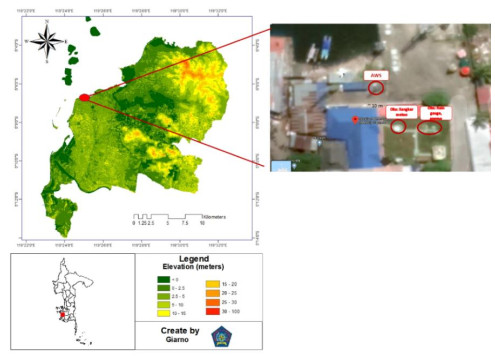
The shift from manual weather measurements to automation is almost inevitable. When switching to AWS (Automatic Weather Station), WMO requires parallel data testing between automatic and manual measurements to be performed. The purpose of this paper is to conduct a parallel test of AWS data using a simple statistical test that has been applied to three main weather parameters, namely temperature, pressure, humidity, rainfall, and wind direction and speed. The months of January and June were used as samples to represent the character of the wet and dry seasons in the Makassar monsoon area. The results of the analysis show that during the rainy season, only pressure and temperature are identical and homogeneous. Meanwhile, in the dry season, apart from these two parameters, humidity and wind speed are also homogeneous and rainfall is a non-homogeneous parameter in January and June. Both AWS and manual observations show that the influence of land-sea winds in Makassar is very strong. Considering that there are inhomogeneous parameters, it is highly recommended to test for a longer time, taking into account the season, the influence of other global phenomena, the effect of missing data and incorrect data testing various methods of homogeneity and characteristics in each place and their effect on forecasts.
Citation: Nurtiti Sunusi, Giarno. Bias of automatic weather parameter measurement in monsoon area, a case study in Makassar Coast[J]. AIMS Environmental Science, 2023, 10(1): 1-15. doi: 10.3934/environsci.2023001
The shift from manual weather measurements to automation is almost inevitable. When switching to AWS (Automatic Weather Station), WMO requires parallel data testing between automatic and manual measurements to be performed. The purpose of this paper is to conduct a parallel test of AWS data using a simple statistical test that has been applied to three main weather parameters, namely temperature, pressure, humidity, rainfall, and wind direction and speed. The months of January and June were used as samples to represent the character of the wet and dry seasons in the Makassar monsoon area. The results of the analysis show that during the rainy season, only pressure and temperature are identical and homogeneous. Meanwhile, in the dry season, apart from these two parameters, humidity and wind speed are also homogeneous and rainfall is a non-homogeneous parameter in January and June. Both AWS and manual observations show that the influence of land-sea winds in Makassar is very strong. Considering that there are inhomogeneous parameters, it is highly recommended to test for a longer time, taking into account the season, the influence of other global phenomena, the effect of missing data and incorrect data testing various methods of homogeneity and characteristics in each place and their effect on forecasts.

| [1] |
Sunusi N, Giarno (2022) Comparison of some schemes for determining the optimal number of rain gauges in a specific area: A case study in an urban area of South Sulawesi, Indonesia. AIMS Environ Sci 9: 260–276. http://doi.org/10.3934/environsci.2022018 doi: 10.3934/environsci.2022018

|
| [2] |
Giarno, Muflihah, Mujahidin (2020) Determination of optimal rain gauge on the coastal region use coefficient variation: Case study in Makassar. J Civ Eng Forum 7: 121–132. https://doi.org/10.22146/jcef.58378 doi: 10.22146/jcef.58378
|
| [3] | WMO (2017) Challenges in the Transition from Conventional to Automatic Meteorological Observing Networks for Long-term Climate Records. Available from: https://library.wmo.int/doc_num.php?explnum_id=4217. |
| [4] | WMO (1994) Guide to Hydrological Practices: Data Acquisition and Processing, Analysis, Forecasting and Other Applications. Available from: https://portal.camins.upc.edu/materials_guia/250144/2013/WMOENG.pdf. |
| [5] | WMO (2008) Guide to Meteorological Instruments and Methods of Observation. Available from: https://www.posmet.ufv.br/wp-content/uploads/2016/09/MET-474-WMO-Guide.pdf. |
| [6] |
Milewska E, Hogg WD (2002) Continuity of climatological observations with automation-temperature and precipitation amounts from AWOS (Automated Weather Observing System). Atmos Ocean 40: 333–359. https://doi.org/10.3137/ao.400304 doi: 10.3137/ao.400304
|
| [7] | Zahumenský I (2004) Guidelines on Quality Control Procedures for Data from Automatic Weather Stations. Available from: https://www.researchgate.net/publication/228826920_Guidelines_on_Quality_Control_Procedures_for_Data_from_Automatic_Weather_Stations. |
| [8] | Wang Y, Liu XN, Ju XH (2006) Differences between automatic and manual meteorological observation. TECO-2006–WMO Technical Conference on Meteorological and Environmental Instruments and Methods of Observation. |
| [9] | Wang Y, Liu XN, Ren ZH (2006) Initial analysis of AWS-observed temperature. TECO-2006–WMO Technical Conference on Meteorological and Environmental Instruments and Methods of Observation. |
| [10] |
Guttman RNB, Baker CB (1996) Exploratory analysis of the difference between temperature observations recorded by ASOS and conventional methods. B Am Meteorol Soc 77: 2865–2873. https://doi.org/10.1175/1520-0477(1996)077%3c2865:EAOTDB%3e2.0.CO; 2 doi: 10.1175/1520-0477(1996)077<2865:EAOTDB>2.0.CO;2
|
| [11] | Brandsma T (2011) In: Parallel air temperature measurements at the KNMI-trrain in De Bilt (the Netherlands) May 2003–April 2005, interim report. Netherlands: KNMI. |
| [12] |
Sunusi N, Herdiani ET, Nirwan I (2017) Modeling of extreme rainfall recurrence time by using point process models. J Environ Sci Technol 10: 320–324. https://doi.org/10.3923/jest.2017.320.324 doi: 10.3923/jest.2017.320.324
|
| [13] | Aprilina K, Nuraini TA, Sopaheluwakan A (2017) Preliminary statistical assesment of temperature data obtained from parallel automatic and manual observation. JMG 18: 13–20. |
| [14] |
Giarno, Hadi MP, Suprayogi S, et al. (2018) Distribution of accuracy of TRMM daily rainfall in Makassar Strait. For Geo 32: 38–52. http://doi.org/10.23917/forgeo.v32i1.5774 doi: 10.23917/forgeo.v32i1.5774
|
| [15] |
Wang ZL, Zhong RD, Lai CG, et al. (2017) Evaluation of the GPM IMERG satellite-based precipitation products and the hydrological utility. Atmos Res 196: 151–163. https://doi.org/10.1016/j.atmosres.2017.06.020 doi: 10.1016/j.atmosres.2017.06.020
|
| [16] |
Tapiador FJ, Navarro A, Ortega EG, et al. (2020) The contribution of rain gauges in the calibration of the IMERG product: Results from the first validation over Spain. J Hydrometeorol 21: 161–182. https://doi.org/10.1175/jhm-d-19-0116.1 doi: 10.1175/JHM-D-19-0116.1
|
| [17] |
Tokay A, Petersen WA, Gatlin P, et al. (2013) Comparison of raindrop size distribution measurements by collocated disdrometers. J Atmos Ocean Tech 30: 1672–1690. https://doi.org/10.1175/JTECH-D-12-00163.1 doi: 10.1175/JTECH-D-12-00163.1
|
| [18] | Piticar A, Ristoiu D (2012) Analysis of air temperature evolution in northeastern Romania and evidence of warming trend. Carpathian J Earth Environ Sci 7: 97–106. |
| [19] |
Gentilucci M, Moustafa AA, Gawad FK, et al. (2021) Advances in Egyptian mediterranean coast climate change monitoring. Water 13: 1870. https://doi.org/10.3390/w13131870 doi: 10.3390/w13131870
|
| [20] |
Wijngaard JB, Klein Tank AMG, Können GP (2003) Homogeneity of 20th century European daily temperature and precipitation series. Int J Climatol 23: 679–692. https://doi.org/10.1002/joc.906 doi: 10.1002/joc.906
|
| [21] |
Farrell PJ, Stewart RK (2006) Comprehensive study of tests for normality and symmetry: Extending the spiegelhalter test. J Stat Comput Sim 76: 803–816. https://doi.org/10.1080/10629360500109023 doi: 10.1080/10629360500109023
|
| [22] | Majid AS, Dharmawan GSB, Heryanto DT, et al. (2017) Automation of surface observing network in BMKG. The WMO International Conference on Automatic Weather Stations (ICAWS-2017). |
| [23] |
Ranalkar M, Gupta M, Mishra R, et al. (2014) Network of automatic weather stations: Time division multiple access type. Mausam 65: 393–406. https://doi.org/10.54302/mausam.v65i3.1048 doi: 10.54302/mausam.v65i3.1048
|
| [24] | Chan PW, Shun CM (2007) Comparison of manual observations and instrumental readings of visibility at the Hong Kong International Airport. Hong Kong Meteorol Soc Bull 17: 94–98. |
| [25] | Petersen JF, Sack D, Gabler RE (2011) In: Fundamentals of physical geography, Boston: Cengage Learning. |
| [26] |
Karaseva MO, Prakash S, Gairola RM (2012) Validation of high-resolution TRMM-3B43 precipitation product using rain gauge measurements over Kyrgyzstan. Theor Appl Climatol 108: 147–157. https://doi.org/10.1007/s00704-011-0509-6 doi: 10.1007/s00704-011-0509-6
|
| [27] |
Prasetia R, As-syakur AR, Osawa T (2013) Validation of TRMM precipitation radar satellite data over Indonesian region. Theor Appl Climatol 112: 575–587. https://doi.org/10.1007/s00704-012-0756-1 doi: 10.1007/s00704-012-0756-1
|
| [28] |
Scheel MLM, Rohrer M, Huggel C, et al. (2011) Evaluation of TRMM multi-satellite precipitation analysis (TMPA) performance in the central Andes region and its dependency on spatial and temporal resolution. Hydrol Earth Syst Sci 15: 2649–2663. https://doi.org/10.5194/hess-15-2649-2011 doi: 10.5194/hess-15-2649-2011
|
| [29] |
Guo H, Chen S, Bao AM, et al. (2016) Comprehensive evaluation of high-resolution satellite-based precipitation products over China. Atmosphere 7: 6. https://doi.org/10.3390/atmos7010006 doi: 10.3390/atmos7010006
|
| [30] | Saber M, Yilmaz K (2016) Bias correction of satellite-based rainfall estimates for modeling flash floods in semi-arid regions: Application to Karpuz River, Turkey. Nat Hazards Earth Syst Sci Discuss. In press. https://doi.org/10.5194/nhess-2016-339 |
| [31] |
Tan ML, Ibrahim AL, Duan Z, et al. (2015) Evaluation of six high-resolution satellite and ground-based precipitation products over Malaysia. Remote Sens 7: 1504–1528. https://doi.org/10.3390/rs70201504 doi: 10.3390/rs70201504
|
| [32] | McCarroll D (2016) In: Simple statistical tests for geography, Boca Raton: CRC Press. |
| [33] | EGU (2017) European Geosciences Union General Assembly 2017. Available from: https://meetingorganizer.copernicus.org/EGU2017/orals/22780. |








Figures(9) / Tables(4)

Nurtiti Sunusi, Giarno. Bias of automatic weather parameter measurement in monsoon area, a case study in Makassar Coast[J]. AIMS Environmental Science, 2023, 10(1): 1-15. doi: 10.3934/environsci.2023001







 DownLoad:
DownLoad: