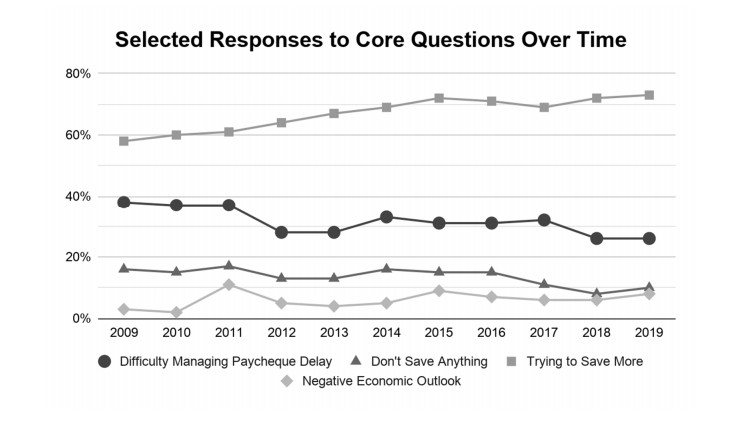
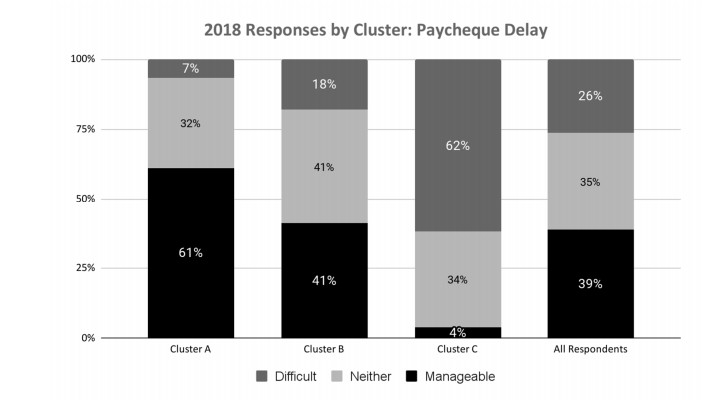
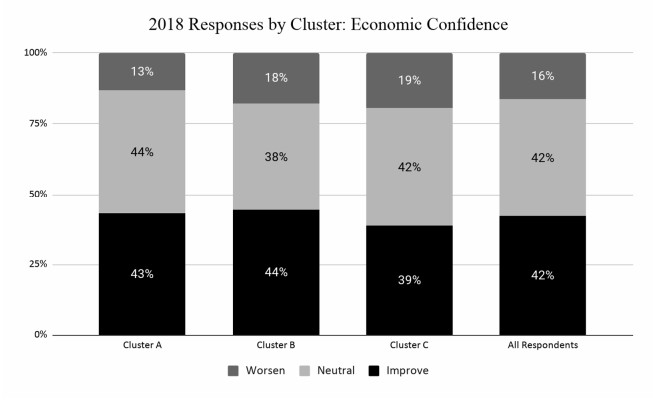
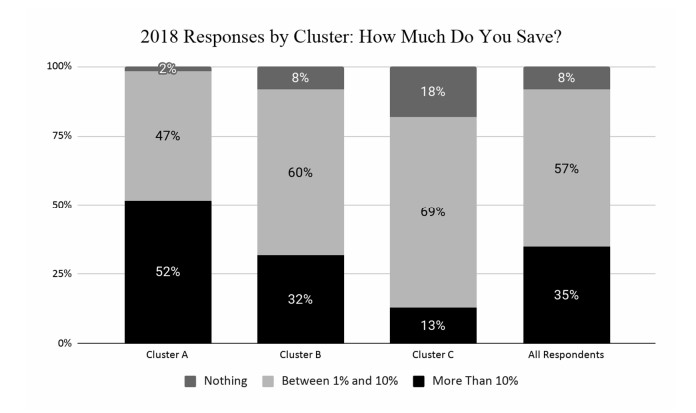
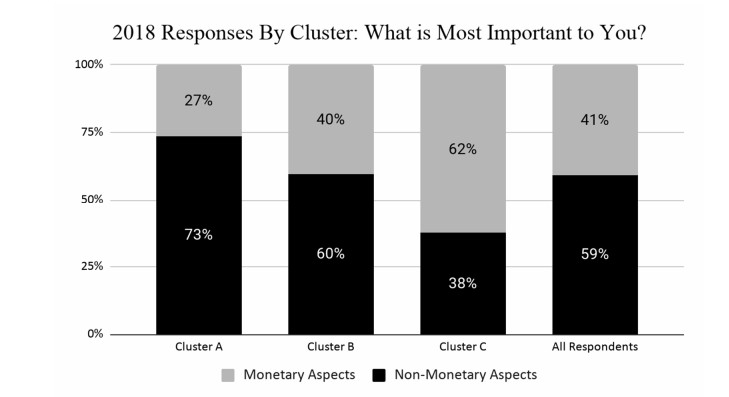
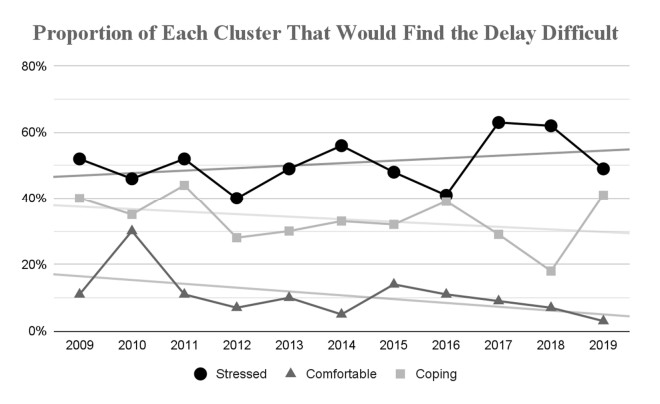
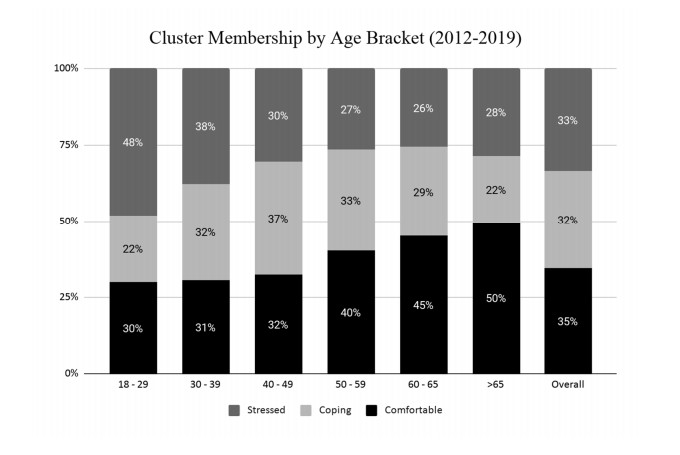
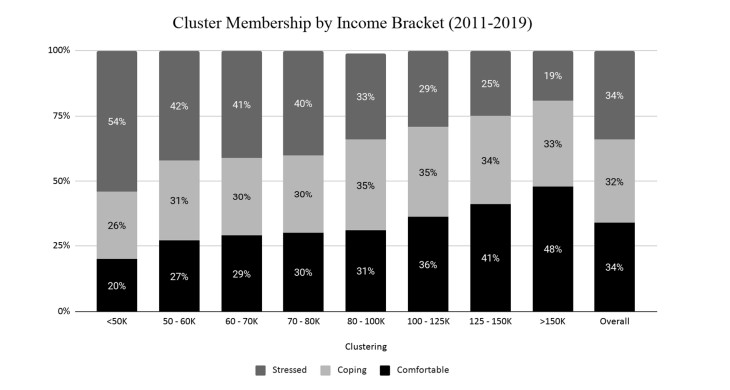
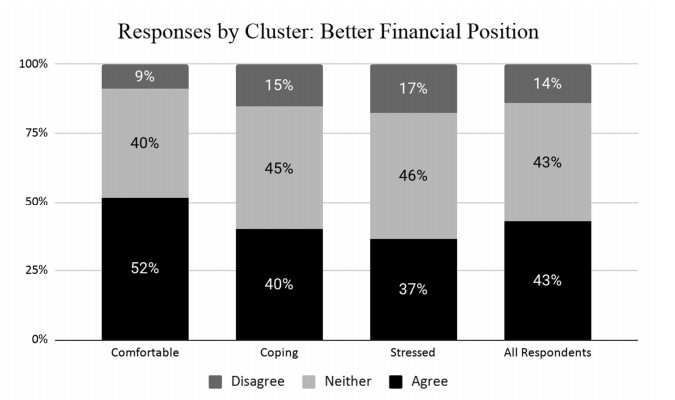
This paper applies cluster analysis to eleven (continuous) years' worth of responses to the Canadian Payroll Association (CPA) survey of employed Canadians. The clustering algorithm clearly identifies three distinct groups of respondents. Between-group comparison of response patterns reveals that two of the groups lie on opposite sides of the financial health spectrum, and leads us to label their members "financially stressed" and "financially capable", respectively. The third group shares characteristics with both the stressed and capable groups, and we label its members as "financially coping". We find that financial stress is both widespread (one third of all respondents are identified as stressed) and complex (stress is only weakly related to simple demographics such as age or income). From a methodological perspective, an important point is that our use of cluster analysis allows us to generate rigorous insights into financial well-being, without having to measure it directly.
Citation: Adam Metzler, Yuhao Zhou, Chuck Grace. Learning about financial health in Canada[J]. Quantitative Finance and Economics, 2021, 5(3): 542-570. doi: 10.3934/QFE.2021024
This paper applies cluster analysis to eleven (continuous) years' worth of responses to the Canadian Payroll Association (CPA) survey of employed Canadians. The clustering algorithm clearly identifies three distinct groups of respondents. Between-group comparison of response patterns reveals that two of the groups lie on opposite sides of the financial health spectrum, and leads us to label their members "financially stressed" and "financially capable", respectively. The third group shares characteristics with both the stressed and capable groups, and we label its members as "financially coping". We find that financial stress is both widespread (one third of all respondents are identified as stressed) and complex (stress is only weakly related to simple demographics such as age or income). From a methodological perspective, an important point is that our use of cluster analysis allows us to generate rigorous insights into financial well-being, without having to measure it directly.

| [1] |
Arbelaitz O, Gurrutxaga I, Muguerza J, et al. (2013) An extensive comparative study of cluster validity indices. Pattern Recogn 46: 243-256. doi: 10.1016/j.patcog.2012.07.021

|
| [2] |
Bezdek J, Pal N (1998) Some new indexes of cluster validity. IEEE T Syst Man Cy B 28: 301-315. doi: 10.1109/3477.678624
|
| [3] |
Castro-González S, Fernández-López S, Rey-Ares L, et al. (2020) The influence of attitude to money on individuals' financial well-being. Soc Indic Res 148: 747-764. doi: 10.1007/s11205-019-02219-4
|
| [4] |
Collins JM, Urban C (2020) Measuring financial well-being over the lifecourse. Eur J Financ 26: 341-359. doi: 10.1080/1351847X.2019.1682631
|
| [5] | Financial Well-being: The Goal of Financial Education. Consumer Financial Protection Bureau, 2015. Available from: https://www.consumerfinance.gov/data-research/research-reports/financial-well-being/. |
| [6] | CFPB Financial Well-Being Scale: scale development and technical report. Consumer Financial Protection Bureau, 2017. Available from: https://www.consumerfinance.gov/data-research/research-reports/financial-well-being-technical-report/. |
| [7] | Cude BJ, Danns D, Kabaci MJ (2016) Financial knowledge and financial education of college students, In: Xiao JJ, Handbook of Consumer Finance Research, Eds., Springer. |
| [8] | DeVaney S (2016) Financial issues of older adults, In: Xiao JJ, Handbook of Consumer Finance Research, Eds., Springer. |
| [9] |
Foss AH, Markatou M, Ray B (2018) Distance metrics and clustering methods of mixed-type data. Int Stat Rev 87: 80-109. doi: 10.1111/insr.12274
|
| [10] | Gower JC (1971) A general coefficient of similarity and some of its properties. Biometrics 27: 857. |
| [11] | Gutter M, Copur Z (2011) Financial behaviors and financial well-being of college students: Evidence from a national survey. J Fam Econ Issues 32: 699–714. |
| [12] | Hinton G, Sejnowski TJ (1999) Unsupervised learning: Foundations of neural computation. Massachusetts Institute of Technology. |
| [13] |
Iramani R, Lutfi L (2021) An integrated model of financial well-being: The role of financial behaviour. Accounting 7: 691-700. doi: 10.5267/j.ac.2020.12.007
|
| [14] | Kaufman L, Rousseeuw PJ (1987) Clustering by means of medoids, In: Dodge Y, Statistical Data Analysis Based on the L1 Norm and Related Methods, Eds., Amsterdam: North Holland/Elsevier, 405-416. |
| [15] | Kempson E, Finney A, Poppe C (2017) Financial well-being: A conceptual model and preliminary analysis. Project Note #3-2017, Consumption Research Norway-SIFO, Oslo and Akershus University College of Applied Sciences. |
| [16] | Kempson E, Poppe C (2018) Understanding financial well-being capability: A revised model and comprehensive analysis. Professional Note #3-2018, Consumption Research Norway-SIFO, Oslo and Akershus University College of Applied Sciences. |
| [17] |
Lee JM, Lee J, Kim KT (2020) Consumer financial well-being: Knowledge is not enough. J Fam Econ Issues 41: 218-228. doi: 10.1007/s10834-019-09649-9
|
| [18] |
Likas A, Vlassis N, Verbeek JJ (2003) The global k-means clustering algorithm. Pattern Recogn 36: 451-461. doi: 10.1016/S0031-3203(02)00060-2
|
| [19] | Lusardi A, Schneider D, Tufano P (2011) Financially fragile households: Evidence and implications, In: Brookings Papers on Economic Activity, Eds., Spring, 83-134. |
| [20] | Madhulatha TS (2011) Comparison between k-Means and k-medoids clustering algorithms. Adv Comput Inform Technol Commun Comput Inform Sci, 472-481. |
| [21] |
Moscone F, Tosetti E, Vittadini G (2016) The impact of precarious employment on mental health: The case of Italy. Soc Sci Med 158: 86-95. doi: 10.1016/j.socscimed.2016.03.008
|
| [22] | Nanda AP, Banerjee R (2021) Consumer's subjective financial well-being: A systematic review and research agenda. Int J Consum Stud. |
| [23] | Nielsen RB, Fletcher CN, Bartholomae S (2016) Consumer finances of low-income individuals, In: Xiao JJ, Handbook of Consumer Finance Research, Eds., Springer. |
| [24] |
Prawitz AD, Cohart J (2016) Financial management competency, financial resources, locus of control, and financial wellness. J Financ Counsel Plan 27: 142-157. doi: 10.1891/1052-3073.27.2.142
|
| [25] | Prawitz AD, Garman ET, Sohaindo B, et al. (2006) InCharge Financial Distress/Financial Well-Being Scale: development, administration, and score interpretation. J Financ Counsel Plan 17: 34-50. |
| [26] | Prawtiz AD, Kalkowski JC, Cohart J (2012) Responses to economic pressure by low-income families: Financial distress and hopefulness. J Fam Econ Issues 34: 29–40 |
| [27] |
Reynolds AP, Richards G, Iglesia BD, et al. (2006) Clustering rules: A comparison of partitioning and hierarchical clustering algorithms. J Math Model Algorithms 5: 475-504. doi: 10.1007/s10852-005-9022-1
|
| [28] |
Rousseeuw PJ (1987) Silhouettes: A graphical aid to the interpretation and validation of cluster analysis. J Comput Appl Math 20: 53-65. doi: 10.1016/0377-0427(87)90125-7
|
| [29] |
Salignac F, Marjolin A, Reeve R, et al. (2019) Conceptualizing and measuring financial resilience: A multidimensional framework. Soc Indic Res 145: 17-38. doi: 10.1007/s11205-019-02100-4
|
| [30] | Strömback C, Skagerlund K, Västfjäll D, et al. (2020) Subjective self-control but not objective measures of executive functions predicts financial behaviour and well-being. J Exp Financ 27. |
| [31] |
Vlaev I, Elliot A (2014) Financial well-being components. Soc Indic Res 118: 1103-1123. doi: 10.1007/s11205-013-0462-0
|
| [32] | Xiao JJ (2016) Consumer financial capability and wellbeing, In: Xiao JJ, Handbook of Consumer Finance Research, Eds., Springer. |
| [33] |
Xu D, Tian Y (2015) A comprehensive survey of clustering algorithms. Ann Data Sci 2: 165-193. doi: 10.1007/s40745-015-0040-1
|
 QFE-05-03-024-s001.pdf QFE-05-03-024-s001.pdf |
 |
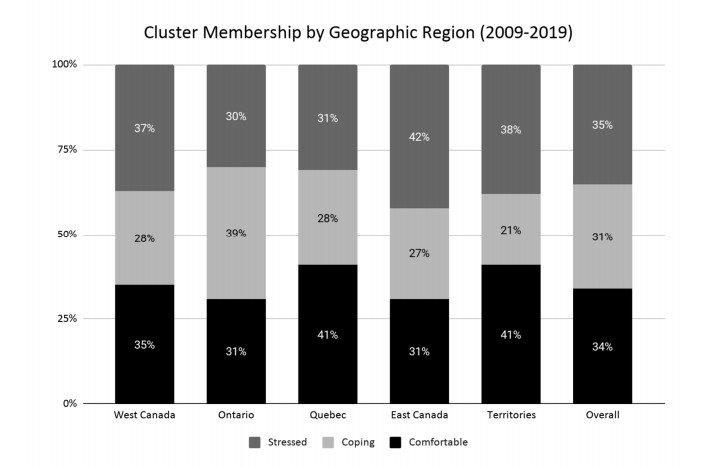
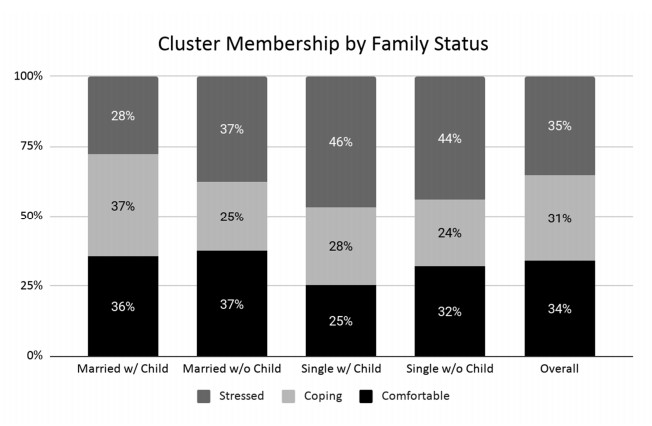
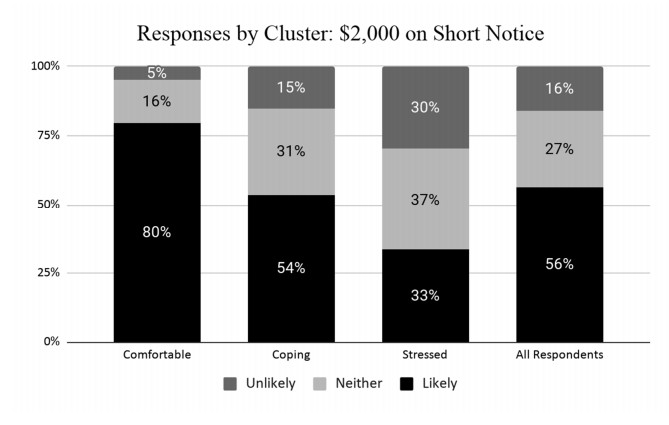
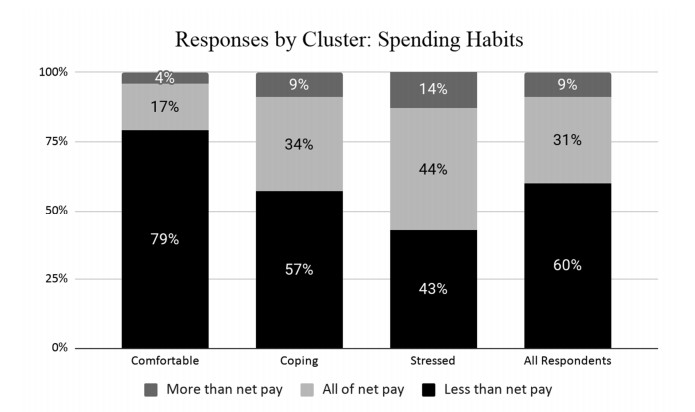
Figures(13) / Tables(6)

Adam Metzler, Yuhao Zhou, Chuck Grace. Learning about financial health in Canada[J]. Quantitative Finance and Economics, 2021, 5(3): 542-570. doi: 10.3934/QFE.2021024







 DownLoad:
DownLoad: