Citation: Hao Zhu, Nan Wang, Jonathan Z. Sun, Ras B. Pandey, Zheng Wang. Inferring the three-dimensional structures of the X-chromosome during X-inactivation[J]. Mathematical Biosciences and Engineering, 2019, 16(6): 7384-7404. doi: 10.3934/mbe.2019369

| [1] | J. Dekker, K. Rippe, M. Dekker, et al., Capturing chromosome conformation, Science, 295 (2002), 1306–1311. |
| [2] | M. Simonis, P. Klous, E. Splinter, et al., Nuclear organization of active and inactive chromatin domains uncovered by chromosome conformation capture-on-chip (4C), Nat. Genet., 38 (2006), 1348–1354. |
| [3] | J. Dostie, T. A. Richmond, R. A. Arnaout, et al., Chromosome Conformation Capture Carbon Copy (5C): A massively parallel solution for mapping interactions between genomic elements, Genome Res., 16 (2006), 1299–1309. |
| [4] | E. Lieberman-Aiden, N. L. van Berkum, L. Williams, et al., Comprehensive mapping of long-range interactions reveals folding principles of the human genome, Science, 326 (2009), 289–293. |
| [5] | L. Harewood, K. Kishore, M. D. Eldridge, et al., Hi-C as a tool for precise detection and characterisation of chromosomal rearrangements and copy number variation in human tumours, Genome Biol., 18 (2017), 125. |
| [6] | H. Won, L. de la Torre-Ubieta, J. L. Stein, et al., Chromosome conformation elucidates regulatory relationships in developing human brain, Nature, 538 (2016), 523–527. |
| [7] | F. Jin, Y. Li, J. R. Dixon, et al., A high-resolution map of the three-dimensional chromatin interactome in human cells, Nature, 503 (2013), 290–294. |
| [8] | J. R. Dixon, S. Selvaraj, F. Yue, et al., Topological domains in mammalian genomes identified by analysis of chromatin interactions, Nature, 485 (2012), 376–380. |
| [9] | T. Nagano, Y. Lubling, T. J. Stevens, et al., Single-cell Hi-C reveals cell-to-cell variability in chromosome structure, Nature, 502 (2013), 59–64. |
| [10] | H. Zhu and Z. Wang, SCL: A lattice-based approach to infer three-dimensional chromosome structures from single-cell Hi-C data, Bioinformatics, (2019). |
| [11] | Z. Duan, M. Andronescu, K. Schutz, et al., A three-dimensional model of the yeast genome, Nature, 465 (2010), 363–367. |
| [12] | D. Bau, A. Sanyal, B. R. Lajoie, et al., The three-dimensional folding of the alpha-globin gene domain reveals formation of chromatin globules, Nat. Struct. Mol. Biol., 18 (2011), 107–114. |
| [13] | H. Tanizawa, O. Iwasaki, A. Tanaka, et al., Mapping of long-range associations throughout the fission yeast genome reveals global genome organization linked to transcriptional regulation, Nucleic Acids Res., 38 (2010), 8164–8177. |
| [14] | Z. Zhang, G. Li, K. C. Toh, et al., 3D chromosome modeling with semi-definite programming and Hi-C data, J. Comput. Biol., 20 (2013), 831–846. |
| [15] | S. Ben-Elazar, Z. Yakhini and I. Yanai, Spatial localization of co-regulated genes exceeds genomic gene clustering in the Saccharomyces cerevisiae genome, Nucleic Acids Res., 41 (2013), 2191–2201. |
| [16] | N. Varoquaux, F. Ay, W. S. Noble, et al., A statistical approach for inferring the 3D structure of the genome, Bioinformatics, 30 (2014), i26–33. |
| [17] | M. Hu, K. Deng, Z. Qin, et al., Bayesian inference of spatial organizations of chromosomes, PLoS Comput. Biol., 9 (2013), e1002893. |
| [18] | C. Zou, Y. Zhang and Z. Ouyang, HSA: Integrating multi-track Hi-C data for genome-scale reconstruction of 3D chromatin structure, Genome Biol., 17 (2016), 40. |
| [19] | O. Oluwadare, Y. Zhang and J. Cheng, A maximum likelihood algorithm for reconstructing 3D structures of human chromosomes from chromosomal contact data, BMC Genomics, 19 (2018), 161. |
| [20] | D. W. Heermann, H. Jerabek, L. Liu, et al., A model for the 3D chromatin architecture of pro and eukaryotes, Methods, 58 (2012), 307–314. |
| [21] | P. M. Diesinger and D. W. Heermann, Monte Carlo Simulations indicate that Chromati: Nanostructure is accessible by Light Microscopy, PMC Biophys, 3 (2010), 11. |
| [22] | M. F. Lyon, Gene action in the X-chromosome of the mouse (Mus musculus L.), Nature, 190 (1961), 372–373. |
| [23] | C. J. Brown, B. D. Hendrich, J. L. Rupert, et al., The human XIST gene: Analysis of a 17 kb inactive X-specific RNA that contains conserved repeats and is highly localized within the nucleus, Cell, 71 (1992), 527–542. |
| [24] | N. Brockdorff, A. Ashworth, G. F. Kay, et al., The product of the mouse Xist gene is a 15 kb inactive X-specific transcript containing no conserved ORF and located in the nucleus, Cell, 71 (1992), 515–526. |
| [25] | C. J. Brown, A. Ballabio, J. L. Rupert, et al., A gene from the region of the human X inactivation centre is expressed exclusively from the inactive X chromosome, Nature, 349 (1991), 38–44. |
| [26] | N. Brockdorff, A. Ashworth, G. F. Kay, et al., Conservation of position and exclusive expression of mouse Xist from the inactive X chromosome, Nature, 351 (1991), 329–331. |
| [27] | R. M. Boumil and J. T. Lee, Forty years of decoding the silence in X-chromosome inactivation, Hum. Mol. Genet., 10 (2001), 2225–2232. |
| [28] | G. Bonora and C. M. Disteche, Structural aspects of the inactive X chromosome, Philos Trans. R Soc. Lond. B Biol. Sci., 372 (2017). |
| [29] | C. Naughton, D. Sproul, C. Hamilton, et al., Analysis of active and inactive X chromosome architecture reveals the independent organization of 30 nm and large-scale chromatin structures, Mol. Cell, 40 (2010), 397–409. |
| [30] | A. Minajigi, J. Froberg, C. Wei, et al., Chromosomes. A comprehensive Xist interactome reveals cohesin repulsion and an RNA-directed chromosome conformation, Science, 349 (2015). |
| [31] | E. P. Nora, B. R. Lajoie, E. G. Schulz, et al., Spatial partitioning of the regulatory landscape of the X-inactivation centre, Nature, 485 (2012), 381–385. |
| [32] | X. Deng, W. Ma, V. Ramani, et al., Bipartite structure of the inactive mouse X chromosome, Genome Biol., 16 (2015), 152. |
| [33] | J. Chaumeil, S. Augui, J. C. Chow, et al., Combined immunofluorescence, RNA fluorescent in situ hybridization, and DNA fluorescent in situ hybridization to study chromatin changes, transcriptional activity, nuclear organization and X-chromosome inactivation, Methods Mol. Biol., 463 (2008), 297–308. |
| [34] | J. M. Engreitz, A. Pandya-Jones, P. McDonel, et al., The Xist lncRNA exploits three-dimensional genome architecture to spread across the X chromosome, Science, 341 (2013), 1237973. |
| [35] | L. Giorgetti, B. R. Lajoie, A. C. Carter, et al., Structural organization of the inactive X chromosome in the mouse, Nature, 535 (2016), 575–579. |
| [36] | R. B. Pandey and B. L. Farmer, Conformational response to solvent interaction and temperature of a protein (Histone h3.1) by a multi-grained monte carlo simulation, PLoS One, 8 (2013), e76069. |
| [37] | K. Binder, Monte Carlo and molecular dynamics simulations in polymer science. New York:Oxford University Press. 1995, xiv, pp587. |
| [38] | S. Kirkpatrick, C. D. Gelatt Jr. and M. P. Vecchi, Optimization by simulated annealing, Science, 220 (1983), 671–680. |
| [39] | Z. Wang, J. Eickholt and J. Cheng, APOLLO: A quality assessment service for single andmultiple protein models, Bioinformatics, 27 (2011), 1715–1716. |
| [40] | Y. Zhang and J. Skolnick, TM-align: A protein structure alignment algorithm based on theTM-score, Nucleic Acids Res., 33 (2005), 2302–2309. |
| [41] | A. Kryshtafovych, A. Barbato, K. Fidelis, et al., Assessment of the assessment: Evaluation of themodel quality estimates in CASP10, Proteins, 82 Suppl 2 (2014), 112–126. |


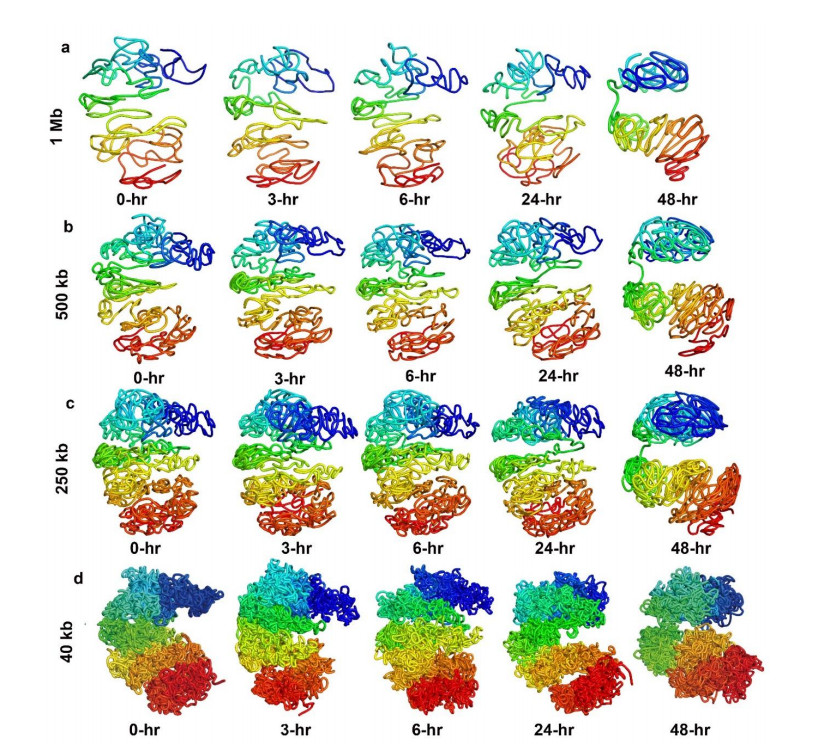
Figures(7)

Hao Zhu, Nan Wang, Jonathan Z. Sun, Ras B. Pandey, Zheng Wang. Inferring the three-dimensional structures of the X-chromosome during X-inactivation[J]. Mathematical Biosciences and Engineering, 2019, 16(6): 7384-7404. doi: 10.3934/mbe.2019369







 DownLoad:
DownLoad: