.org/10.1007/978-3-642-46466-9_18 |
| [36] |
A. Waibel, Modular construction of time-delay neural networks for speech recognition, Neural Comput., 1 (1989), 39–46. https://doi.org/10.1162/neco.1989.1.1.39 doi: 10.1162/neco.1989.1.1.39
|
| [37] | W. Zhang, J. Tanida, K. Itoh, Y. Ichioka, Shift-invariant pattern recognition neural network and its optical architecture, in Proceedings of Annual Conference of the Japan Society of Applied Physics, (1988), 2147–2151. |
| [38] |
C. Garcia, M. Delakis, Convolutional face finder: a neural architecture for fast and robust face detection, IEEE Trans. Pattern Anal. Mach. Intell., 26 (2004), 1408–1423. https://doi.org/10.1109/TPAMI.2004.97 doi: 10.1109/TPAMI.2004.97
|
| [39] | J. Platt, S. Nowlan, A convolutional neural network hand tracker, Proc. Adv. Neural Inf. Process. Syst., 1995 (1995), 901–908. Available from: https://www.microsoft.com/en-us/research/wp-content/uploads/2016/02/cnnHand.pdf. |
| [40] |
S. Greenland, S. J. Senn, K. J. Rothman, J. B. Carlin, C. Poole, S. N. Goodman, et al., Statistical tests, p values, confidence intervals, and power: a guide to misinterpretations, Eur. J. Epidemiol., 31 (2016), 337–350. https://doi.org/10.1007/s10654-016-0149-3 doi: 10.1007/s10654-016-0149-3
|











Figures(12) / Tables(11)
Fenggang Yuan, Cheng Tang, Zheng Tang, Yuki Todo. A model of amacrine cells for orientation detection[J]. Electronic Research Archive, 2023, 31(4): 1998-2018. doi: 10.3934/era.2023103







 DownLoad:
DownLoad: