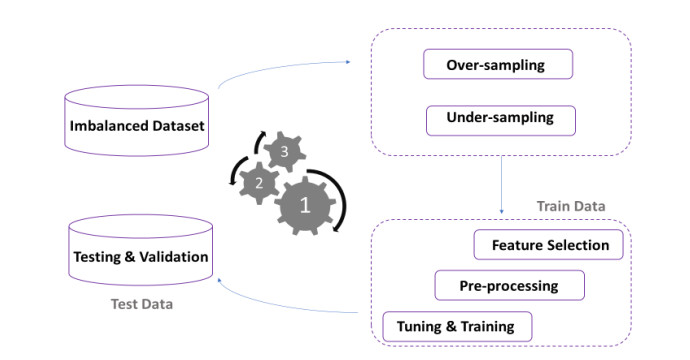
In the realm of machine learning, where data-driven insights guide decision-making, addressing the challenges posed by class imbalance in datasets has emerged as a crucial concern. The effectiveness of classification algorithms hinges not only on their intrinsic capabilities but also on their adaptability to uneven class distributions, a common issue encountered across diverse domains. This study delves into the intricate interplay between varying class imbalance levels and the performance of ten distinct classification models, unravelling the critical impact of this imbalance on the landscape of predictive analytics. Results showed that random forest (RF) and decision tree (DT) models outperformed others, exhibiting robustness to class imbalance. Logistic regression (LR), stochastic gradient descent classifier (SGDC) and naïve Bayes (NB) models struggled with imbalanced datasets. Adaptive boosting (ADA), gradient boosting (GB), extreme gradient boosting (XGB), light gradient boosting machine (LGBM), and k-nearest neighbour (kNN) models improved with balanced data. Adaptive synthetic sampling (ADASYN) yielded more reliable predictions than the under-sampling (UNDER) technique. This study provides insights for practitioners and researchers dealing with imbalanced datasets, guiding model selection and data balancing techniques. RF and DT models demonstrate superior performance, while LR, SGDC and NB models have limitations. By leveraging the strengths of RF and DT models and addressing class imbalance, classification performance in imbalanced datasets can be enhanced. This study enriches credit risk modelling literature by revealing how class imbalance impacts default probability estimation. The research deepens our understanding of class imbalance's critical role in predictive analytics. Serving as a roadmap for practitioners and researchers dealing with imbalanced data, the findings guide model selection and data balancing strategies, enhancing classification performance despite class imbalance.
Citation: Lindani Dube, Tanja Verster. Enhancing classification performance in imbalanced datasets: A comparative analysis of machine learning models[J]. Data Science in Finance and Economics, 2023, 3(4): 354-379. doi: 10.3934/DSFE.2023021
In the realm of machine learning, where data-driven insights guide decision-making, addressing the challenges posed by class imbalance in datasets has emerged as a crucial concern. The effectiveness of classification algorithms hinges not only on their intrinsic capabilities but also on their adaptability to uneven class distributions, a common issue encountered across diverse domains. This study delves into the intricate interplay between varying class imbalance levels and the performance of ten distinct classification models, unravelling the critical impact of this imbalance on the landscape of predictive analytics. Results showed that random forest (RF) and decision tree (DT) models outperformed others, exhibiting robustness to class imbalance. Logistic regression (LR), stochastic gradient descent classifier (SGDC) and naïve Bayes (NB) models struggled with imbalanced datasets. Adaptive boosting (ADA), gradient boosting (GB), extreme gradient boosting (XGB), light gradient boosting machine (LGBM), and k-nearest neighbour (kNN) models improved with balanced data. Adaptive synthetic sampling (ADASYN) yielded more reliable predictions than the under-sampling (UNDER) technique. This study provides insights for practitioners and researchers dealing with imbalanced datasets, guiding model selection and data balancing techniques. RF and DT models demonstrate superior performance, while LR, SGDC and NB models have limitations. By leveraging the strengths of RF and DT models and addressing class imbalance, classification performance in imbalanced datasets can be enhanced. This study enriches credit risk modelling literature by revealing how class imbalance impacts default probability estimation. The research deepens our understanding of class imbalance's critical role in predictive analytics. Serving as a roadmap for practitioners and researchers dealing with imbalanced data, the findings guide model selection and data balancing strategies, enhancing classification performance despite class imbalance.

| [1] |
Alija S, Beqiri E, Gaafar AS, et al. (2023) Predicting students performance using supervised machine learning based on imbalanced dataset and wrapper feature selection. Informatica 47. https://doi.org/10.31449/inf.v47i1.4519 doi: 10.31449/inf.v47i1.4519

|
| [2] |
Aljedaani W, Rustam F, Mkaouer MW, et al. (2022) Sentiment analysis on twitter data integrating textblob and deep learning models: The case of us airline industry. Knowl-Based Syst 255: 109780. https://doi.org/10.1016/j.knosys.2022.109780 doi: 10.1016/j.knosys.2022.109780
|
| [3] | Anguita D, Ghelardoni L, Ghio A, et al. (2012) The'k'in k-fold cross validation. in 'ESANN', 441–446. |
| [4] |
Bentéjac C, Csörgő A, Martínez-Muñoz G (2021) A comparative analysis of gradient boosting algorithms. Artif Intell Rev 54: 1937–1967. https://doi.org/10.1007/s10462-020-09896-5 doi: 10.1007/s10462-020-09896-5
|
| [5] |
Booth A, Gerding E, McGroarty F (2015) Performance-weighted ensembles of random forests for predicting price impact. Quant Financ 15: 1823–1835. https://doi.org/10.1080/14697688.2014.983539 doi: 10.1080/14697688.2014.983539
|
| [6] | Breeden J (2021) A survey of machine learning in credit risk. J Credit Risk 17. https://ssrn.com/abstract = 3946261 |
| [7] |
Breiman L (2001) Random forests. Mach learn 45: 5–32. https://doi.org/10.1023/A:1010933404324 doi: 10.1023/A:1010933404324
|
| [8] | Breiman L, Friedman J, Olshen R, et al. (1984) Classification and regression trees (wadsworth, belmont, ca). 13: 978–0412048418. |
| [9] |
Calderoni L, Ferrara M, Franco A, et al. (2015) Indoor localization in a hospital environment using random forest classifiers. Expert Syst Appl 42: 125–134. https://doi.org/10.1016/j.eswa.2014.07.042 doi: 10.1016/j.eswa.2014.07.042
|
| [10] | Cawley GC, Talbot NL (2010) On over-fitting in model selection and subsequent selection bias in performance evaluation. J Mach Learn Res 11: 2079–2107. |
| [11] | Chen T, Guestrin C (2016) Xgboost: A scalable tree boosting system, in Proceedings of the 22nd acm sigkdd international conference on knowledge discovery and data mining, 785–794. |
| [12] |
Chicco D, Jurman G (2020) The advantages of the matthews correlation coefficient (mcc) over f1 score and accuracy in binary classification evaluation. BMC Genomics 21: 1–13. https://doi.org/10.1186/s12864-019-6413-7 doi: 10.1186/s12864-019-6413-7
|
| [13] |
Das S, Datta S, Chaudhuri BB (2018) Handling data irregularities in classification: Foundations, trends, and future challenges. Pattern Recogn 81: 674–693. https://doi.org/10.1016/j.patcog.2018.03.008 doi: 10.1016/j.patcog.2018.03.008
|
| [14] | De Campos LM, Cano A, Castellano JG, et al. (2011) Bayesian networks classifiers for gene-expression data, in 2011 11th International Conference on Intelligent Systems Design and Applications, IEEE, 1200–1206. https://doi.org/10.1109/ISDA.2011.6121822 |
| [15] |
Deng M, Chen J, Huang J, et al. (2018) Agricultural drought risk evaluation based on an optimized comprehensive index system. Sustainability 10: 3465. https://doi.org/10.3390/su10103465 doi: 10.3390/su10103465
|
| [16] | Dhieb N, Ghazzai H, Besbes H, et al. (2019) Extreme gradient boosting machine learning algorithm for safe auto insurance operations, in 2019 IEEE international conference on vehicular electronics and safety (ICVES), IEEE, 1–5. https://doi.org/10.1109/ICVES.2019.8906396 |
| [17] |
Dorogush AV, Ershov V, Gulin A (2018) Catboost: gradient boosting with categorical features support. arXiv preprint. https://doi.org/10.48550/arXiv.1810.11363 doi: 10.48550/arXiv.1810.11363
|
| [18] | Fayyad UM, Irani KB (1992) The attribute selection problem in decision tree generation, in 'AAAI', 104–110. |
| [19] | Fernando KRM, Tsokos CP (2021) Dynamically weighted balanced loss: class imbalanced learning and confidence calibration of deep neural networks. IEEE T Neur Net Learn Syst 33: 2940–2951. |
| [20] | Granström D, Abrahamsson J (2019) Loan default prediction using supervised machine learning algorithms. |
| [21] | Han J, Kamber M, Pei J (2012) Data mining concepts and techniques third edition, University of Illinois at Urbana-Champaign Micheline Kamber Jian Pei Simon Fraser University. |
| [22] | Ho TK (1995) Random decision forests, in Proceedings of 3rd international conference on document analysis and recognition, IEEE, 1: 278–282. |
| [23] | Kaggle (2023) Give me some credit. Available from: https://www.kaggle.com/competitions/GiveMeSomeCredit/dataselect = cs-training.csv. Accessed: 2023-02-05. |
| [24] | Ke G, Meng Q, Finley T, et al. (2017) Lightgbm: A highly efficient gradient boosting decision tree. Adv Neural Inf Process Syst 30. |
| [25] | Kelleher JD, Mac Namee B, D'arcy A (2020) Fundamentals of machine learning for predictive data analytics: algorithms, worked examples, and case studies, MIT press. |
| [26] |
Khemakhem S, Boujelbene Y (2018) Predicting credit risk on the basis of financial and non-financial variables and data mining. Rev Account Financ 17: 316–340. https://doi.org/10.1108/RAF-07-2017-0143 doi: 10.1108/RAF-07-2017-0143
|
| [27] |
Laradji IH, Alshayeb M, Ghouti L (2015) Software defect prediction using ensemble learning on selected features. Inform Software Tech 58: 388–402. https://doi.org/10.1016/j.infsof.2014.07.005 doi: 10.1016/j.infsof.2014.07.005
|
| [28] |
Leo M, Sharma S, Maddulety K (2019) Machine learning in banking risk management: A literature review. Risks 7: 29. https://doi.org/10.3390/risks7010029 doi: 10.3390/risks7010029
|
| [29] |
Li K, Xu H, Liu X (2022) Analysis and visualization of accidents severity based on lightgbm-tpe. Chaos, Solitons Fract 157: 111987. https://doi.org/10.1016/j.chaos.2022.111987 doi: 10.1016/j.chaos.2022.111987
|
| [30] |
Liu L, Li P, Chu M, et al. (2021) Stochastic gradient support vector machine with local structural information for pattern recognition. Int J Mach Learn Cybe 12: 2237–2254. https://doi.org/10.1007/s13042-021-01303-x doi: 10.1007/s13042-021-01303-x
|
| [31] | Liu W, Chawla S, Cieslak DA, et al. (2010) A robust decision tree algorithm for imbalanced data sets, inProceedings of the 2010 SIAM International Conference on Data Mining, SIAM, 766–777. |
| [32] | Lokeswari N, Amaravathi K (2018) Comparative study of classification algorithms in sentiment analysis. Int Res J Sci Eng Technol 4: 31–39. |
| [33] | Mitchell TM, Mitchell TM (1997) Machine learning, 1: McGraw-hill New York. |
| [34] |
Ogunleye A, Wang QG (2019) Xgboost model for chronic kidney disease diagnosis. IEEE/ACM T Comput Bi 17: 2131–2140. https://doi.org/10.1109/TCBB.2019.2911071 doi: 10.1109/TCBB.2019.2911071
|
| [35] |
Okey OD, Maidin SS, Adasme P, et al. (2022) Boostedenml: Efficient technique for detecting cyberattacks in iot systems using boosted ensemble machine learning. Sensors 22: 7409. https://doi.org/10.3390/s22197409 doi: 10.3390/s22197409
|
| [36] | Padmaja TM, Dhulipalla N, Bapi RS, et al. (2007) Unbalanced data classification using extreme outlier elimination and sampling techniques for fraud detection. in 15th International Conference on Advanced Computing and Communications (ADCOM 2007), IEEE, 511–516. https://doi.org/10.1109/ADCOM.2007.74 |
| [37] | Patro S, Sahu KK (2015) Normalization: A preprocessing stage. arXiv preprint arXiv: 1503.06462. https://doi.org/10.48550/arXiv.1503.06462 |
| [38] | Rubin DB (1976) Inference and missing data. Biometrika 63: 581–592. |
| [39] |
Schafer JL, Graham JW (2002) Missing data: our view of the state of the art. Psychol Methods 7: 147. https://doi.org/10.1037/1082-989X.7.2.147 doi: 10.1037/1082-989X.7.2.147
|
| [40] | Singhal Y, Jain A, Batra S, et al. (2018) Review of bagging and boosting classification performance on unbalanced binary classification, in 2018 IEEE 8th International Advance Computing Conference (IACC), IEEE, 338–343. https://doi.org/10.1109/IADCC.2018.8692138 |
| [41] |
Stephens D, Diesing M (2014) A comparison of supervised classification methods for the prediction of substrate type using multibeam acoustic and legacy grain-size data. PloS One 9: e93950. https://doi.org/10.1371/journal.pone.0093950 doi: 10.1371/journal.pone.0093950
|
| [42] |
Sun J, Lang J, Fujita H, et al. (2018) Imbalanced enterprise credit evaluation with dte-sbd: Decision tree ensemble based on smote and bagging with differentiated sampling rates. Inform Sci 425: 76–91. https://doi.org/10.1016/j.ins.2017.10.017 doi: 10.1016/j.ins.2017.10.017
|
| [43] |
Thabtah F, Hammoud S, Kamalov F, et al. (2020) Data imbalance in classification: Experimental evaluation. Inform Sci 513: 429–441. https://doi.org/10.1016/j.ins.2019.11.004 doi: 10.1016/j.ins.2019.11.004
|
| [44] | Wilson DR, Martinez TR (1997) Improved heterogeneous distance functions. J Artif Intell Res 6: 1–34. |
| [45] | Yao Z, Ruzzo WL (2006) A regression-based k nearest neighbor algorithm for gene function prediction from heterogeneous data, BMC Bioinformatics, BioMed Central, 7: 1–11. https://doi.org/10.1186/1471-2105-7-S1-S11 |
| [46] |
Zhang C, Liu C, Zhang X, et al. (2017) An up-to-date comparison of state-of-the-art classification algorithms. Expert Syst Appl 82: 128–150. https://doi.org/10.1016/j.eswa.2017.04.003 doi: 10.1016/j.eswa.2017.04.003
|
| [47] |
Zhou L, Wang H (2012) Loan default prediction on large imbalanced data using random forests. TELKOMNIKA Indonesian J Electr Eng 10: 1519–1525. https://doi.org/10.11591/telkomnika.v10i6.1323 doi: 10.11591/telkomnika.v10i6.1323
|








Figures(9) / Tables(7)
Lindani Dube, Tanja Verster. Enhancing classification performance in imbalanced datasets: A comparative analysis of machine learning models[J]. Data Science in Finance and Economics, 2023, 3(4): 354-379. doi: 10.3934/DSFE.2023021







 DownLoad:
DownLoad: