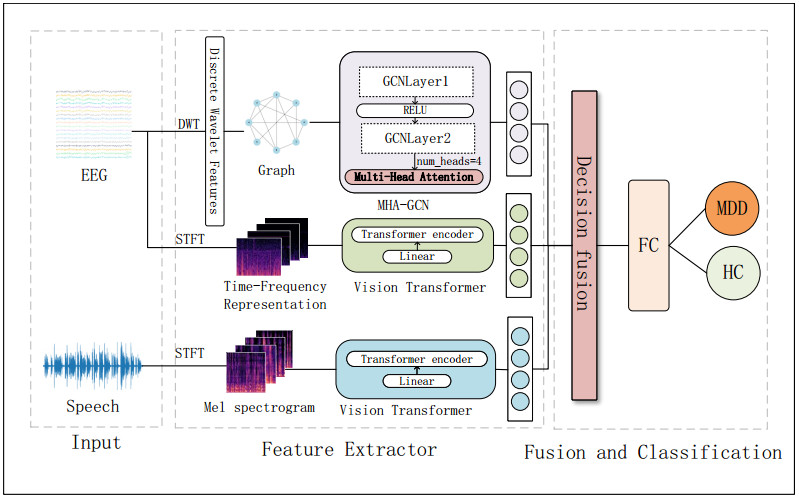
Traditional depression detection methods typically rely on single-modal data, but these approaches are limited by individual differences, noise interference, and emotional fluctuations. To address the low accuracy in single-modal depression detection and the poor fusion of multimodal features from electroencephalogram (EEG) and speech signals, we have proposed a multimodal depression detection model based on EEG and speech signals, named the multi-head attention-GCN_ViT (MHA-GCN_ViT). This approach leverages deep learning techniques, including graph convolutional networks (GCN) and vision transformers (ViT), to effectively extract and fuse the frequency-domain features and spatiotemporal characteristics of EEG signals with the frequency-domain features of speech signals. First, a discrete wavelet transform (DWT) was used to extract wavelet features from 29 channels of EEG signals. These features serve as node attributes for the construction of a feature matrix, calculating the Pearson correlation coefficient between channels, from which an adjacency matrix is constructed to represent the brain network structure. This structure was then fed into a graph convolutional network (GCN) for deep feature learning. A multi-head attention mechanism was introduced to enhance the GCN's capability in representing brain networks. Using a short-time Fourier transform (STFT), we extracted 2D spectral features of EEG signals and mel spectrogram features of speech signals. Both were further processed using a vision transformer (ViT) to obtain deep features. Finally, the multiple features from EEG and speech spectrograms were fused at the decision level for depression classification. A five-fold cross-validation on the MODMA dataset demonstrated the model's accuracy, precision, recall, and F1 score of 89.03%, 90.16%, 89.04%, and 88.83%, respectively, indicating a significant improvement in the performance of multimodal depression detection. Furthermore, MHA-GCN_ViT demonstrated robust performance in depression detection and exhibited broad applicability, with potential for extension to multimodal detection tasks in other psychological and neurological disorders.
Citation: Xiaowen Jia, Jingxia Chen, Kexin Liu, Qian Wang, Jialing He. Multimodal depression detection based on an attention graph convolution and transformer[J]. Mathematical Biosciences and Engineering, 2025, 22(3): 652-676. doi: 10.3934/mbe.2025024
Traditional depression detection methods typically rely on single-modal data, but these approaches are limited by individual differences, noise interference, and emotional fluctuations. To address the low accuracy in single-modal depression detection and the poor fusion of multimodal features from electroencephalogram (EEG) and speech signals, we have proposed a multimodal depression detection model based on EEG and speech signals, named the multi-head attention-GCN_ViT (MHA-GCN_ViT). This approach leverages deep learning techniques, including graph convolutional networks (GCN) and vision transformers (ViT), to effectively extract and fuse the frequency-domain features and spatiotemporal characteristics of EEG signals with the frequency-domain features of speech signals. First, a discrete wavelet transform (DWT) was used to extract wavelet features from 29 channels of EEG signals. These features serve as node attributes for the construction of a feature matrix, calculating the Pearson correlation coefficient between channels, from which an adjacency matrix is constructed to represent the brain network structure. This structure was then fed into a graph convolutional network (GCN) for deep feature learning. A multi-head attention mechanism was introduced to enhance the GCN's capability in representing brain networks. Using a short-time Fourier transform (STFT), we extracted 2D spectral features of EEG signals and mel spectrogram features of speech signals. Both were further processed using a vision transformer (ViT) to obtain deep features. Finally, the multiple features from EEG and speech spectrograms were fused at the decision level for depression classification. A five-fold cross-validation on the MODMA dataset demonstrated the model's accuracy, precision, recall, and F1 score of 89.03%, 90.16%, 89.04%, and 88.83%, respectively, indicating a significant improvement in the performance of multimodal depression detection. Furthermore, MHA-GCN_ViT demonstrated robust performance in depression detection and exhibited broad applicability, with potential for extension to multimodal detection tasks in other psychological and neurological disorders.

| [1] | T. Widiger, Diagnostic and Statistical Manual of Mental Disorders (DSM), 5$^{nd}$ edition, obo in Psychology, 2011. https://doi.org/10.1093/obo/9780199828340-0022 |
| [2] | J. Li, R. Zhao, Y. Zhang, The development and application of artificial intelligence Counseling, Psychol.Tech. Appl., 10 (2022), 296–306. |
| [3] |
L. Yang, Trends and prediction of the burden of depression among adolescents aged 10 to 24 years in China from 1990 to 2019, Chin. J. Sch. Health, 44 (2023), 1063–1067. Available from: https://link.cnki.net/doi/10.16835/j.cnki.1000-9817.2023.07.023 doi: 10.16835/j.cnki.1000-9817.2023.07.023

|
| [4] |
Y. Hou, S. Jia, X. Lun, Z. Hao, Y. Shi, Y. Li, GCNs-net: A graph convolutional neural network approach for decoding time-resolved eeg motor imagery signals, IEEE Trans. Neural Networks Learn. Syst., 35 (2024), 7312–7323. https://doi.org/10.1109/TNNLS.2022.3202569 doi: 10.1109/TNNLS.2022.3202569
|
| [5] |
J. Ancilin, A. Milton, Improved speech emotion recognition with Mel frequency magnitude coefficient, Appl. Acousti., 179 (2021), 108046. https://doi.org/10.1016/j.apacoust.2021.108046 doi: 10.1016/j.apacoust.2021.108046
|
| [6] |
S. K. Khare, V. Bajaj, U. R. Acharya, SchizoNET: A robust and accurate Margenau-Hill time-frequency distribution based deep neural network model for schizophrenia detection using EEG signals, Physiolog. Meas., 44 (2023), 035005. https://doi.org/10.1088/1361-6579/acbc06 doi: 10.1088/1361-6579/acbc06
|
| [7] |
E. S. A. El-Dahshan, M. M. Bassiouni, S. K. Khare, R. S. Tan, U. R. Acharya, ExHyptNet: An explainable diagnosis of hypertension using EfficientNet with PPG signals, Expert Syst. Appl., 239 (2024), 122388. https://doi.org/10.1016/j.eswa.2023.122388 doi: 10.1016/j.eswa.2023.122388
|
| [8] |
S. Siuly, S. K. Khare, E. Kabir, M. T. Sadiq, H. Wang, An efficient Parkinson's disease detection framework: Leveraging time-frequency representation and AlexNet convolutional neural network, Computers Biol. Med., 174 (2024), 108462. https://doi.org/10.1016/j.compbiomed.2024.108462 doi: 10.1016/j.compbiomed.2024.108462
|
| [9] | S. K. Khare, V. Bajaj, S. Taran, G. R. Sinha, 1-Multiclass sleep stage classification using artificial intelligence based time-frequency distribution and CNN, Artif. Intell. Brain-Comput. Interface, (2022), 1–21. https://doi.org/10.1016/B978-0-323-91197-9.00012-6 |
| [10] |
Z. Wan, M. Li, S. Liu, J. Huang, H. Tan, W. Duan, EEGformer: A transformer-based brain activity classification method using EEG signal, Front. Neurosci., 17 (2023), 1148855. https://doi.org/10.3389/fnins.2023.1148855 doi: 10.3389/fnins.2023.1148855
|
| [11] |
Q. Gong, Y. He, Depression, neuroimaging and connectomics: A selective overview, Biol. Psychiatry, 77 (2015), 223–235. https://doi.org/10.1016/j.biopsych.2014.08.009 doi: 10.1016/j.biopsych.2014.08.009
|
| [12] | F. Jia, H. Tang, J. Shi, Q. Lu, C. Liu, K. Bi, et al., Relationship between magnetoencephalography spectrum individual spectral power of depressed patients and the severity of clinical symptom clusters, Nanjing Brain Hosp. Affil. Nanjing Med. Univ., 25 (2015), 145–148. |
| [13] | Y. Jiang, Abnormal connectivity patterns of core networks between schizophrenia and depression, Master's thesis, University of Electronic Science and Technology of China, 2017. |
| [14] |
X. Liu, S. Liu, D. Guo, X. An, J. Yang, D. Ming, Research progress in electroencephalography of depression, Chin. J. Biomed. Eng., 39 (2020), 351–361. https://doi.org/10.3969/j.issn.0258-8021.2020.03.13 doi: 10.3969/j.issn.0258-8021.2020.03.13
|
| [15] | S. K. Khare, S. March, P. D. Barua, V. M. Gadre, U. R. Acharya, Application of data fusion for automated detection of children with developmental and mental disorders: A systematic review of the last decade, Inf. Fusion, (2023), 101898. https://doi.org/10.1016/j.inffus.2023.101898 |
| [16] |
J. Yang, Z. Zhang, P. Xiong, X. Liu, Depression detection based on analysis of EEG signals in multi brain regions, J. Integr. Neurosci., 22 (2023), 93. https://doi.org/10.31083/j.jin2204093 doi: 10.31083/j.jin2204093
|
| [17] |
Y. Li, Y. Zhao, X. Li, Z. Liu, J. Chen, H. Guo, Construction of brain functional hypernetwork and feature fusion analysis based on sparse group Lasso method, J. Comput. Appl., 40 (2020), 62–70. https://doi.org/10.11772/j.issn.1001-9081.2019061026 doi: 10.11772/j.issn.1001-9081.2019061026
|
| [18] |
B. Yang, Y. Guo, S. Hao, R. Hong, Application of graph neural network based on data augmentation and model ensemble in depression recognition, Comput. Sci., 49 (2022), 57–63. https://doi.org/10.11896/jsjkx.210800070 doi: 10.11896/jsjkx.210800070
|
| [19] |
T. Chen, R. Hong, Y. Guo, S. Hao, B. Hu, MS$^{2}$-GNN: Exploring GNN-based multimodal fusion network for depression detection, IEEE Trans. Cybern., 53 (2023), 7749–7759. https://doi.org/10.1109/TCYB.2022.3197127 doi: 10.1109/TCYB.2022.3197127
|
| [20] |
Z. Zhang, Q. Meng, L. Jin, H. Wang, H. Hou, A novel EEG-based graph convolution network for depression detection: Incorporating secondary subject partitioning and attention mechanism, Expert Syst. Appl., 239 (2024), 122356. https://doi.org/10.1016/j.eswa.2023.122356 doi: 10.1016/j.eswa.2023.122356
|
| [21] | H. Wu, J. Liu, Y. Zhao, EEG-Based depression identification using a deep learning model, 2022 IEEE Conference on Information and Communication Technology (CICT), (2022). https://doi.org/10.1109/CICT56698.2022.9997829 |
| [22] |
J. Qin, Z. Qin, F. Li, Y. Peng, Diagnosis of major depressive disorder based on probabilistic sparse self-attention neural network, J. Comput. Appl., 44 (2024), 2970–2974. https://doi.org/10.11772/j.issn.1001-9081.2023091371 doi: 10.11772/j.issn.1001-9081.2023091371
|
| [23] |
J. Bo, S. Chen, B. Wang, B. Luo, MGLNN: Semi-supervised learning via multiple graph cooperative learning neural networks, Neural Networks, 153 (2022), 204–214. https://doi.org/10.1016/j.neunet.2022.05.024 doi: 10.1016/j.neunet.2022.05.024
|
| [24] |
T. Wu, L. Yang, L. Xu, The application and challenges of Artificial Intelligence in audio signal processing, Audio Eng., 48 (2024), 31–34. Available from: https://link.cnki.net/doi/10.16311/j.audioe.2024.05.009 doi: 10.16311/j.audioe.2024.05.009
|
| [25] |
A. Y. Kim, E. H. Jang, S. H. Lee, K. Y. Choi, J. G. Park, H. C. Shin, Automatic depression detection using smartphone-based Text-Dependent speech signals: Deep convolutional neural network approach, J. Med. Internet Res., 25 (2023), e34474. https://doi.org/10.2196/34474 doi: 10.2196/34474
|
| [26] |
W. Yang, J. Liu, P. Cao, R. Zhu, Y. Wang, J. K. Liu, et al., Attention guided learnable Time-Domain filterbanks for speech depression detection, Neural Networks, 165 (2023), 135–149. https://doi.org/10.1016/j.neunet.2023.05.041 doi: 10.1016/j.neunet.2023.05.041
|
| [27] |
F. Yin, J. Du, X. Xu, L. Zhao, Depression detection in speech using Transformer and parallel convolutional neural networks, Electronics, 12 (2023), 328. https://doi.org/10.3390/electronics12020328 doi: 10.3390/electronics12020328
|
| [28] |
E. Debie, R. F. Rojas, J. Fidock, M. Barlow, K. Kasmarik, S. Anavatti, Multimodal fusion for objective assessment of cognitive workload: A review, IEEE Trans. Cybern., 51 (2019), 1542–1555. https://doi.org/10.1109/TCYB.2019.2939399 doi: 10.1109/TCYB.2019.2939399
|
| [29] |
Y. Liu, Y. Shi, F. Mu, J. Cheng, X.Chen, Glioma segmentation-oriented multi-modal MR image fusion with adversarial learning, IEEE/CAA J. Autom. Sin., 9 (2022), 1528–1531. https://doi.org/10.1109/JAS.2022.105770 doi: 10.1109/JAS.2022.105770
|
| [30] |
Z. Zhu, X. He, G. Qi, Y. Li, B. Cong, Y. Liu, Brain tumor segmentation based on the fusion of deep semantics and edge information in multimodal MRI, Inf. Fusion, 91 (2023), 376–387. https://doi.org/10.1016/j.inffus.2022.10.022 doi: 10.1016/j.inffus.2022.10.022
|
| [31] |
Z. Zhu, Z. Wang, G. Qi, N. Mazur, P. Yang, Y. Liu, Brain tumor segmentation in MRI with multi-modality spatial information enhancement and boundary shape correction, Pattern Recognit., 153 (2024), 110553. https://doi.org/10.1016/j.patcog.2024.110553 doi: 10.1016/j.patcog.2024.110553
|
| [32] |
Y. Liu, Z. Qi, J. Cheng, X. Chen, Rethinking the effectiveness of objective evaluation metrics in multi-focus image fusion: A statistic-based approach, IEEE Trans. Pattern Anal. Mach. Intell., 46 (2024), 5806–5819. https://doi.org/10.1109/TPAMI.2024.3367905 doi: 10.1109/TPAMI.2024.3367905
|
| [33] | A. M. Bucur, A. Cosma, P. Rosso, L. P. Dinu, It's just a matter of time: detecting depression with Time-Enriched multimodal Transformers, In Advances in Information Retrieval, ECIR 2023, Lecture Notes in Computer Science (eds. J. Kamps), Springer, Cham, (2023), 200–215. https://doi.org/10.1007/978-3-031-28244-7_13 |
| [34] |
A. M. Roy, R. Bose, J. Bhaduri, A fast accurate fine-grain object detection model based on YOLOv4 deep neural network, Neural Comput. Appl., 34 (2022), 3895–3921. https://doi.org/10.1007/s00521-021-06651-x doi: 10.1007/s00521-021-06651-x
|
| [35] |
A. M. Roy, J. Bhaduri, DenseSPH-YOLOv5: An automated damage detection model based on DenseNet and Swin-Transformer prediction head-enabled YOLOv5 with attention mechanism, Adv. Eng. Inform., 56 (2023), 102007. https://doi.org/10.1016/j.aei.2023.102007 doi: 10.1016/j.aei.2023.102007
|
| [36] |
S. Jamil, A. M. Roy, An efficient and robust phonocardiography (pcg)-based valvular heart diseases (vhd) detection framework using vision transformer (vit), Comput. Biol. Med., 158 (2023), 106734. https://doi.org/10.1016/j.compbiomed.2023.106734 doi: 10.1016/j.compbiomed.2023.106734
|
| [37] |
H. Fan, X. Zhang, Y. Xu, J. Fang, S. Zhang, X. Zhao, et al., Transformer-Based multimodal feature enhancement networks for multimodal depression detection integrating video, audio and remote photoplethysmograph signals, Inf. Fusion, 104 (2024), 102161. https://doi.org/10.1016/j.inffus.2023.102161 doi: 10.1016/j.inffus.2023.102161
|
| [38] |
Z. Ning, H. Hu, L. Yi, Z. Qie, A. Tolba, X. Wang, A depression detection auxiliary decision system based on multi-modal Feature-Level fusion of EEG and speech, IEEE Trans. Consum. Electron., 70 (2024), 3392–3402. https://doi.org/10.1109/TCE.2024.3370310 doi: 10.1109/TCE.2024.3370310
|
| [39] |
A. Qayyum, I. Razzak, M. Tanveer, M. Mazher, B. Alhaqbani, High-Density electroencephalography and speech signal based deep framework for clinical depression diagnosis, IEEE/ACM Trans. Comput. Biol. Bioinform., 20 (2023), 2587–2597. https://doi.org/10.1109/TCBB.2023.3257175 doi: 10.1109/TCBB.2023.3257175
|
| [40] | A. Dosovitskiy, An image is worth 16x16 words: Transformers for image recognition at scale, preprint, arXiv: 2010.11929. |
| [41] | H. Cai, Y. Gao, S. Sun, N. Li, F. Tian, H. Xiao, et al., MODMA dataset: A multi-modal open dataset for Mental-Disorder analysis, preprint, arXiv: 2002.09283. |
| [42] |
Y. Li, Discussion on MFCC algorithm in speech signal feature extraction, J. High. Corresp. Educ.(Nat. Sci.), 25 (2012), 78–80. https://doi.org/10.3969/j.issn.1006-7353.2012.04.036 doi: 10.3969/j.issn.1006-7353.2012.04.036
|
| [43] |
M. Gu, B. Fan, Feature-level multimodal fusion for depression recognition, Comput. Mod., 10 (2023), 17–22. https://doi.org/10.3969/j.issn.1006-2475.2023.10.003 doi: 10.3969/j.issn.1006-2475.2023.10.003
|
| [44] | Y. Hu, S. Zhang, T. Dang, H. Jia, F. D. Salim, W. Hu, et al., Exploring large-scale language models to evaluate eeg-based multimodal data for mental health, in Companion of the 2024 on ACM International Joint Conference on Pervasive and Ubiquitous Computing, 6 (2024), 412–417. https://doi.org/10.1145/3675094.3678494 |
| [45] |
S. K. Khare, V. Blanes-Vidal, E. S. Nadimi, U. R. Acharya, Emotion recognition and artificial intelligence: A systematic review (2014–2023) and research recommendations, Inf. Fusion, 102 (2024), 102019. https://doi.org/10.1016/j.inffus.2023.102019 doi: 10.1016/j.inffus.2023.102019
|
| [46] |
A. Singh, K. Raj, T. Kumar, S. Verma, A. M. Roy, Deep learning-based cost-effective and responsive robot for autism treatment, Drones, 7 (2023), 81. https://doi.org/10.3390/drones7020081 doi: 10.3390/drones7020081
|
| [47] |
L. Sun, D. Liu, M. Wang, Y. Han, Y. Zhang, B. Zhou, Taming unleashed large language models with blockchain for massive personalized reliable healthcare, IEEE J. Biomed. Health Inform., 2025 (2025), 1–20. https://doi.org/10.1109/JBHI.2025.3528526 doi: 10.1109/JBHI.2025.3528526
|







Figures(8) / Tables(5)

Xiaowen Jia, Jingxia Chen, Kexin Liu, Qian Wang, Jialing He. Multimodal depression detection based on an attention graph convolution and transformer[J]. Mathematical Biosciences and Engineering, 2025, 22(3): 652-676. doi: 10.3934/mbe.2025024







 DownLoad:
DownLoad: