Citation: Elvira Caloiero, Massimo Guidolin. Volatility as an Alternative Asset Class: Does It Improve Portfolio Performance?[J]. Quantitative Finance and Economics, 2017, 1(4): 334-362. doi: 10.3934/QFE.2017.4.334

| [1] | Adams Z, Füss R, Glück T (2017) Are correlations constant? Empirical and theoretical results on popular correlation models in finance. J Bank Financ 84: 9–24. |
| [2] |
Alexander C, Kapraun J, Korovilas D (2015) Trading and investing in volatility products. Financ Mark, Inst Instrum 24: 313–347. doi: 10.1111/fmii.12032

|
| [3] | Alexander C, Korovilas D (2013) Volatility exchange-traded notes: curse or cure? J Altern Invest 12: 52–70. |
| [4] | Amenc N, Glotz F, Grigoriu A (2010) Risk Control through Dynamic Core-Satellite Portfolios of ETFs: Applications to Absolute Return Funds and Tactical Asset Allocation. EDHEC-Risk Institute Publication. |
| [5] |
Bhansali V (2008) Tail risk management. J Portf Manage 34: 68–75. doi: 10.3905/jpm.2008.709982
|
| [6] |
Bekaert G, Wu G (2000) Asymmetric Volatility and Risk in Equity Markets. Rev Financ Stud 13: 1–42. doi: 10.1093/rfs/13.1.1
|
| [7] |
Bollen N, O'Neill MJ, Whaley R (2017) Tail Wags Dog: Intraday Price Discovery in VIX Markets. J Futures Mark 37: 431–451. doi: 10.1002/fut.21805
|
| [8] | Black K (2006) Improving Hedge Fund Risk Exposures by Hedging Equity Market Volatility, or How the VIX Ate My Kurtosis. J Trading 1: 6–15. |
| [9] |
Brenner M, Ou E, Zhang J (2006) Hedging Volatility Risk. J Bank Financ 30: 811–821. doi: 10.1016/j.jbankfin.2005.07.015
|
| [10] | Brière M, Burgues A, Signori O (2009) Volatility Exposure for Strategic Asset Allocation. J Portf Manage 36: 105–116. |
| [11] |
Carroll R, Conlon T, Cotter J, et al. (2017) Asset allocation with correlation: A composite trade-off. European J Oper Res 262: 1164–1180. doi: 10.1016/j.ejor.2017.04.015
|
| [12] | Chicago Board Options Exchange (2003) VIX: CBOE Volatility Index. Working Paper. |
| [13] | Dash S, Liu B (2012) Volatility ETFs and ETNs. J Trading 7: 43–48. |
| [14] |
Dash S, Moran MT (2005) VIX as a Companion for Hedge Fund Portfolios. J Altern Invest 8: 75–80. doi: 10.3905/jai.2005.608034
|
| [15] | DeLisle J, Doran JS, Krieger K (2010) Volatility as an Asset Class: Holding VIX in a Portfolio. Working Paper. |
| [16] | DeMiguel V, Garlappi L, Uppal R (2007) Optimal Versus Naive Diversification: How Inefficient is the 1/N Portfolio Strategy? Rev Financ Stud 22: 1915–1953. |
| [17] |
Doran J, Krieger K (2010) Implications for Asset Returns in the Implied Volatility Skew. Financ Anal J 66: 65–76. doi: 10.2469/faj.v66.n1.9
|
| [18] |
Fallon W, Park J, Yun D (2015) Asset Allocation Implications of the Global Volatility Premium. Financ Anal J 71: 38–56. doi: 10.2469/faj.v71.n5.4
|
| [19] |
Füss R, Grabellus M, Mager F, et al. (2014) How risk-return efficient are target risk strategies? J Index Invest 4: 33–42. doi: 10.3905/jii.2014.4.4.033
|
| [20] | Grant M, Gregory K, Lui J (2007) Volatility as an Asset. Goldman Sachs Equity Research. |
| [21] | Guidolin M (2013) Preference Models in Portfolio Construction and Evaluation, in K., Baker and G., Filbeck (eds.), Portf Theory Manage, chapter 11, Oxford University Press. |
| [22] | Guidolin M, Timmermann A (2005) Optimal Portfolio Choice under Regime Switching, Skew and Kurtosis Preferences. Federal Reserve Bank of St. Louis W.P. No. 2005-006A. |
| [23] |
Guidolin M, Timmermann A (2008) International Asset Allocation under Regime Switching, Skew and Kurtosis Preferences. Rev Financ Stud 21: 889–935. doi: 10.1093/rfs/hhn006
|
| [24] | Hancock G (2013) VIX futures ETNs: three dimensional losers. Account Financ Res 2: 53–64. |
| [25] | Jondeau E, Rockinger M (2006) Optimal Portfolio Allocation under Higher Moments. European Financ Manage 12: 29–55. |
| [26] | Hafner R, Wallmeier M (2008) Optimal Investments in Volatility. Financ Mark Portf Manage 22: 147–167. |
| [27] |
Hafner R, Wallmeier M (2007) Volatility as an Asset Class: European Evidence. European J Financ 13: 621–644. doi: 10.1080/13518470701380142
|
| [28] |
Jondeau E, Rockinger M (2006) Optimal Portfolio Allocation under Higher Moments. European Financ Manage 12: 29–55. doi: 10.1111/j.1354-7798.2006.00309.x
|
| [29] | Kuenzi D, Xu S (2007) Asset Based Style Analysis for Equity Strategies: The Role of the Volatility Factor. J Altern Invest 10: 10–24. |
| [30] |
Rakowski D, Shirley SE, Stark JR (2017) Tail-risk hedging, dividend chasing, and investment constraints: The use of exchange-traded notes by mutual funds. J Empir Financ 44: 91–107. doi: 10.1016/j.jempfin.2017.08.003
|
| [31] | Scott R, Horvath P (1980) On the Direction of Preference for Moments of Higher Order than the Variance. J Financ 35: 915–919. |
| [32] | Sharpe W (2006) Expected Utility Asset Allocation. Financ Anal J 63: 12–39. |
| [33] | Stanton C (2011) Volatility as an Asset Class. J Invest Consult 12: 23–30. |
| [34] |
Szado E (2009) VIX Futures and Options: A Case Study of Portfolio Diversification during the 2008 Financial Crisis. J Altern Invest 12: 68–95. doi: 10.3905/JAI.2009.12.2.068
|
| [35] | Whaley R (2000) The Investor Fear Gauge. J Portf Manage 26: 12–17. |
| [36] |
Whaley R (2009) Understanding the VIX. J Portf Manage 35: 98–105. doi: 10.3905/JPM.2009.35.3.098
|
| [37] | Whaley R (2013) Trading Volatility: At What Cost? J Portf Manage 40: 95–108. |
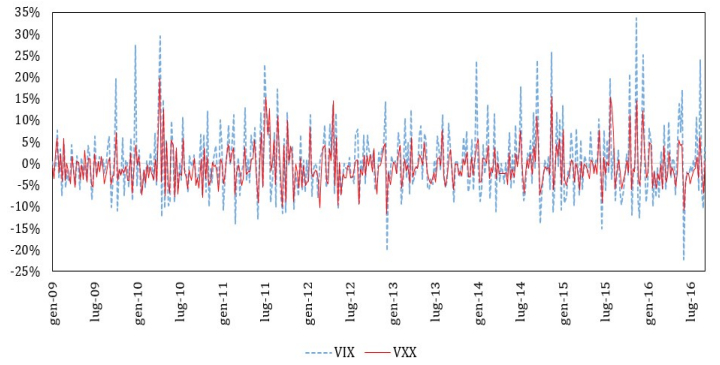
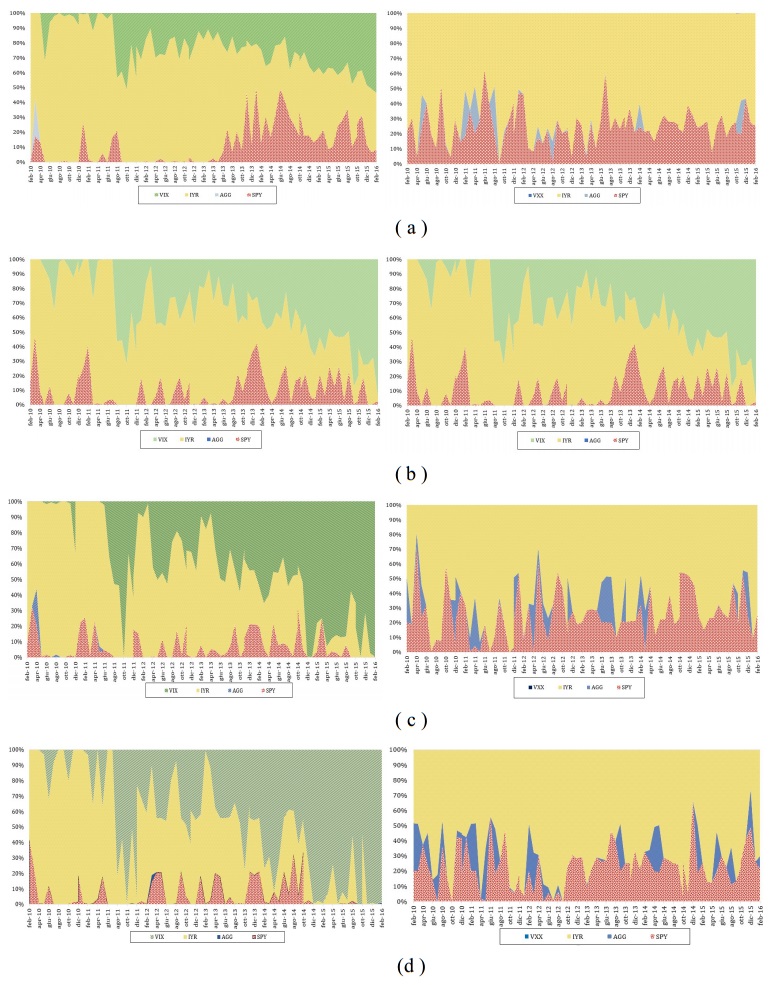
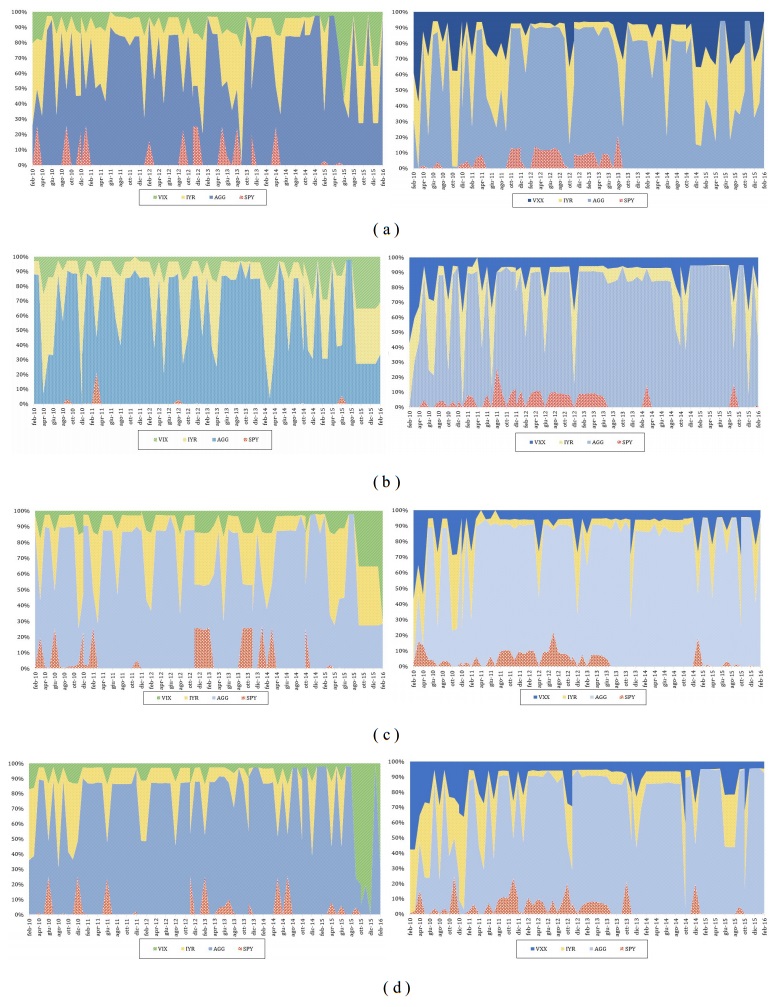
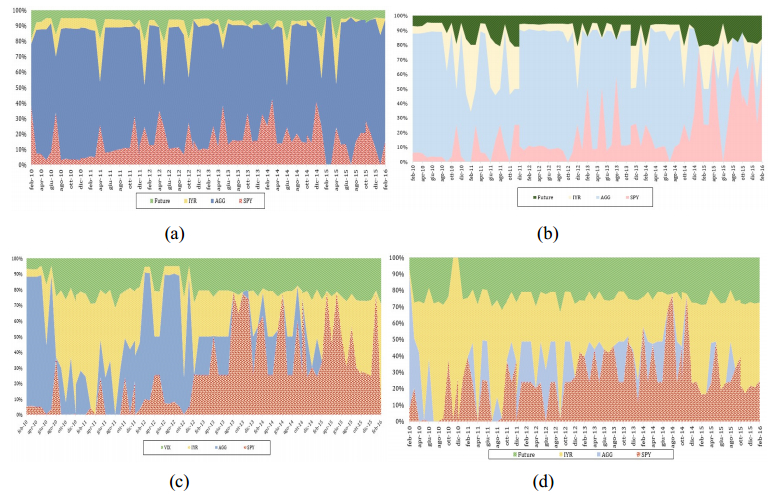
Figures(4) / Tables(9)

Elvira Caloiero, Massimo Guidolin. Volatility as an Alternative Asset Class: Does It Improve Portfolio Performance?[J]. Quantitative Finance and Economics, 2017, 1(4): 334-362. doi: 10.3934/QFE.2017.4.334







 DownLoad:
DownLoad: