Citation: Mohammad Masih Sediqi, Harun Or Rashid Howlader, Abdul Matin Ibrahimi, Mir Sayed Shah Danish, Najib Rahman Sabory, Tomonobu Senjyu. Development of renewable energy resources in Afghanistan for economically optimized cross-border electricity trading[J]. AIMS Energy, 2017, 5(4): 691-717. doi: 10.3934/energy.2017.4.691

| [1] | Worldometers. Population of Southern Asia, 2017. Available from: http://www.worldometers.info/world-population/southern-asia-population/. |
| [2] | Central Statistics Office (CSO). Ministry of Statistics and Programme Implementation. Government of India. Available from: http://mospi.nic.in/. |
| [3] | Pakistan Bureau of Statistics (PBS). Ministry of Economic Affairs and Statistics of Pakistan. Available from: http://www.pbs.gov.pk/. |
| [4] | Bangladesh GDP Growth Rate. Available from: http://www.tradingeconomics.com/bangladesh/gdpgrowth. |
| [5] | Integrated Research and Action for Development (IRADe) (2013) Prospects for Regional Cooperation on Cross-Border Electricity Trade in South Asia. |
| [6] | Faheem JB (2016) Energy Crisis in Pakistan. IRA-Int J of Technol Eng 03: 1-16. |
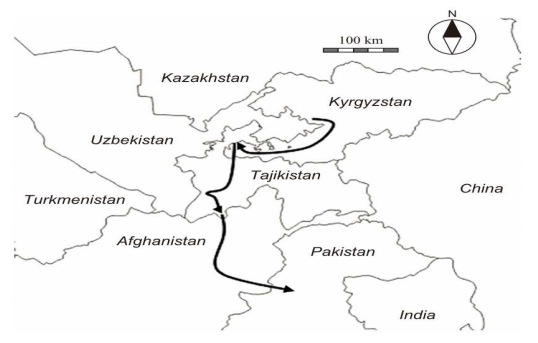
| [7] | CASA-1000. Available from: http://www.casa-1000.org/. |
| [8] | The world Bank. Central Asia-South Asia Electricity Transmission and Trade Project (CASA-1000). Available from: http://www.worldbank.org/en/news/speech/2016/05/13/centralasia-south-asia-electricity-transmission-and-trade-project-casa-1000. |
| [9] |
Sasaki D, Nakayama M (2015) A study on the risk management of the CASA-1000 project. Hydrol Res Lett 9: 90-96. doi: 10.3178/hrl.9.90

|
| [10] | USAID Energy Policy Program (2014) Import of surplus power from Central Asian Republics and Afghanistan to Pakistan. |
| [11] | The World Bank Group. Development of Electricity Trade in Central Asia-South Asia Region. Available from: http://siteresources.worldbank.org/INTSOUTHASIA/556101-1100091707765/21358230/AfghanistanElectricityTradePaperforDelhiRECC(111006).pdf. |
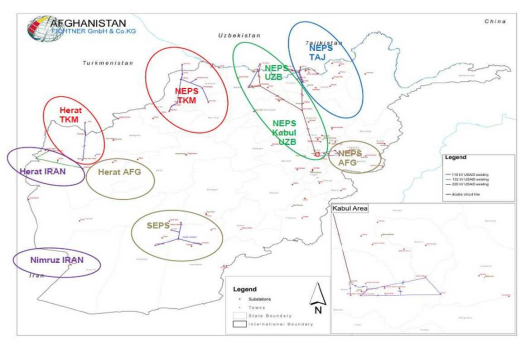
| [12] | ADB Technical Assistance Report (2014) Islamic Republic of Afghanistan: Renewable Energy Development. Capacity Development Technical Assistance (CDTA). Project Number: 47266-001. |
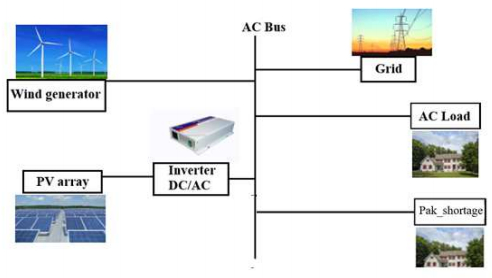
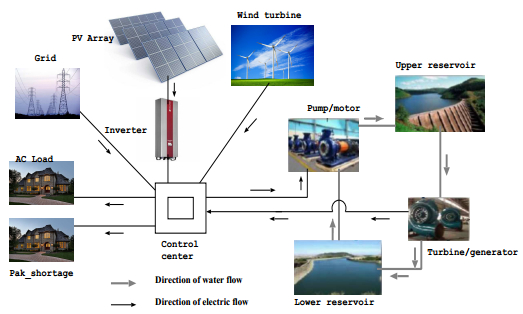
| [13] | Sediqi MM, Furukakoi M, Lotfy ME, et al. (2017) Optimal Economical Sizing of Grid-Connected Hybrid Renewable Energy System. Energy Power Eng 11:244-253. |
| [14] | Aminjonov F. Afghanistan's energy security. Tracing Central Asian countries' contribution. |
| [15] | Irving J, Meier P (2012) Afghanistan Resource Corridor Development: Power Sector Analysis. Australian AID. |
| [16] | Sparrow FT, Brian HB, Shimon KM (2003) General training manual for the purdue long-term electricity trading model. Institute for Interdisciplinary Engineering Studies. |
| [17] |
Shakouri GH, Eghlimi M, Manzoor D (2009) Economically optimized electricity trade modeling: Iran-Turkey case. Energ Policy 37: 472-483. doi: 10.1016/j.enpol.2008.09.074
|
| [18] | Shakouri GH, Eghlimi M, Manzoor D (2006) Power trade between Iran and Turkey: A nonlinear optimization analysis. IEEE 1st Power and Energy Conference. 28-29 November. Malaysia. |
| [19] |
Kousksou T, Bruel P, Jamil A, et al. (2014) Energy storage: applications and challenges. Sol Energ Mat Sol C 120: 59-80. doi: 10.1016/j.solmat.2013.08.015
|
| [20] |
Tao M, Hongxing Y, Lin L, et al. (2015) Pumped storage-based standalone photovoltaic power generation system: Modeling and techno-economic optimization. Appl Energ 137: 649-659. doi: 10.1016/j.apenergy.2014.06.005
|
| [21] |
Tao M, Hongxing Y, Lin L, et al. (2014) Technical feasibility study on a standalone hybrid solarwind system with pumped hydro storage for a remote island in Hong Kong. Renew Energ 69: 7-15. doi: 10.1016/j.renene.2014.03.028
|
| [22] |
Erdinc O, Uzunoglu M (2012) Optimum design of hybrid renewable energy systems: overview of different approaches. Renew Sust Energ Rev 16: 1412-1425. doi: 10.1016/j.rser.2011.11.011
|
| [23] |
Kaabeche A, Belhamel M, Lbtiouen R (2011) Sizing Optimization of Grid-Independent Hybrid Photovoltaic/Wind Power Generation System. Energy 36: 1214-1222. doi: 10.1016/j.energy.2010.11.024
|
| [24] |
Askarzadeh A, dos Santos Coelho L (2015) A Novel Framework for Optimization of a Grid Independent Hybrid Renewable Energy System: A Case Study of Iran. Sol Energ 112: 383-396. doi: 10.1016/j.solener.2014.12.013
|
| [25] |
Hong YY, Lian RC (2012) Optimal Sizing of Hybrid Wind/PV/Diesel Generation in a Stand-Alone Power System Using Markov-Based Genetic Algorithm. IEEE T Power Deliver 27: 640-647. doi: 10.1109/TPWRD.2011.2177102
|
| [26] |
Deshmukh MK, Deshmukh SS (2008) Modeling of Hybrid Renewable Energy Systems. Renew Energ Rev 12: 235-249. doi: 10.1016/j.rser.2006.07.011
|
| [27] | Holland JH (1992) Adaptation in natural and artificial systems. MIT Press. |
| [28] | Malhotra R, Singh N, Singh Y (2011) Genetic algorithms: concepts, design for optimization of process controllers. Computer and Information Science 4: 39-54. |
| [29] |
Feroldi D, Zumoffen D (2014) Sizing methodology for hybrid systems based on multiple renewable power sources integrated to the energy management strategy. Int J of Hydrogen Energ 39: 8609-8620. doi: 10.1016/j.ijhydene.2014.01.003
|
| [30] |
Koutroulis E, Kolokotsa D, Potirakis A, et al. (2006) Methodology for optimal sizing of standalone photovoltaic/wind-generator systems using genetic algorithms. Sol Energ 80: 1072-1088. doi: 10.1016/j.solener.2005.11.002
|





Figures(28) / Tables(4)

Mohammad Masih Sediqi, Harun Or Rashid Howlader, Abdul Matin Ibrahimi, Mir Sayed Shah Danish, Najib Rahman Sabory, Tomonobu Senjyu. Development of renewable energy resources in Afghanistan for economically optimized cross-border electricity trading[J]. AIMS Energy, 2017, 5(4): 691-717. doi: 10.3934/energy.2017.4.691







 DownLoad:
DownLoad: