Citation: Yiye Jiang, Jérémie Bigot, Edoardo Provenzi. Commutativity of spatiochromatic covariance matrices in natural image statistics[J]. Mathematics in Engineering, 2020, 2(2): 313-339. doi: 10.3934/mine.2020016

| [1] | Attneave F (1954) Some informational aspects of visual perception. Physchol Rev 61: 183-193. |
| [2] | Barlow HB (1961) Possible principles underlying the transformations of sensory messages. Sens Commun 1: 217-234. |
| [3] | Berman A, Plemmons RJ (1987) Nonnegative Matrices in the Mathematical Sciences, SIAM. |
| [4] | Buchsbaum G, Gottschalk A (1983) Trichromacy, opponent colours coding and optimum colour information transmission in the retina. P Roy Soc Lond B Bio 220: 89-113. |
| [5] |
Field DJ (1987) Relations between the statistics of natural images and the response properties of cortical cells. J Opt Soc Am 4: 2379-2394. doi: 10.1364/JOSAA.4.002379

|
| [6] | Frazier MW (2001) Introduction to Wavelets through Linear Algebra, Springer. |
| [7] | Gonzales RC, Woods RE (2002) Digital Image Processing, Prentice Hall. |
| [8] | Gray RM (2006) Toeplitz and circulant matrices: A review. Found Trends Commun Inform Theory 2: 155-239. |
| [9] | Johnson CR, Horn RA (1985) Matrix Analysis. Cambridge: Cambridge University Press. |
| [10] |
Johnson GM, Song X, Montag ED, et al. (2010) Derivation of a color space for image color difference measurement. Color Res Appl 35: 387-400. doi: 10.1002/col.20561
|
| [11] |
MacKay DM (1956) Towards an information-flow model of human behaviour. Brit J Psy 47: 30-43. doi: 10.1111/j.2044-8295.1956.tb00559.x
|
| [12] |
Ohta Y, Kanade T, Sakai T (1980) Color information for region segmentation. Comput Graph Image Process 13: 222-241. doi: 10.1016/0146-664X(80)90047-7
|
| [13] | Olshausen B, Field DJ (1997) Sparse coding with an overcomplete basis set: A strategy employed by v1?. Vision Res 37: 607-609. |
| [14] | Párraga C, Troscianko T, Tolhurst D (2002) Spatiochromatic properties of natural images and human vision. Curr Bio 6: 483-487. |
| [15] | Pratt WK (2007) Digital Image Processing, J. Wiley & Sons. |
| [16] |
Provenzi E, Delon J, Gousseau Y, et al. (2016) On the second order spatiochromatic structure of natural images. Vision Res 120: 22-38. doi: 10.1016/j.visres.2015.02.025
|
| [17] | Rao CR (1973) Linear Statistical Inference and Its Applications, John Wiley and Sons. |
| [18] | Ruderman DL (1996) Origin of scaling in natural images. Vision Res 37: 3385-3398. |
| [19] |
Ruderman DL, Cronin TW, Chiao C (1998) Statistics of cone responses to natural images: Implications for visual coding. J Opt Soc Am A 15: 2036-2045. doi: 10.1364/JOSAA.15.002036
|
| [20] |
Shapley R, Enroth-Cugell C (1984) Visual adaptation and retinal gain controls. Prog Retin Res 3: 263-346. doi: 10.1016/0278-4327(84)90011-7
|
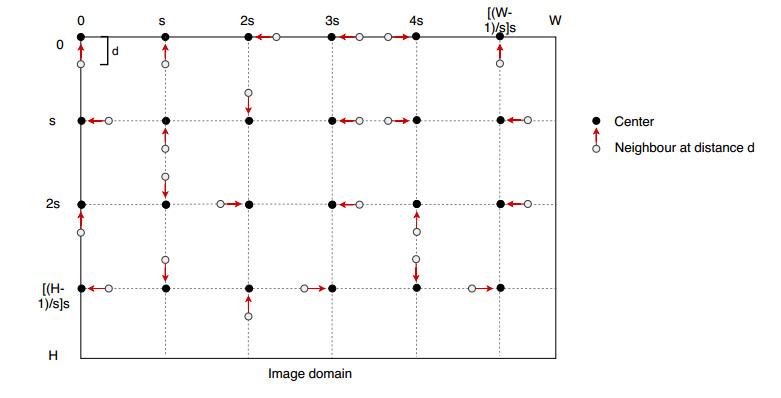
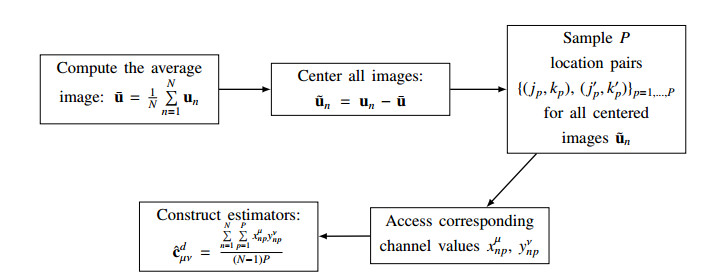
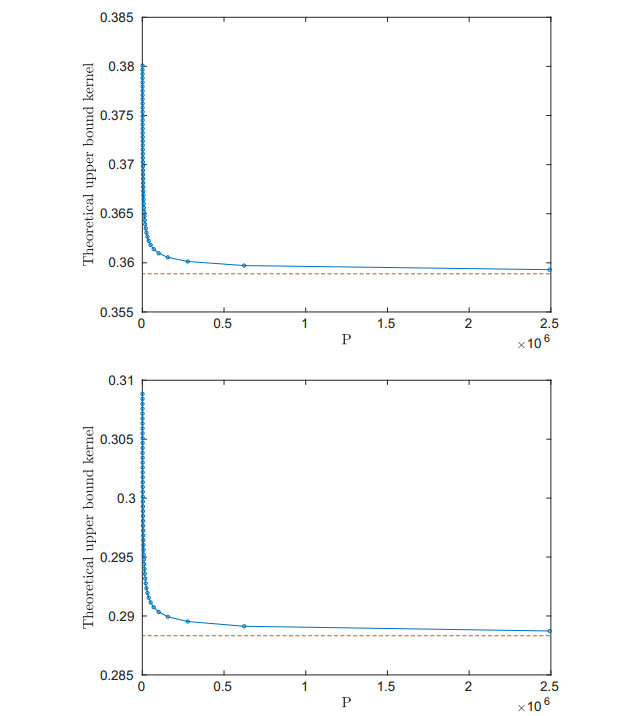

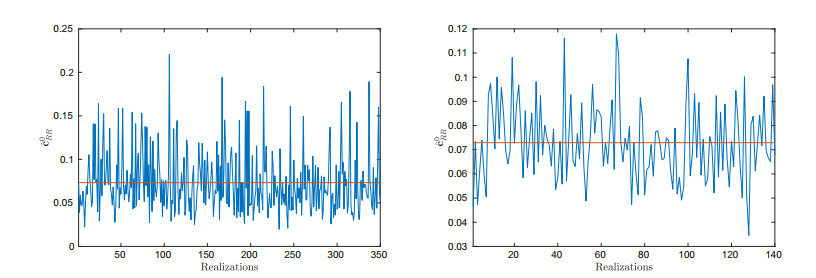

Figures(14) / Tables(1)

Yiye Jiang, Jérémie Bigot, Edoardo Provenzi. Commutativity of spatiochromatic covariance matrices in natural image statistics[J]. Mathematics in Engineering, 2020, 2(2): 313-339. doi: 10.3934/mine.2020016







 DownLoad:
DownLoad: