Following the keep-it-sophisticatedly-simple principle, KISS, we propose using the averaging window approach to forecast the market equity premium in unstable environments. First, the estimation methodology of averaging window is a theoretically justified method robust to uncertainties on structural breaks and estimation window sizes. Second, the averaging window method has the obvious advantages of being understandable to forecast users and simple to implement, thus encouraging engagement and criticism. Our empirical results demonstrate the superior performance of the averaging window when forecasting the U.S. market equity premium, exceeding a wide range of methods which have been shown effective, such as shrinkage estimators and technical indicators.
Citation: Anwen Yin. Equity premium prediction: keep it sophisticatedly simple[J]. Quantitative Finance and Economics, 2021, 5(2): 264-286. doi: 10.3934/QFE.2021012
Following the keep-it-sophisticatedly-simple principle, KISS, we propose using the averaging window approach to forecast the market equity premium in unstable environments. First, the estimation methodology of averaging window is a theoretically justified method robust to uncertainties on structural breaks and estimation window sizes. Second, the averaging window method has the obvious advantages of being understandable to forecast users and simple to implement, thus encouraging engagement and criticism. Our empirical results demonstrate the superior performance of the averaging window when forecasting the U.S. market equity premium, exceeding a wide range of methods which have been shown effective, such as shrinkage estimators and technical indicators.

| [1] |
Andrews D (1993) Tests for parameter instability and structural change with unknown change point. Econometrica 61: 821-856. doi: 10.2307/2951764

|
| [2] |
Andrews D, Ploberger W (1994) Optimal tests when a nuisance parameter is present only under the alternative. Econometrica 62: 1383-1414. doi: 10.2307/2951753
|
| [3] | Baetje F, Menkhoff L (2016) Equity premium prediction: Are economic and technical indicators unstable? Int J Forecasting 32: 1193-1207. |
| [4] |
Bai J, Perron P (1998) Estimating and testing linear models with multiple structural changes. Econometrica 66: 47-78. doi: 10.2307/2998540
|
| [5] |
Baltas N, Karyampas D (2018) Forecasting the equity risk premium: The importance of regime-dependent evaluation. J Financ Mark 32: 83-102. doi: 10.1016/j.finmar.2017.11.002
|
| [6] | Boot T, Pick A (2010) Does modeling a structural break improve forecast accuracy? J Econometrics 215: 35-59. |
| [7] |
Campbell J (1987) Stock returns and the term structure. J Financ Econ 18: 373-399. doi: 10.1016/0304-405X(87)90045-6
|
| [8] | Campbell J, Thompson S (2008) Predicting excess stock returns out of sample: can anything beat the historical average? Rev Financ Stud 21: 1509-1531. |
| [9] | Cenesizoglu T, Timmermann A (2012) Do return prediction models add economic value? J Bank Financ 36: 2974-2987. |
| [10] |
Chen B, Hong Y (2012) Testing smooth structural changes in time series models via nonparametric regression. Econometrica 80: 1157-1183. doi: 10.3982/ECTA7990
|
| [11] |
Clark T, McCracken M (2001) Tests of equal forecast accuracy and encompassing for nested models. J Econometrics 105: 85-110. doi: 10.1016/S0304-4076(01)00071-9
|
| [12] |
Clark T, McCracken M (2013) Advances in forecast evaluation. Handb Econ Forecasting 2: 1107-1201. doi: 10.1016/B978-0-444-62731-5.00020-8
|
| [13] |
Clark T, West K (2007) Approximately normal tests for equal predictive accuracy in nested models. J Econometrics 138: 291-311. doi: 10.1016/j.jeconom.2006.05.023
|
| [14] |
Dangl T, Halling M (2012) Predictive regressions with time-varying coefficients. J Financ Econ 106: 157-181. doi: 10.1016/j.jfineco.2012.04.003
|
| [15] |
Elliott G, Muller U (2006) Efficient tests for general persistent time variation in regression coefficients. Rev Econ Stud 73: 907-940. doi: 10.1111/j.1467-937X.2006.00402.x
|
| [16] |
Fama E, French K (1988) Dividend yields and expected stock returns. J Financ Econ 22: 3-25. doi: 10.1016/0304-405X(88)90020-7
|
| [17] |
Green K, Armstrong J (2015) Simple versus complex forecasting: the evidence. J Bus Res 68: 1678-1685. doi: 10.1016/j.jbusres.2015.03.026
|
| [18] |
Jiang F, Lee J, Martin X, et al. (2019) Manager sentiment and stock returns. J Financ Econ 132: 126-149. doi: 10.1016/j.jfineco.2018.10.001
|
| [19] |
Li J, Tsiakas I (2017) Equity premium prediction: the role of economic and statistical constraints. J Financ Mark 36: 56-75. doi: 10.1016/j.finmar.2016.09.001
|
| [20] |
Li Y, Ng D, Swaminathan B (2013) Predicting market returns using aggregate implied cost of capital. J Financ Econ 110: 419-436. doi: 10.1016/j.jfineco.2013.06.006
|
| [21] |
Ma C, Wen D, Wang G, et al. (2019) Further mining the predictability of moving averages: evidence from the US stock market. Int Rev Financ 19: 413-433. doi: 10.1111/irfi.12166
|
| [22] |
Neely C, Rapach D, Tu J, et al. (2014) Forecasting the equity risk premium: the role of technical indicators. Manage Sci 60: 1772-1791. doi: 10.1287/mnsc.2013.1838
|
| [23] |
Paye B, Timmermann A (2006) Instability of return prediction models. J Empir Financ 13: 274-315. doi: 10.1016/j.jempfin.2005.11.001
|
| [24] |
Pesaran M, Pick A (2011) Forecast combination across estimation windows. J Bus Econ Stat 29: 307-318. doi: 10.1198/jbes.2010.09018
|
| [25] |
Pesaran M, Pick A, Pranovich M (2011) Optimal forecasts in the presence of structural breaks. J Econometrics 177: 134-152. doi: 10.1016/j.jeconom.2013.04.002
|
| [26] |
Pesaran M, Timmermann A (2007) Selection of estimation window in the presence of breaks. J Econometrics 137: 134-161. doi: 10.1016/j.jeconom.2006.03.010
|
| [27] |
Pettenuzzo A, Timmermann A, Rossen V (2014) Forecasting stock returns under economic constraints. J Financ Econ 114: 517-553. doi: 10.1016/j.jfineco.2014.07.015
|
| [28] |
Pyun S (2019) Variance risk in aggregate stock returns and time-varying return predictability. J Financ Econ 132: 150-174. doi: 10.1016/j.jfineco.2018.10.002
|
| [29] |
Rapach D, Strauss J, Zhou G (2010) Out-of-sample equity premium prediction: combination forecasts and links to the real economy. Rev Financ Stud 23: 821-862. doi: 10.1093/rfs/hhp063
|
| [30] |
Rapach D, Wohar M (2006) Structural breaks and predictive regression models of aggregate US stock returns. J Financ Econometrics 4: 238-274. doi: 10.1093/jjfinec/nbj008
|
| [31] |
Rapach D, Ringgenberg M, Zhou G (2016) Short interest and aggregate stock returns. J Financ Econ 121: 46-65. doi: 10.1016/j.jfineco.2016.03.004
|
| [32] |
Timmermann A (2006) Forecast combinations. Handb Econ Forecasting 1: 135-196. doi: 10.1016/S1574-0706(05)01004-9
|
| [33] |
Timmermann A (2008) Elusive return predictability. Int J Forecasting 24: 1-18. doi: 10.1016/j.ijforecast.2007.07.008
|
| [34] |
Welch I, Goyal A (2008) A comprehensive look at the empirical performance of equity premium prediction. Rev Financ Stud 21: 1455-1508. doi: 10.1093/rfs/hhm014
|
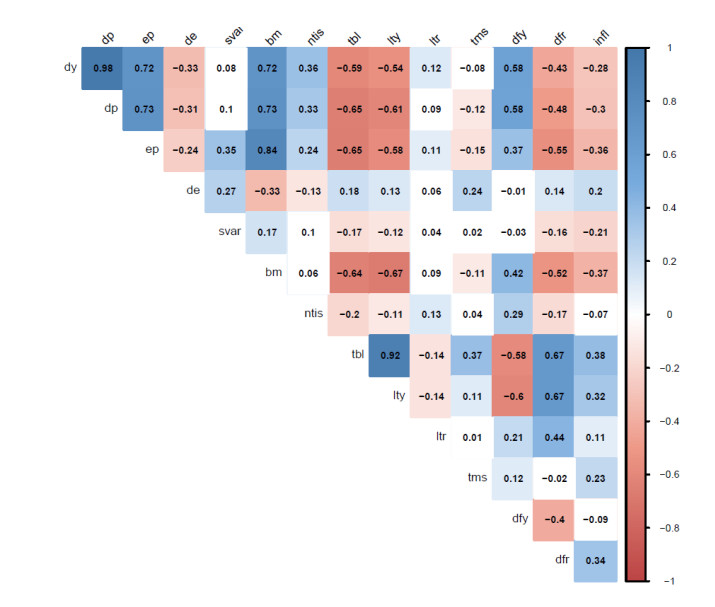
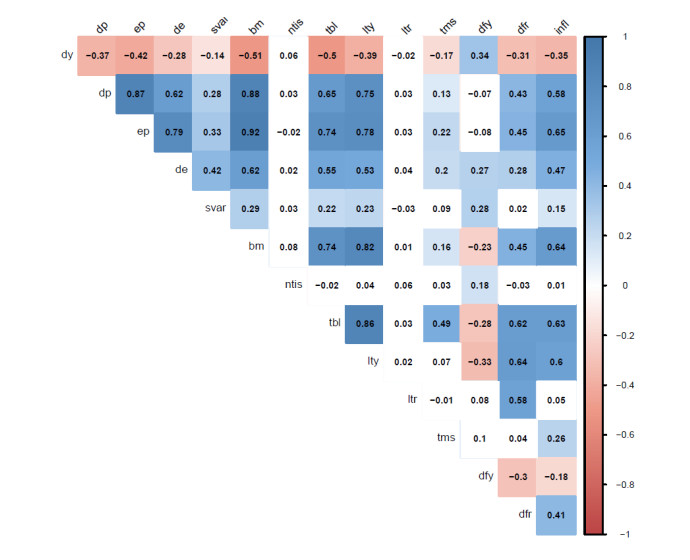
Figures(6) / Tables(6)

Anwen Yin. Equity premium prediction: keep it sophisticatedly simple[J]. Quantitative Finance and Economics, 2021, 5(2): 264-286. doi: 10.3934/QFE.2021012







 DownLoad:
DownLoad: