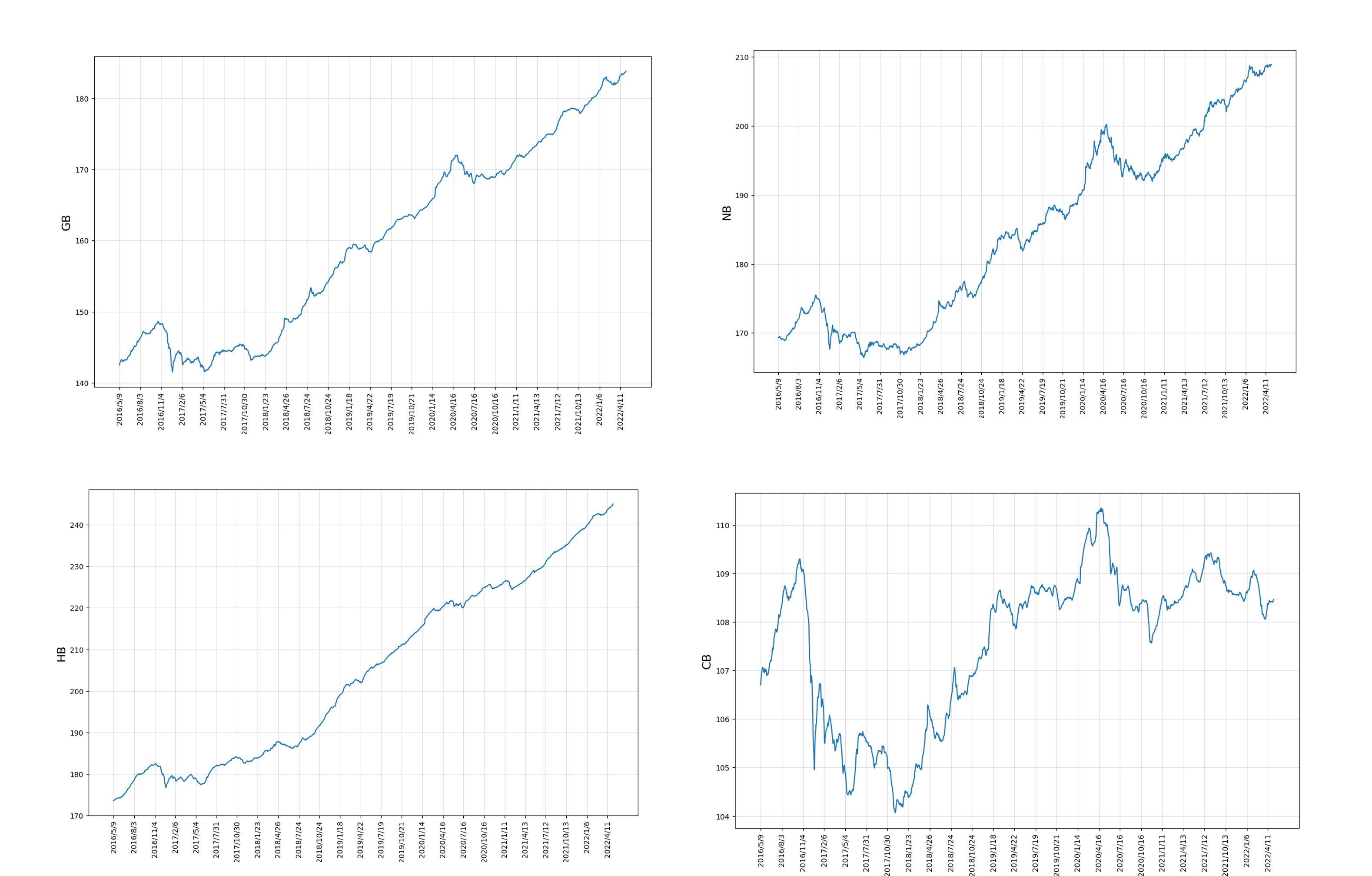
With the aim of effectively preventing and controlling systemic risk, by stimulating the advancement of the green bond market, it is significant and imperative to help investors and policymakers adopt more effective measures, which will ensure them to maximize profit. We construct VAR, DCC-GARCH and Copula-CoVaR models, and study the spillover effect between the green bond market and traditional bond market from the three perspectives of mean spillover, volatility spillover and extreme risk spillover using the data on daily closing prices of green bond market and traditional bond market indices. The research findings of this paper are as follows: (1) There are three spillover effects of mean value, volatility and extreme risk among the green bond market, corporate bond market, enterprise bond market and conventional bond market. (2) From the perspective of mean spillover between markets, only the mean spillover between the conventional bond market and the green bond market is bidirectional, and there is the profoundest impact of spillover from the green bond market to the conventional bond market. (3) As far as the volatility spillover between markets is concerned, the volatility spillover between the three traditional bond market and the green bond markets are all positive. The volatility spillover between the conventional bond market and the green bond market is the largest, which is particularly obvious in the first half of 2018 and the first half of 2020. (4) In terms of inter-market extreme risk spillover, the risk spillover between the green bond market and the traditional bond market is positive. The green bond market contributes more to the risk spillover of the enterprise bond market, and it has a time-varying risk spillover effect on the traditional bond market.
Citation: Gang Peng, Jie Ding, Zehang Zhou, Li Zhu. Measurement of spillover effect between green bond market and traditional bond market in China[J]. Green Finance, 2023, 5(4): 538-561. doi: 10.3934/GF.2023021
With the aim of effectively preventing and controlling systemic risk, by stimulating the advancement of the green bond market, it is significant and imperative to help investors and policymakers adopt more effective measures, which will ensure them to maximize profit. We construct VAR, DCC-GARCH and Copula-CoVaR models, and study the spillover effect between the green bond market and traditional bond market from the three perspectives of mean spillover, volatility spillover and extreme risk spillover using the data on daily closing prices of green bond market and traditional bond market indices. The research findings of this paper are as follows: (1) There are three spillover effects of mean value, volatility and extreme risk among the green bond market, corporate bond market, enterprise bond market and conventional bond market. (2) From the perspective of mean spillover between markets, only the mean spillover between the conventional bond market and the green bond market is bidirectional, and there is the profoundest impact of spillover from the green bond market to the conventional bond market. (3) As far as the volatility spillover between markets is concerned, the volatility spillover between the three traditional bond market and the green bond markets are all positive. The volatility spillover between the conventional bond market and the green bond market is the largest, which is particularly obvious in the first half of 2018 and the first half of 2020. (4) In terms of inter-market extreme risk spillover, the risk spillover between the green bond market and the traditional bond market is positive. The green bond market contributes more to the risk spillover of the enterprise bond market, and it has a time-varying risk spillover effect on the traditional bond market.

| [1] | Bai J (2021) A Study of Systemic Risk Spillover Effects of Commercial Banks Based on GARCH-DCC-Copula-CoVaR Approach. Huabei Financ, 45–58. |
| [2] |
Bhatnagar M, Taneja S, Özen E (2022) A wave of green start-ups in India—The study of green finance as a support system for sustainable entrepreneurship. Green Financ 4: 253–273. https://doi.org/10.3934/GF.2022012 doi: 10.3934/GF.2022012

|
| [3] | Chen F, Zhang Y (2023) An Empirical Research on the Financial and Environmental Results of Corporate Green Bond Issuance. J Guangdong Univ Financ Econ 38: 38–53+81. |
| [4] | Chen W, Huang L, Weng J (2021) Exploring the Pricing Advantages of Green Bond Issuance and Its Influencing Factors. J Reg Financ Res, 25–32. |
| [5] | Chen X, Zhang M (2022) China's Green Bond Market: Characteristics, Facts, Endogenous Dynamics, and Existing Challenges. Int Econ Rev, 104–133+107. |
| [6] | Colombage S, Nanayakkara K (2020) Impact of credit quality on credit spread of Green Bonds: a global evidence. Rev Dev Financ 10: 31–42. |
| [7] | Dou R, Zhang W (2019) The Effect of Green Factor on Bond Yield Spread——Based on PSM. J Shanghai Lixin Univ Account Financ, 47–57. |
| [8] |
Ezuma REMR, Matthew NK, Ezuma R, et al. (2022) The perspectives of stakeholders on the effectiveness of green financing schemes in Malaysia. Green Financ 4: 450–473. https://doi.org/10.3934/GF.2022022 doi: 10.3934/GF.2022022
|
| [9] | Gao X, Ji W (2018) Characteristics of Issuers and Credit Spread of Green Bond Issuance. Financ Econ, 26–36. |
| [10] | Gao Y, Li C (2021) Research on Risk Spillover Effect between Green Bond Market and Financial Market in China. Financ Forum 26: 59–69. |
| [11] | Gianfrate G (2019) Climate risks and the practice of corporate valuation. |
| [12] |
Girardi G, Ergün AT (2013) Systemic risk measurement: Multivariate GARCH estimation of CoVaR. J Bank Financ 37: 3169–3180. https://doi.org/10.1016/j.jbankfin.2013.02.027 doi: 10.1016/j.jbankfin.2013.02.027
|
| [13] | He J (2017) An empirical study of spillover effects between Main Board, GEM and NSE. China Manage Inf 20: 110–112. |
| [14] | Hu Q, Ma L (2011) China's stock market and bond market Analysis of volatility spillover effect. J Financ Res, 198–206. |
| [15] | Huang Z (2021) The Impact of International Oil Price on the Stock Prices of Domestic Oil Related Industries—AnEmpiricalAnalysis Based on DCC-Copula-CoVaR. |
| [16] |
Huynh TLD (2021) Does bitcoin react to Trump's tweets? J Behav Exp Financ 31: 100546. https://doi.org/10.1016/j.jbef.2021.100546 doi: 10.1016/j.jbef.2021.100546
|
| [17] | Jiang F, Fan L (2020) Green Premium or Green Discount?——A study based on China's green bond credit spreads. Modernization Manage 40: 11–15. |
| [18] |
Kanamura T (2020) Are green bonds environmentally friendly and good performing assets? Energ Econ 88: 104767. https://doi.org/10.1016/j.eneco.2020.104767 doi: 10.1016/j.eneco.2020.104767
|
| [19] |
Kielmann J, Manner H, Min A (2022) Stock market returns and oil price shocks: A CoVaR analysis based on dynamic vine copula models. Empir Econ 62: 1543–1574. https://doi.org/10.1007/s00181-021-02073-9 doi: 10.1007/s00181-021-02073-9
|
| [20] |
Kirithiga S, Naresh G, Thiyagarajan S (2017) Measuring volatility in the Indian commodity futures. Int J Bonds Deriv 3: 253–274. https://doi.org/10.1504/IJBD.2017.088545 doi: 10.1504/IJBD.2017.088545
|
| [21] | Li Y, Wang Y, Deng W (2018) Investor Sentiment, Heterogeneity and the Credit Spread of Chinese Corporate Bonds. Financ Trade Res 29: 100–110. |
| [22] | Li Z, Fan L (2011) House Price Volatility, the Selection of Monetary Policy Instruments and the Stability of Macro-economy: Theory and Empirical Evidence. Modern Econ Sci 33: 13–20+122. |
| [23] |
Lin T, Du M, Ren S, et al. (2022) How do green bonds affect green technology innovation? Firm evidence from China. Green Financ 4: 492–511. https://doi.org/10.3934/GF.2022024 doi: 10.3934/GF.2022024
|
| [24] | Liu X, Wang S (2018) Research on mean spillover effect of Sino US soybean futures——An Empirical Analysis Based on MSVAR Model. Price: Theory Practice, 99–102. |
| [25] |
MacAskill S, Roca E, Liu B, et al. (2021) Is there a green premium in the green bond market? Systematic literature review revealing premium determinants. J Clean Prod 280: 124491. https://doi.org/10.1016/j.jclepro.2020.124491 doi: 10.1016/j.jclepro.2020.124491
|
| [26] |
Mensi W, Shafiullah M, Vo XV, et al. (2022) Spillovers and connectedness between green bond and stock markets in bearish and bullish market scenarios. Financ Res Lett 49: 103120. https://doi.org/10.1016/j.frl.2022.103120 doi: 10.1016/j.frl.2022.103120
|
| [27] |
Naeem MA, Conlon T, Cotter J (2022) Green bonds and other assets: Evidence from extreme risk transmission. J Environ Manage 305: 114358. https://doi.org/10.1016/j.jenvman.2021.114358 doi: 10.1016/j.jenvman.2021.114358
|
| [28] |
Partridge C, Medda FR (2020) Green bond pricing: The search for greenium. J Altern Invest 23: 49–56. https://doi.org/10.3905/jai.2020.1.096 doi: 10.3905/jai.2020.1.096
|
| [29] |
Pham L, Huynh TLD (2020) How does investor attention influence the green bond market? Financ Res Lett 35: 101533. https://doi.org/10.1016/j.frl.2020.101533 doi: 10.1016/j.frl.2020.101533
|
| [30] | Qi H, Liu S (2021) Is there a Greenium in the Bond market of China? Account Res, 131–148. |
| [31] | Qin S, Wang X, Luo Y, et al. (2019) Spillover effects between the stock market and the green bond market in low-carbon industries—an analysis based on data before and after the emergence of labeled green bonds. Wuhan Financ, 67–72. |
| [32] |
Reboredo JC (2018) Green bond and financial markets: Co-movement, diversification and price spillover effects. Energ Econ 74: 38–50. https://doi.org/10.1016/j.eneco.2018.05.030 doi: 10.1016/j.eneco.2018.05.030
|
| [33] |
Reboredo JC, Ugolini A, Chen Y (2019) Interdependence between renewable-energy and low-carbon stock prices. Energies 12: 4461. https://doi.org/10.3390/en12234461 doi: 10.3390/en12234461
|
| [34] |
Su T, Zhang ZJ, Lin B (2022) Green bonds and conventional financial markets in China: A tale of three transmission modes. Energ Econ 113: 106200. https://doi.org/10.1016/j.eneco.2022.106200 doi: 10.1016/j.eneco.2022.106200
|
| [35] |
Tsagkanos A, Sharma A, Ghosh B (2022) Green Bonds and Commodities: A new asymmetric sustainable relationship. Sustainability 14: 6852. https://doi.org/10.3390/su14116852 doi: 10.3390/su14116852
|
| [36] |
Tsoukala AK, Tsiotas G (2021) Assessing green bond risk: an empirical investigation. Green Financ 3: 222–252. https://doi.org/10.3934/GF.2021012 doi: 10.3934/GF.2021012
|
| [37] | Wairagu GP (2011) The relationship between financial innovation and profitability of Commercial banks in Kenya. |
| [38] | Wang Y (2021) Analysis of the Linkage Effect and Influencing Factors between the Green Bond Market and the Traditional Bond Market. |
| [39] | Wang Y, Tian Y (2023) Research on the Impact of the Issuance of Green Bonds on the Business Performance of Listed Companies. China J Commerce, 109–113. |
| [40] | Wang Y, Xu N (2016) The Development of Chinese Green Bonds and A Comparative Study of Chinese and Foreign Standards. Financ Forum 21: 29–38. |
| [41] | Wang Z, Zeng G (2016) International Green Bond Market: Current Situation, Experience and Enlightenment. Financ Forum 21: 39–45. |
| [42] |
Yavas BF, Dedi L (2016) An investigation of return and volatility linkages among equity markets: A study of selected European and emerging countries. Res Int Bus Financ 37: 583–596. https://doi.org/10.1016/j.ribaf.2016.01.025 doi: 10.1016/j.ribaf.2016.01.025
|
| [43] |
Zerbib OD (2019) The effect of pro-environmental preferences on bond prices: Evidence from green bonds. J Bank Financ 98: 39–60. https://doi.org/10.1016/j.jbankfin.2018.10.012 doi: 10.1016/j.jbankfin.2018.10.012
|
| [44] |
Zhang Y, Wang Z, Tang Z, et al. (2020) Water Phase, Room Temperature, Ligand‐Free Suzuki–Miyaura Cross‐Coupling: A Green Gateway to Aryl Ketones by C–N Bond Cleavage. Eur Org Chem 2020: 1620–1628. https://doi.org/10.1002/ejoc.201901730 doi: 10.1002/ejoc.201901730
|
| [45] |
Zhong M, Darrat AF, Otero R (2004) Price discovery and volatility spillovers in index futures markets: Some evidence from Mexico. J Bank Financ 28: 3037–3054. https://doi.org/10.1016/j.jbankfin.2004.05.001 doi: 10.1016/j.jbankfin.2004.05.001
|
| [46] | Zhou S, Zhou J (2006) A Study of Volatility Spillovers in Domestic and International Crude Oil Markets. J China Univ Petroleum (Edition of Social Sciences), 8–11. |
| [47] |
Zhu M (2013) Return distribution predictability and its implications for portfolio selection. Int Rev Econ Financ 27: 209–223. https://doi.org/10.1016/j.iref.2012.10.002 doi: 10.1016/j.iref.2012.10.002
|







Figures(8) / Tables(14)

Gang Peng, Jie Ding, Zehang Zhou, Li Zhu. Measurement of spillover effect between green bond market and traditional bond market in China[J]. Green Finance, 2023, 5(4): 538-561. doi: 10.3934/GF.2023021







 DownLoad:
DownLoad: