Citation: Ansgar Steland. Fusing photovoltaic data for improved confidence intervals[J]. AIMS Energy, 2017, 5(1): 125-148. doi: 10.3934/energy.2017.1.125

| [1] | Chang YT, Steland A (2016) Jackknife variance estimation for common mean estimators under ordered variances and general two-sample statistics. [preprint] |
| [2] |
Nair K (1980) Variance and distribution of the Graybill-Deal estimator of the common mean of two normal populations. Ann Stat 8: 212-216. doi: 10.1214/aos/1176344904

|
| [3] |
Tukey JW (1958) Bias and confidence in quite large samples. Ann Math Stat 29: 614. doi: 10.1214/aoms/1177706647
|
| [4] | Shao J, Wu CF (1998) A general theory for jackknife variance estimation. Ann Stat 17: 1176-1197. |
| [5] |
Newman RM, Martin FB (1983) Estimation of fish production rates and associated variances. Can J Fish Aquat Sci 40: 1729-1736. doi: 10.1139/f83-200
|
| [6] |
Graybill FA, Deal RB (1959) Combining unbiased estimators. Biometrics 15: 543-550. doi: 10.2307/2527652
|
| [7] | Parr WC (1985) Jackknifing di erentiable statistical functionals, J Roy Stat Soc B 47: 56-66. |
| [8] | Shao J, Tu D (1995) The Jackknife and Bootstrap. Springer-Verlag, New York. |
| [9] | Steland A, Rafajłowicz E (2014). Decoupling change-point detection based on characteristic functions: Methodology, asymptotics, subsampling and application, J Stat Plan Infer 145: 49-73. |
| [10] | Gregurich MA, Broemeling LD (1989) A Bayesian analysis for estimating the common mean of independent normal populations. Commun Stat- Simul C |
| [11] | Roberts CP (2007) The Bayesian Choice: A Decision-Theoretic Motivation. Springer Texts in Statistics, Springer, New York. |
| [12] |
Berger JO, Bernardo JM, Sun D (2015) Overall objective priors. Bayesian Anal 10: 189-221. doi: 10.1214/14-BA915
|
| [13] | Ghosal Y (1996) A review of consistency and convergence rates of posterior distribution. Proceedings of Varanashi Symposium in Bayesian Inference, Banaras Hindu University, 26: 35-51. |
| [14] | Herrmann W, Althaus J, Steland A, et al. (2006) Statistical and experimental methods for assessing the power output specification of PV modules. Proceedings of the 21st European Photovoltaic Solar Energy Conference 2416-2420. |
| [15] | Herrmann W, Steland A, Herff W (2010) Sampling Procedures for the Validation of PV Module Output Specifcation. Proceedings of the 24th European Photovoltaic Solar Energy Conference, Hamburg 3540-3547. |
| [16] |
Herrmann W, Steland A (2010) Evaluation of Photovoltaic Modules Based on Sampling Inspection Using Smoothed Empirical Quantiles. Prog Photovoltaics 18: 1-9. doi: 10.1002/pip.926
|
| [17] |
Pepelyshev A, Steland A, Avellan-Hampe A (2014) Acceptance sampling plans for photovoltaic modules with two-sided specification limits. Prog Photovoltaics 22: 603-611. doi: 10.1002/pip.2306
|
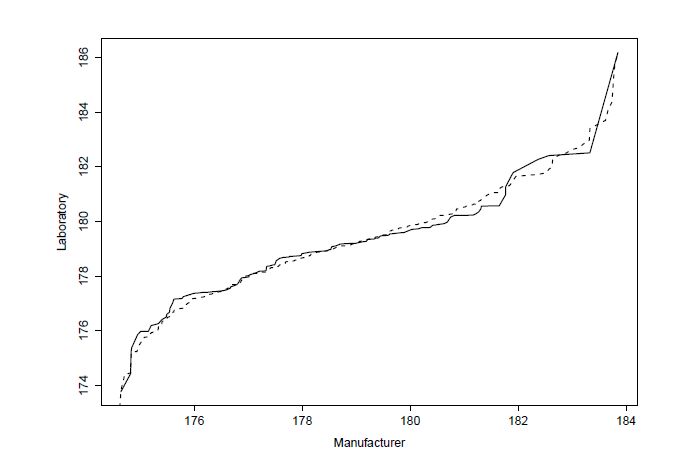
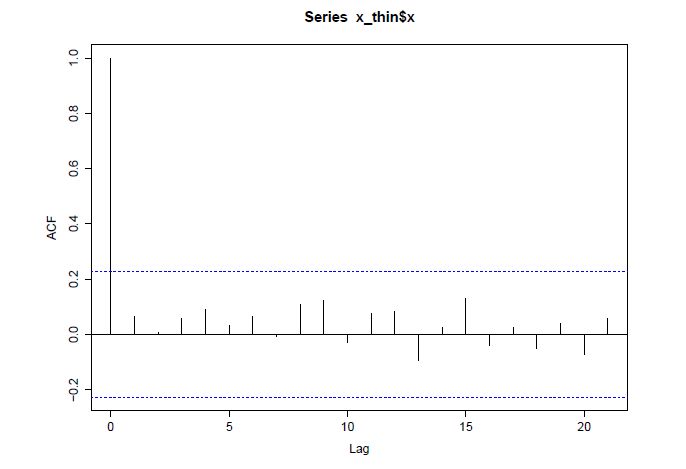
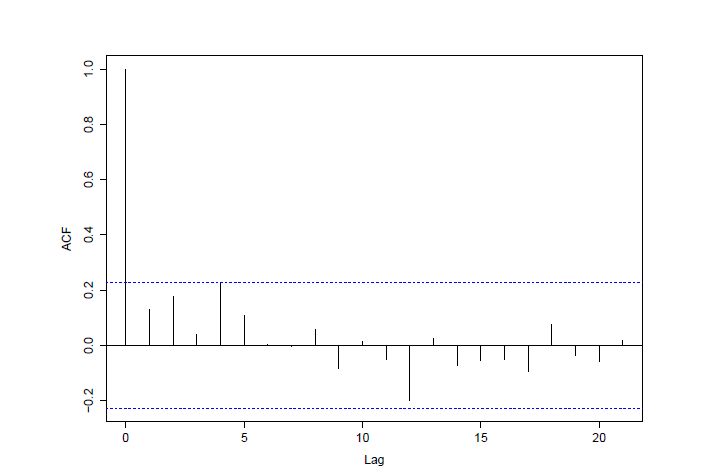
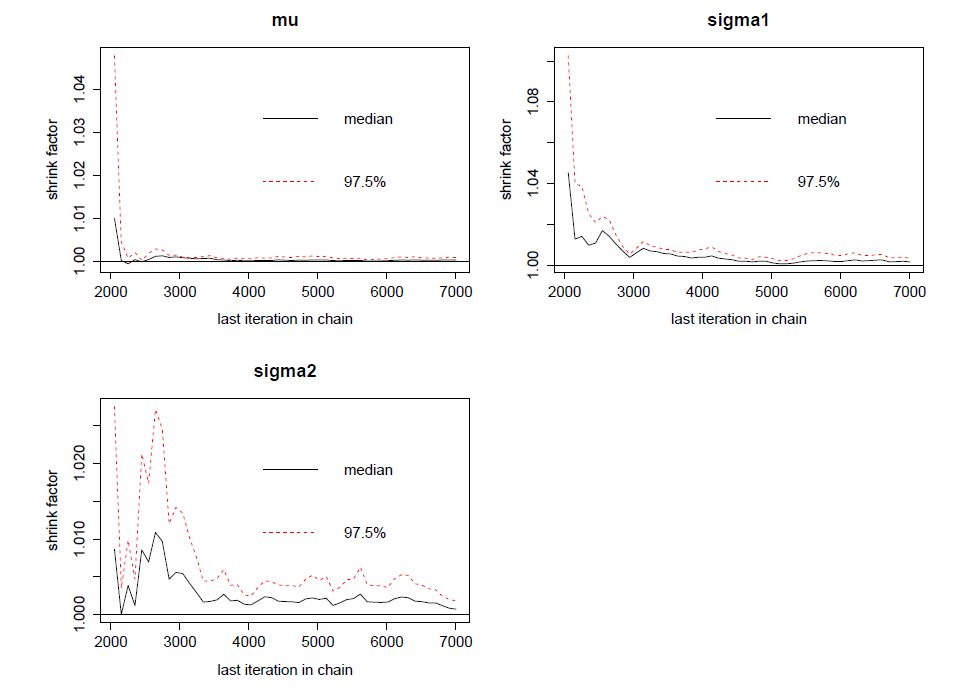
Figures(8) / Tables(3)

Ansgar Steland. Fusing photovoltaic data for improved confidence intervals[J]. AIMS Energy, 2017, 5(1): 125-148. doi: 10.3934/energy.2017.1.125







 DownLoad:
DownLoad: