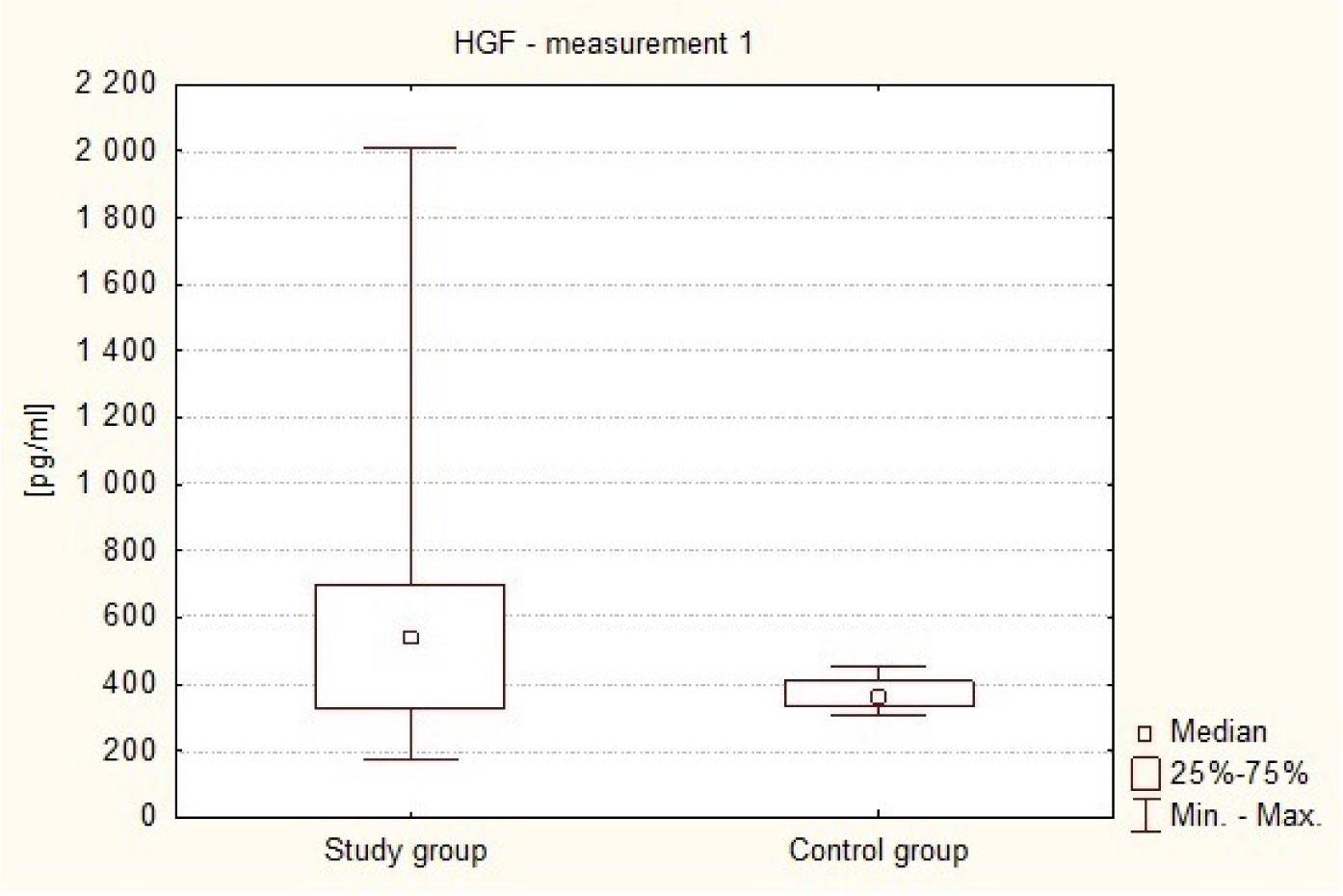
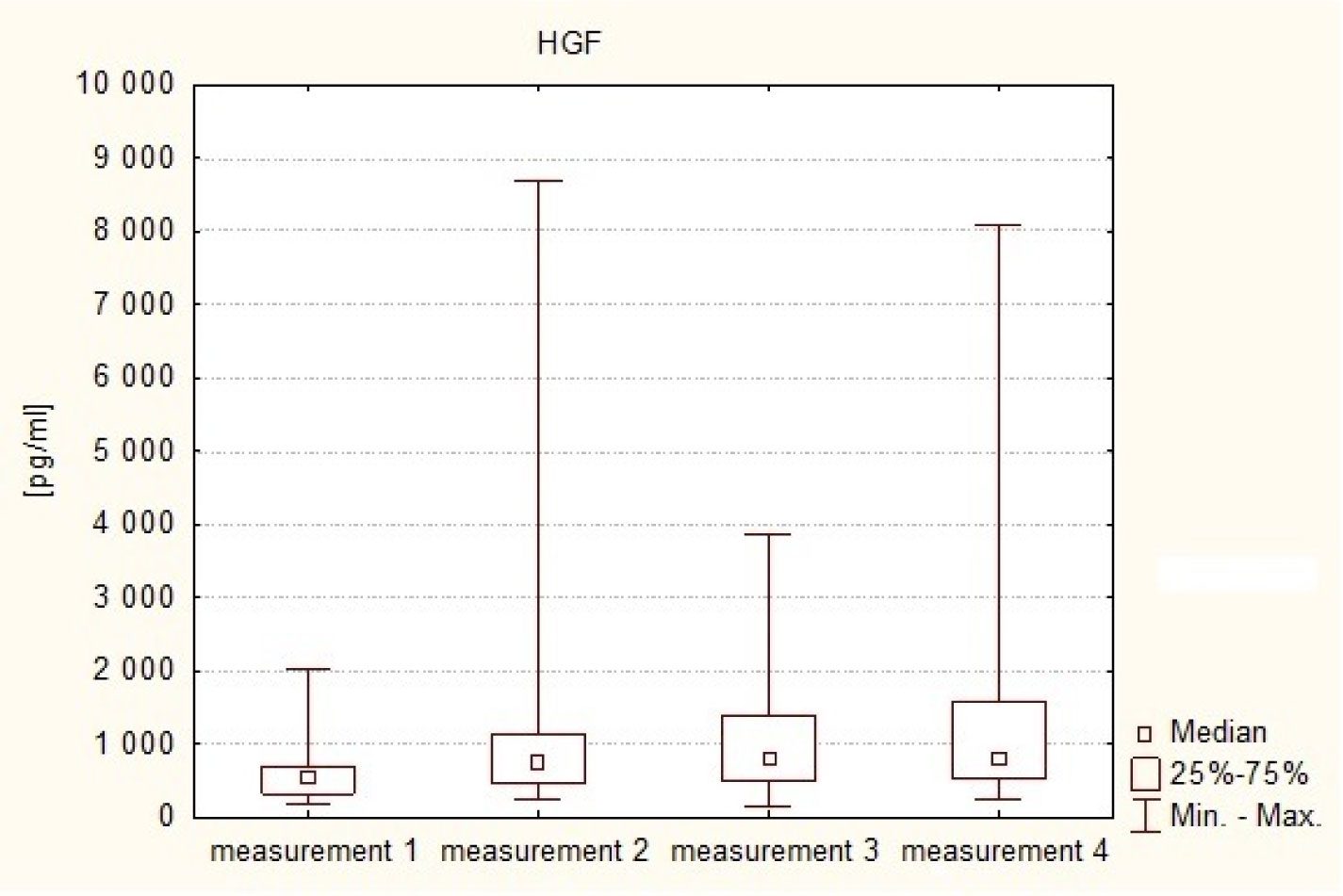
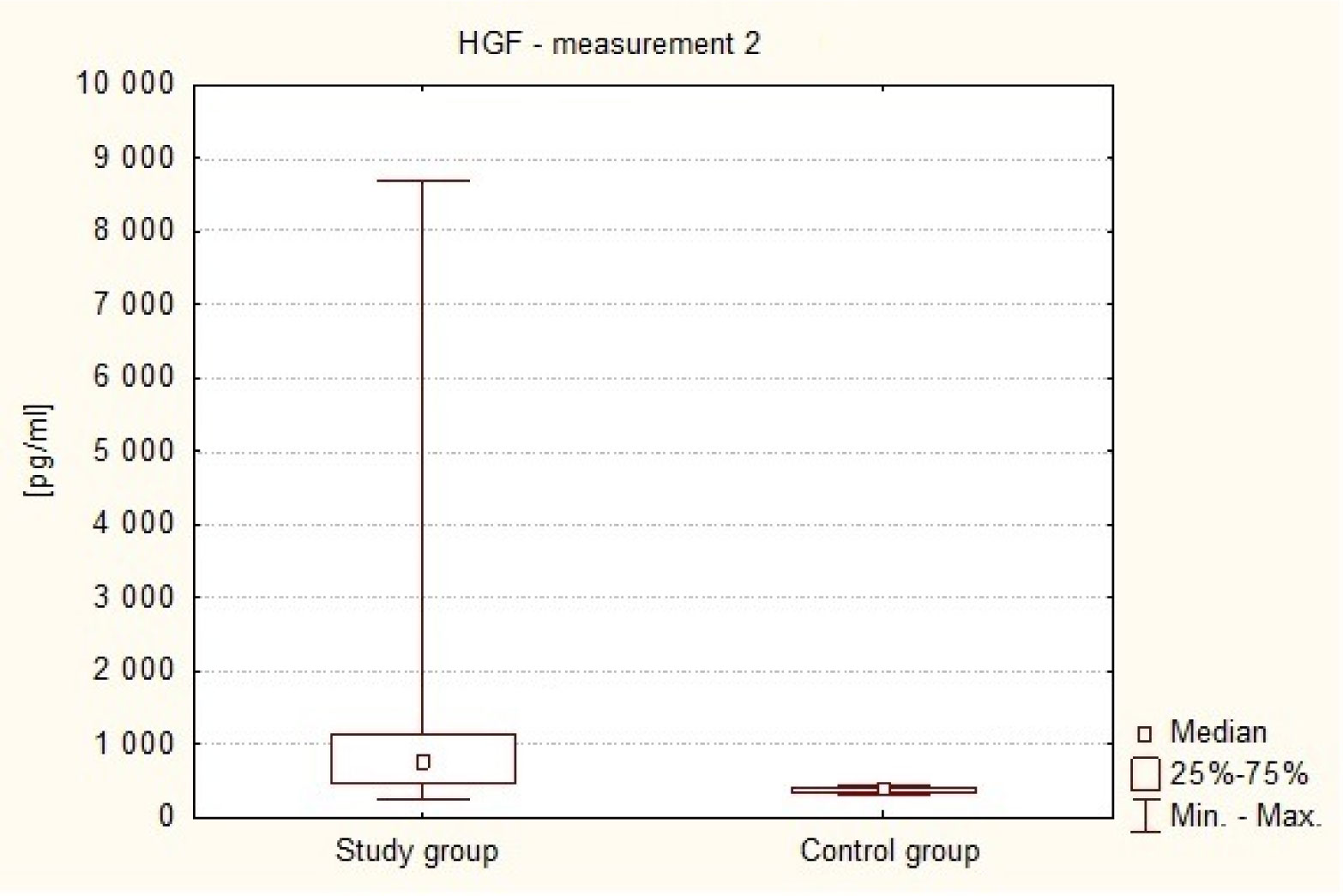
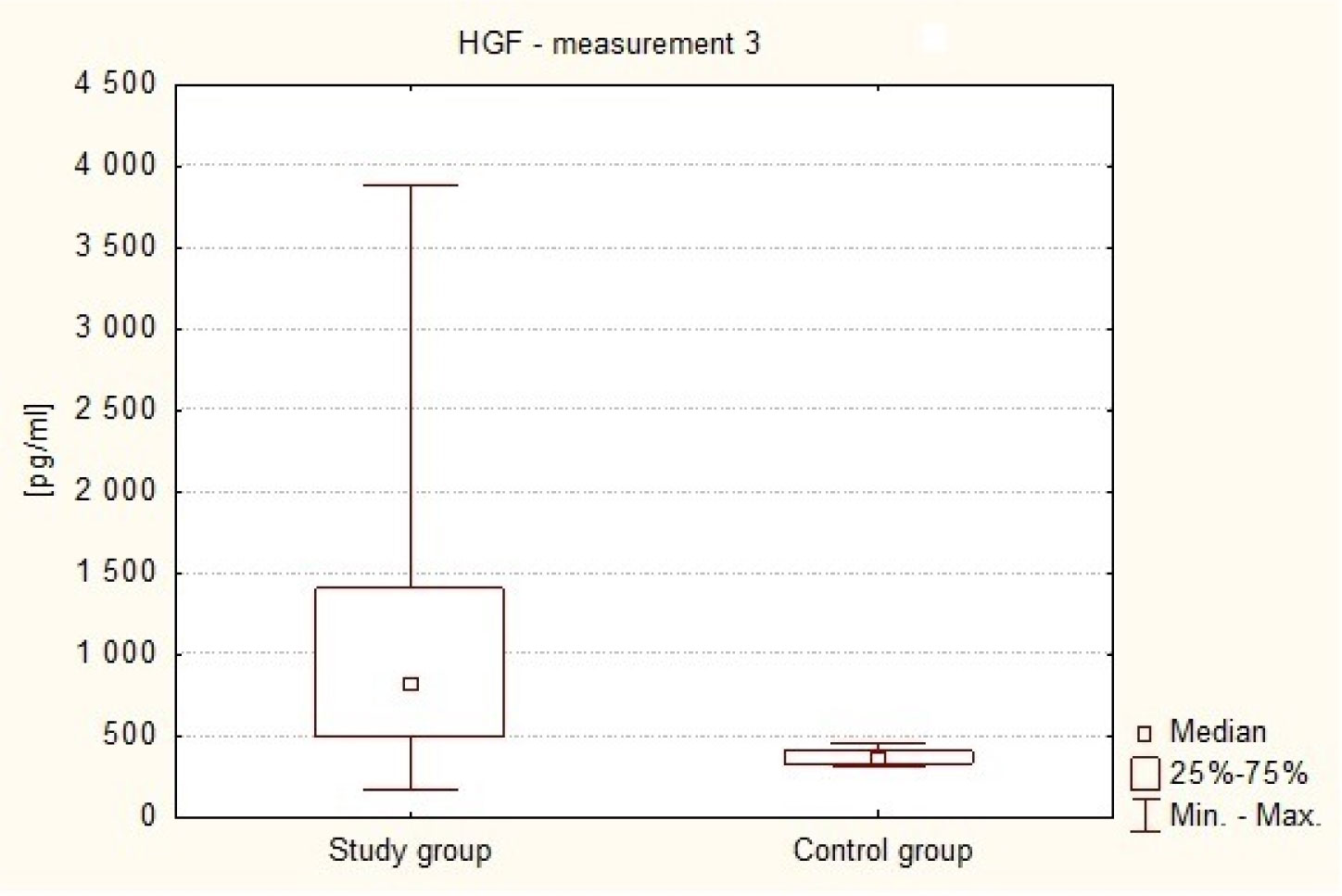
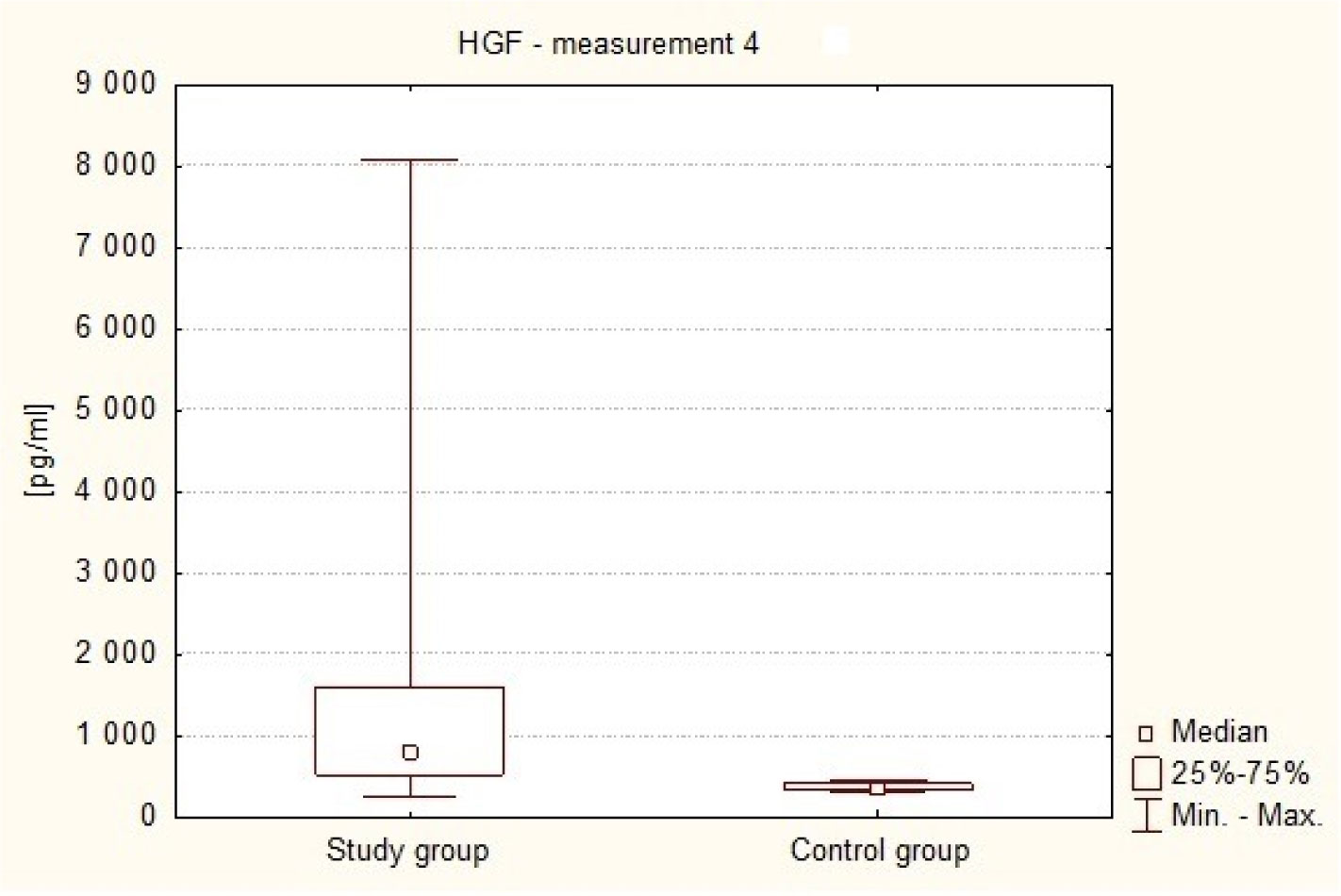
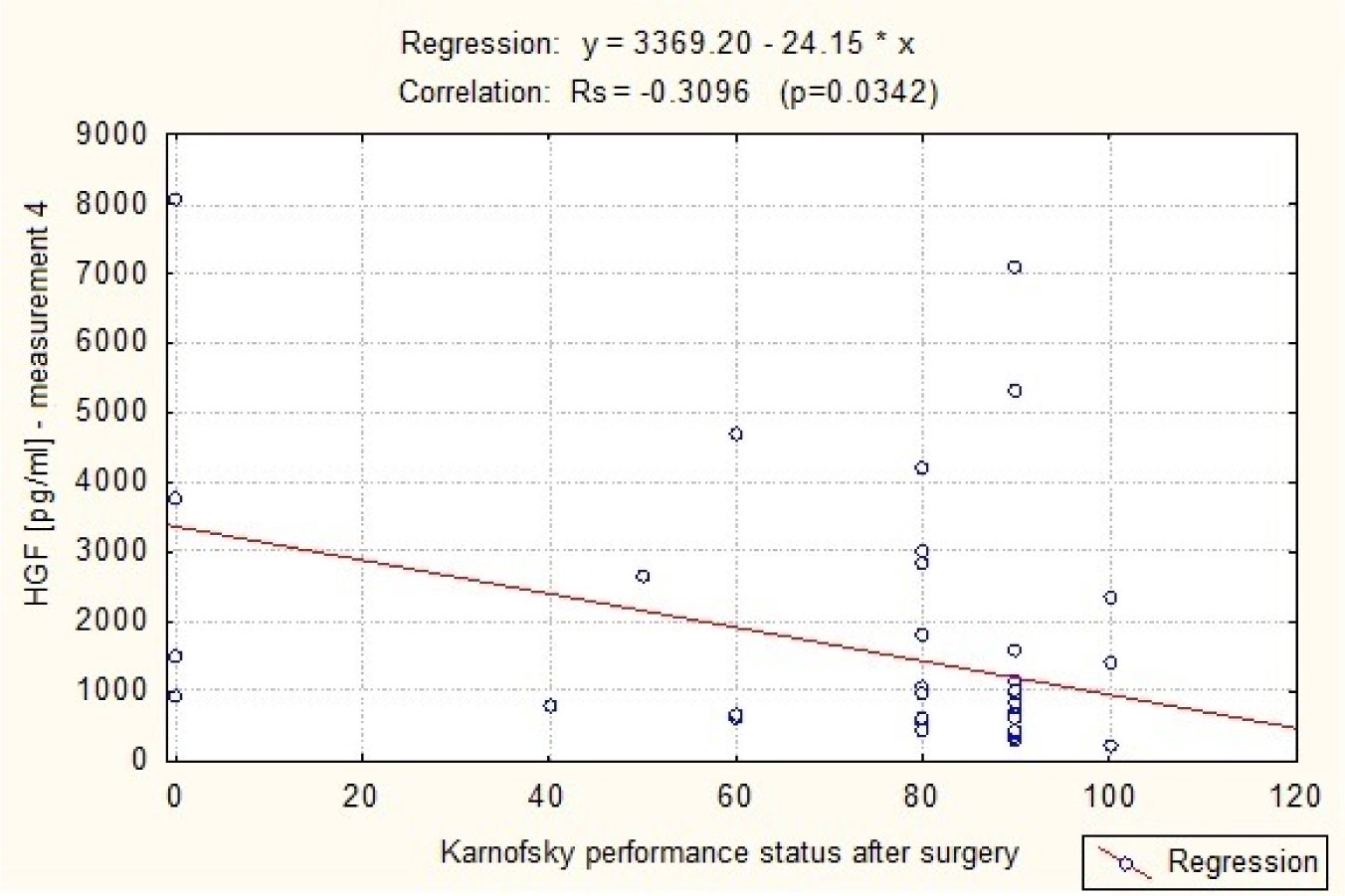
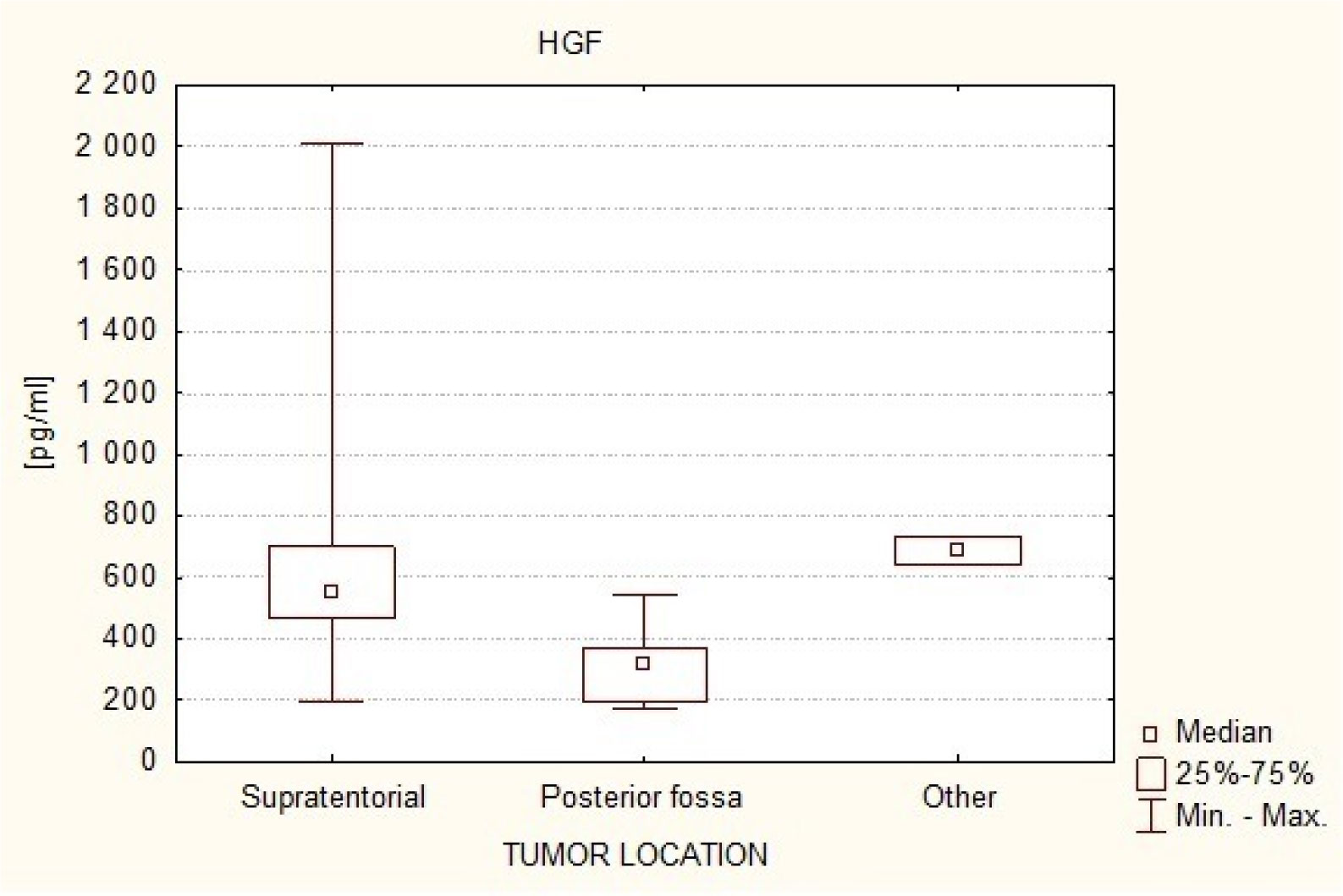
The Hepatocyte Growth Factor is a strong mitogenic factor and seems to play important role in tumor angiogenesis. The purpose of this study was to analyse the plasma concentration of this factor in patients treated surgically because of intracranial tumors. The study included 47 patients, both sexes treated surgically for intracranial tumors and 30 adult volunteers of both sexes, without cancer diagnosis. In study group 4 measurements of plasma HGF were taken: measurement 1: within 24 hours to 1 hour before the operation (preoperative), measurement 2: on the first day after the operation, i.e. after 24 hours, measurement 3: between the third and fifth day following the treatment, i.e. within 72–120 hours, and measurement 4: on the seventh day after the operation, i.e. after 840 hours. In control group only one measurement was taken. The distribution of the analyzed parameters was different from the normal distribution, therefore nonparametric statistics were used. The result values are presented in the form of a median (Me). The analysis revealed that HGR plasma levels in the patients with intracranial tumors in all 4 measurements (Me1 = 543.16 pg/ml, Me2 = 762.59 pg/ml, Me3 = 819.82 pg/ml, Me4 = 804.82 pg/ml) in the perioperative period were elevated in comparison to healthy subjects (Me = 361.04 pg/ml). The association has been shown to exist between postoperative HGF plasma levels and the clinical condition of patients with intracranial tumors (p = 0.0342). Postoperative HGF levels correlated negatively with the patients' postoperative condition. It was also found that in patients with supratentorial tumors HGF plasma levels were higher (Me = 557.74 pg/ml) in comparison to patients with posterior fossa tumors (Me = 325.00 pg/ml). These results suggest increased angiogenic and mitogenic activity in patients with intracranial tumors and its even greater intensity in the postoperative period. Greater angiogenic activity appears to occur in patients with supratentorial tumors.
Citation: Zygmunt Siedlecki, Sebastian Grzyb, Danuta Rość, Maciej Śniegocki. Plasma HGF concentration in patients with brain tumors[J]. AIMS Neuroscience, 2020, 7(2): 107-119. doi: 10.3934/Neuroscience.2020008
The Hepatocyte Growth Factor is a strong mitogenic factor and seems to play important role in tumor angiogenesis. The purpose of this study was to analyse the plasma concentration of this factor in patients treated surgically because of intracranial tumors. The study included 47 patients, both sexes treated surgically for intracranial tumors and 30 adult volunteers of both sexes, without cancer diagnosis. In study group 4 measurements of plasma HGF were taken: measurement 1: within 24 hours to 1 hour before the operation (preoperative), measurement 2: on the first day after the operation, i.e. after 24 hours, measurement 3: between the third and fifth day following the treatment, i.e. within 72–120 hours, and measurement 4: on the seventh day after the operation, i.e. after 840 hours. In control group only one measurement was taken. The distribution of the analyzed parameters was different from the normal distribution, therefore nonparametric statistics were used. The result values are presented in the form of a median (Me). The analysis revealed that HGR plasma levels in the patients with intracranial tumors in all 4 measurements (Me1 = 543.16 pg/ml, Me2 = 762.59 pg/ml, Me3 = 819.82 pg/ml, Me4 = 804.82 pg/ml) in the perioperative period were elevated in comparison to healthy subjects (Me = 361.04 pg/ml). The association has been shown to exist between postoperative HGF plasma levels and the clinical condition of patients with intracranial tumors (p = 0.0342). Postoperative HGF levels correlated negatively with the patients' postoperative condition. It was also found that in patients with supratentorial tumors HGF plasma levels were higher (Me = 557.74 pg/ml) in comparison to patients with posterior fossa tumors (Me = 325.00 pg/ml). These results suggest increased angiogenic and mitogenic activity in patients with intracranial tumors and its even greater intensity in the postoperative period. Greater angiogenic activity appears to occur in patients with supratentorial tumors.

| [1] | Bhargava M, Joseph A, Knesel J, et al. (1992) Scalier Factor and Hepatocyte Growth Factor: Activities, Properties, and Mechanism. Cell Growth Diff 3: 11-20. |
| [2] |
Gospodarowicz D, Cheng J, Lui GM, et al. (1984) Isolation of brain fibroblast growth factor by heparin-Sepharose affinity chromatography: identity with pituitary fibroblast growth factor. Proc Natl Acad Sci U S A 81: 6963-6967. doi: 10.1073/pnas.81.22.6963

|
| [3] |
Gao CF, Vande Woude GF (2005) HGF/SF-Met signaling in tumor progression. Cell Res 15: 49-51. doi: 10.1038/sj.cr.7290264
|
| [4] |
Chandel V, Raj S, Choudhary R, et al. (2020) Role of c-Met/HGF Axis in Altered Cancer Metabolism. Cancer Cell Metabolism: A Potential Target for Cancer Therapy Springer: Singapore, 89-102. doi: 10.1007/978-981-15-1991-8_7
|
| [5] |
Jang J, Ma SH, Ko KP, et al. (2020) Hepatocyte growth factor in blood and gastric cancer risk: A Nested Case–Control study. Cancer Epidemiol Prev Biomarkers 29: 470-476. doi: 10.1158/1055-9965.EPI-19-0436
|
| [6] | Pai P, Kittur SK (2020) Hepatocyte growth factor: A novel tumor marker for breast cancer. |
| [7] | Parizadeh SM, Jafarzadeh-Esfehani R, Fazilat-Panah D, et al. (2019) The potential therapeutic and prognostic impacts of the c-MET/HGF signaling pathway in colorectal cancer. IUBMB life 71: 802-811. |
| [8] |
Folkman J (1995) Clinical applications of research on angiogenesis. N Engl J Med 333: 1757-1763. doi: 10.1056/NEJM199512283332608
|
| [9] |
Lamszus K, Schmidt NO, Jin L, et al. (1998) Scatter factor promotes motility of human glioma and neuromicrovascular endothelial cells. Int J Cancer 75: 19-28. doi: 10.1002/(SICI)1097-0215(19980105)75:1<19::AID-IJC4>3.0.CO;2-4
|
| [10] | Koochekpour S, Jeffers M, Rulong S, et al. (1997) Met and hepatocyte growth factor/scatter factor expression in human gliomas. Cancer Res 57: 5391-5398. |
| [11] |
Rao UN, Sonmez-Alpan E, Michalopoulos GK (1997) Hepatocyte growth factor and c-MET in benign and malignant peripheral nerve sheath tumors. Hum Pathol 28: 1066-1070. doi: 10.1016/S0046-8177(97)90060-5
|
| [12] |
Maemura M, Iino Y, Yokoe T, et al. (1998) Serum concentration of hepatocyte growth factor in patients with metastatic breast cancer. Cancer Lett 126: 215-220. doi: 10.1016/S0304-3835(98)00014-7
|
| [13] |
Moriyama T, Kataoka H, Kawano H, et al. (1998) Comparative analysis of expression of hepatocye growth factor and its receptor, c-met, in gliomas, meningiomas and schwannomas in humans. Cancer Lett 124: 149-155. doi: 10.1016/S0304-3835(97)00469-2
|
| [14] |
Kurumiya Y, Nimura Y, Takeuchi E, et al. (1999) Active form of human hepatocyte growth factor is excreted into bile after hepatobiliary resection. J Hepatol 30: 22-28. doi: 10.1016/S0168-8278(99)80004-X
|
| [15] |
Bussolino F, Di Renzo MF, Ziche M, et al. (1992) Hepatocyte growth factor is a potent angiogenic factor which stimulates endothelial cell motility and growth. J Cell Biol 119: 629-641. doi: 10.1083/jcb.119.3.629
|
| [16] |
Nayeri F, Xu J, Abdiu A, et al. (2006) Autocrine production of biologically active hepatocyte growth factor (HGF) by injured human skin. J Dermatol Sci 43: 49-56. doi: 10.1016/j.jdermsci.2006.03.004
|
| [17] | Criscuolo GR (1993) The genesis of peritumoral vasogenic brain edema and tumor cysts: a hypothetical role for tumor-derived vascular permeability factor. Yale J Biol Med 66: 277-314. |
| [18] |
Burger PC, Kleihues P (1989) Cytologic composition of the untreated glioblastoma with implications for evaluation of needle biopsies. Cancer 63: 2014-2023. doi: 10.1002/1097-0142(19890515)63:10<2014::AID-CNCR2820631025>3.0.CO;2-L
|
| [19] | Brem S, Cotran R, Folkman J (1972) Tumor angiogenesis: a quantitative method for histologic grading. J Natl Cancer Inst 48: 347-356. |
| [20] |
Folkman J (1971) Tumor angiogenesis: therapeutic implications. N Engl J Med 285: 1182-1186. doi: 10.1056/NEJM197108122850711
|
| [21] |
Komaki Y, Kanmura S, Sasaki F, et al. (2019) Hepatocyte growth factor facilitates esophageal mucosal repair and inhibits the submucosal fibrosis in a rat model of esophageal ulcer. Digestion 99: 227-238. doi: 10.1159/000491876
|
| [22] |
Wang X, Tang Y, Shen R, et al. (2017) Hepatocyte growth factor (HGF) optimizes oral traumatic ulcer healing of mice by reducing inflammation. Cytokine 99: 275-280. doi: 10.1016/j.cyto.2017.08.006
|
| [23] |
Miyagi H, Thomasy SM, Russell P, et al. (2018) The role of hepatocyte growth factor in corneal wound healing. Exp Eye Res 166: 49-55. doi: 10.1016/j.exer.2017.10.006
|
| [24] |
Chen SX, Zhang LJ, Gallo RL (2019) Dermal white adipose tissue: a newly recognized layer of skin innate defense. J Invest Dermatol 139: 1002-1009. doi: 10.1016/j.jid.2018.12.031
|
| [25] |
Nicu C, Lai T, Hardman J, et al. (2019) The role of hepatocyte growth factor in human hair follicle–dermal white adipose tissue communication. J Invest Dermatol 139: S314-S314. doi: 10.1016/j.jid.2019.07.580
|
Figures(7) / Tables(1)

Zygmunt Siedlecki, Sebastian Grzyb, Danuta Rość, Maciej Śniegocki. Plasma HGF concentration in patients with brain tumors[J]. AIMS Neuroscience, 2020, 7(2): 107-119. doi: 10.3934/Neuroscience.2020008







 DownLoad:
DownLoad: