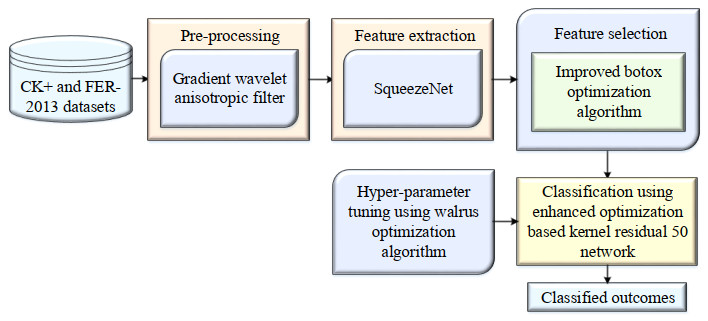
Facial emotion recognition (FER) is largely utilized to analyze human emotion in order to address the needs of many real-time applications such as computer-human interfaces, emotion detection, forensics, biometrics, and human-robot collaboration. Nonetheless, existing methods are mostly unable to offer correct predictions with a minimum error rate. In this paper, an innovative facial emotion recognition framework, termed extended walrus-based deep learning with Botox feature selection network (EWDL-BFSN), was designed to accurately detect facial emotions. The main goals of the EWDL-BFSN are to identify facial emotions automatically and effectively by choosing the optimal features and adjusting the hyperparameters of the classifier. The gradient wavelet anisotropic filter (GWAF) can be used for image pre-processing in the EWDL-BFSN model. Additionally, SqueezeNet is used to extract significant features. The improved Botox optimization algorithm (IBoA) is then used to choose the best features. Lastly, FER and classification are accomplished through the use of an enhanced optimization-based kernel residual 50 (EK-ResNet50) network. Meanwhile, a nature-inspired metaheuristic, walrus optimization algorithm (WOA) is utilized to pick the hyperparameters of EK-ResNet50 network model. The EWDL-BFSN model was trained and tested with publicly available CK+ and FER-2013 datasets. The Python platform was applied for implementation, and various performance metrics such as accuracy, sensitivity, specificity, and F1-score were analyzed with state-of-the-art methods. The proposed EWDL-BFSN model acquired an overall accuracy of 99.37 and 99.25% for both CK+ and FER-2013 datasets and proved its superiority in predicting facial emotions over state-of-the-art methods.
Citation: C Willson Joseph, G. Jaspher Willsie Kathrine, Shanmuganathan Vimal, S Sumathi., Danilo Pelusi, Xiomara Patricia Blanco Valencia, Elena Verdú. Improved optimizer with deep learning model for emotion detection and classification[J]. Mathematical Biosciences and Engineering, 2024, 21(7): 6631-6657. doi: 10.3934/mbe.2024290
Facial emotion recognition (FER) is largely utilized to analyze human emotion in order to address the needs of many real-time applications such as computer-human interfaces, emotion detection, forensics, biometrics, and human-robot collaboration. Nonetheless, existing methods are mostly unable to offer correct predictions with a minimum error rate. In this paper, an innovative facial emotion recognition framework, termed extended walrus-based deep learning with Botox feature selection network (EWDL-BFSN), was designed to accurately detect facial emotions. The main goals of the EWDL-BFSN are to identify facial emotions automatically and effectively by choosing the optimal features and adjusting the hyperparameters of the classifier. The gradient wavelet anisotropic filter (GWAF) can be used for image pre-processing in the EWDL-BFSN model. Additionally, SqueezeNet is used to extract significant features. The improved Botox optimization algorithm (IBoA) is then used to choose the best features. Lastly, FER and classification are accomplished through the use of an enhanced optimization-based kernel residual 50 (EK-ResNet50) network. Meanwhile, a nature-inspired metaheuristic, walrus optimization algorithm (WOA) is utilized to pick the hyperparameters of EK-ResNet50 network model. The EWDL-BFSN model was trained and tested with publicly available CK+ and FER-2013 datasets. The Python platform was applied for implementation, and various performance metrics such as accuracy, sensitivity, specificity, and F1-score were analyzed with state-of-the-art methods. The proposed EWDL-BFSN model acquired an overall accuracy of 99.37 and 99.25% for both CK+ and FER-2013 datasets and proved its superiority in predicting facial emotions over state-of-the-art methods.

| [1] | S. K. Singh, R. K. Thakur, S. Kumar, R. Anand, Deep learning and machine learning based facial emotion detection using CNN, in 2022 9th International Conference on Computing for Sustainable Global Development (INDIACom), New Delhi, India, (2022), 530–535. https://doi.org/10.23919/INDIACom54597.2022.9763165 |
| [2] |
A. R. Khan, Facial emotion recognition using conventional machine learning and deep learning methods: current achievements, analysis and remaining challenges, Information, 13 (2022), 268. https://doi.org/10.3390/info13060268 doi: 10.3390/info13060268

|
| [3] |
V. M. Joshi, R. B. Ghongade, A. M. Joshi, R. V. Kulkarni, Deep BiLSTM neural network model for emotion detection using cross-dataset approach, Biomed. Signal Process. Control, 73 (2022), 103407. https://doi.org/10.1016/j.bspc.2021.103407 doi: 10.1016/j.bspc.2021.103407
|
| [4] |
A. Aggarwal, A. Srivastava, A. Agarwal, N. Chahal, D. Singh, A. A. Alnuaim, et al., Two-way feature extraction for speech emotion recognition using deep learning, Sensors, 22 (2022), 2378. https://doi.org/10.3390/s22062378 doi: 10.3390/s22062378
|
| [5] |
M. F. Bashir, A. R. Javed, M. U. Arshad, T. R. Gadekallu, W. Shahzad, M. O. Beg, Context-aware emotion detection from low-resource URDU language using deep neural network, ACM Trans. Asian Low-Resour. Lang. Inf. Process., 22 (2023), 1–30. https://doi.org/10.1145/3528576 doi: 10.1145/3528576
|
| [6] |
I. Lasri, A. Riadsolh, M. Elbelkacemi, Facial emotion recognition of deaf and hard-of-hearing students for engagement detection using deep learning, Educ. Inf. Technol., 28 (2023), 4069–4092. https://doi.org/10.1007/s10639-022-11370-4 doi: 10.1007/s10639-022-11370-4
|
| [7] |
M. Mukhiddinov, O. Djuraev, F. Akhmedov, A. Mukhamadiyev, J. Cho, Masked face emotion recognition based on facial landmarks and deep learning approaches for visually impaired people, Sensors, 23 (2023), 1080. https://doi.org/10.3390/s23031080 doi: 10.3390/s23031080
|
| [8] |
F. M. Talaat, Z. H. A. Zainab, R. R. Mostafa, N. El-Rashidy, Real-time facial emotion recognition model based on kernel autoencoder and convolutional neural network for autism children, Soft Comput., 28 (2024), 1–14. https://doi.org/10.21203/rs.3.rs-2387030/v1 doi: 10.21203/rs.3.rs-2387030/v1
|
| [9] |
B. Sowmya, S. A. Alex, A. Kanavalli, S. Supreeth, G. Shruthi, S. Rohith, Machine learning model for emotion detection and recognition using an enhanced convolutional neural network, J. Integr. Sci. Technol., 12 (2024), 786. https://doi.org/10.62110/sciencein.jist.2024.v12.786 doi: 10.62110/sciencein.jist.2024.v12.786
|
| [10] |
B. Bakariya, A. Singh, H. Singh, P. Raju, R. Rajpoot, K. K. Mohbey, Facial emotion recognition and music recommendation system using CNN-based deep learning techniques, Evol. Syst., 15 (2024), 641–658. https://doi.org/10.1007/s12530-023-09506-z doi: 10.1007/s12530-023-09506-z
|
| [11] | K. Jhadi, N. Tiwari, M. Chawla, Review of machine and deep learning techniques for expression based facial emotion recognition, in 2024 IEEE International Students' Conference on Electrical, Electronics and Computer Science (SCEECS), Bhopal, India, (2024), 1–6. https://doi.org/10.1109/SCEECS61402.2024.10482176 |
| [12] |
H. B. U. Haq, W. Akram, M. N. Irshad, A. Kosar, M. Abid, Enhanced real-time facial expression recognition using deep learning, Acadlore Trans. AI Mach. Learn., 3 (2024), 24–35. https://doi.org/10.56578/ataiml030103 doi: 10.56578/ataiml030103
|
| [13] | A. Jaiswal, A. K. Raju, S. Deb, Facial emotion detection using deep learning, in 2020 international conference for emerging technology (INCET), Belgaum, India, (2020), 1–5. https://doi.org/10.1109/INCET49848.2020.9154121 |
| [14] | E. Pranav, S. Kamal, C. S. Chandran, M. H. Supriya, Facial emotion recognition using deep convolutional neural network, in 2020 6th International Conference on Advanced Computing and Communication Systems (ICACCS), Coimbatore, India, (2020), 317–320. https://doi.org/10.1109/ICACCS48705.2020.9074302 |
| [15] |
W. Mellouk, W. Handouzi, Facial emotion recognition using deep learning: review and insights, Procedia Comput. Sci., 175 (2020), 689–694. https://doi.org/10.1016/j.procs.2020.07.101 doi: 10.1016/j.procs.2020.07.101
|
| [16] |
S. A. Hussain, A. S. A. Al Balushi, A real time face emotion classification and recognition using deep learning model, J. Phys. Conf. Ser., 1432 (2020), 012087. https://doi.org/10.1088/1742-6596/1432/1/012087 doi: 10.1088/1742-6596/1432/1/012087
|
| [17] |
M. A. H. Akhand, S. Roy, N. Siddique, M. A. S. Kamal, T. Shimamura, Facial emotion recognition using transfer learning in the deep CNN, Electronics, 10 (2021), 1036. https://doi.org/10.3390/electronics10091036 doi: 10.3390/electronics10091036
|
| [18] |
M. K. Chowdary, T. N. Nguyen, D. J. Hemanth, Deep learning-based facial emotion recognition for human–computer interaction applications, Neural Comput. Appl., 35 (2023), 23311–23328. https://doi.org/10.1007/s00521-021-06012-8 doi: 10.1007/s00521-021-06012-8
|
| [19] | I. P. R. E. Wicaksana, G. R. Davinsi, M. A. Afriyanto, A. Wibowo, P. A. Suri, Systematic literature review: The influence and effectiveness of deep learning in image processing for emotion recognition, 2024. https://doi.org/10.21203/rs.3.rs-3856084/v1 |
| [20] |
G. Meena, K. K. Mohbey, A. Indian, M. Z. Khan, S. Kumar, Identifying emotions from facial expressions using a deep convolutional neural network-based approach, Multimedia Tools Appl., 83 (2024), 15711–15732. https://doi.org/10.1007/s11042-023-16174-3 doi: 10.1007/s11042-023-16174-3
|
| [21] |
A. A. Alzahrani, Bioinspired image processing enabled facial emotion recognition using equilibrium optimizer with a hybrid deep learning model, IEEE Access, 12 (2024), 22219–22229. https://doi.org/10.1109/ACCESS.2024.3359436 doi: 10.1109/ACCESS.2024.3359436
|
| [22] |
H. Tao, Q. Duan, Hierarchical attention network with progressive feature fusion for facial expression recognition, Neural Networks, 170 (2024), 337–348. https://doi.org/10.1016/j.neunet.2023.11.033 doi: 10.1016/j.neunet.2023.11.033
|
| [23] |
F. M. Alamgir, M. S. Alam, An artificial intelligence driven facial emotion recognition system using hybrid deep belief rain optimization, Multimedia Tools Appl., 82 (2023), 2437–2464. https://doi.org/10.1007/s11042-022-13378-x doi: 10.1007/s11042-022-13378-x
|
| [24] |
P. M. A. Kumar, J. B. Maddala, K. M. Sagayam, Enhanced facial emotion recognition by optimal descriptor selection with neural network, IETE J. Res., 69 (2023), 2595–2614. https://doi.org/10.1080/03772063.2021.1902868 doi: 10.1080/03772063.2021.1902868
|
| [25] |
N. Kumari, R. Bhatia, Efficient facial emotion recognition model using deep convolutional neural network and modified joint trilateral filter, Soft Comput., 26 (2022), 7817–7830. https://doi.org/10.1007/s00500-022-06804-7 doi: 10.1007/s00500-022-06804-7
|
| [26] | B. Koonce, B. E. Koonce, Convolutional Neural Networks with Swift for Tensorflow: Image Recognition and Dataset Categorization, USA: Apress, New York, NY, (2021), 109–123. https://doi.org/10.1007/978-1-4842-6168-2_10 |
| [27] | F. N. Iandola, S. Han, M. W. Moskewicz, K. Ashraf, W. J. Dally, K. Keutzer, SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and < 0.5 MB model size, preprint, arXiv: 1602.07360. |
| [28] | W. Liu, D. Anguelov, D. Erhan, C. Szegedy, S. Reed, C. Y. Fu, et al., SSD: Single shot multibox detector, in Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, Proceedings, Part I, Springer International Publishing, The Netherlands, 14 (2016), 21–37. https://doi.org/10.1007/978-3-319-46448-0_2 |
| [29] |
M. Hubálovská, Š. Hubálovský, P. Trojovský, Botox optimization algorithm: a new human-based metaheuristic algorithm for solving optimization problems, Biomimetics, 9 (2024), 137. https://doi.org/10.3390/biomimetics9030137 doi: 10.3390/biomimetics9030137
|
| [30] |
W. Islam, M. Jones, R. Faiz, N. Sadeghipour, Y. Qiu, B. Zheng, Improving performance of breast lesion classification using a ResNet50 model optimized with a novel attention mechanism, Tomography, 8 (2022), 2411–2425. https://doi.org/10.3390/tomography8050200 doi: 10.3390/tomography8050200
|
| [31] |
P. Luo, R. Zhang, J. Ren, Z. Peng, J. Li, Switchable normalization for learning-to-normalize deep representation, IEEE Trans. Pattern Anal. Mach. Intell., 43 (2019), 712–728. https://doi.org/10.1109/TPAMI.2019.2932062 doi: 10.1109/TPAMI.2019.2932062
|
| [32] |
M. Han, Z. Du, K. F. Yuen, H. Zhu, Y. Li, Q. Yuan, Walrus optimizer: A novel nature-inspired metaheuristic algorithm, Expert Syst. Appl., 239 (2024), 122413. https://doi.org/10.1016/j.eswa.2023.122413 doi: 10.1016/j.eswa.2023.122413
|
| [33] | I. J. Goodfellow, D. Erhan, P. L. Carrier, A. Courville, M. Mirza, B. Hamner, et al., Challenges in representation learning: A report on three machine learning contests, in Neural Information Processing: 20th International Conference, ICONIP 2013, Proceedings, Part Ⅲ, Springer-Verlag Berlin Heidelberg, Daegu, Korea, 20 (2013), 117–124. https://doi.org/10.1007/978-3-642-42051-1_16 |
| [34] | P. Lucey, J. F. Cohn, T. Kanade, J. Saragih, Z. Ambadar, I. Matthews, The extended Cohn-Kanade dataset (CK+): A complete dataset for action unit and emotion-specified expression, in 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition-Workshops, San Francisco, CA, USA, (2010), 94–101. https://doi.org/10.1109/CVPRW.2010.5543262 |
| [35] |
H. N. AlEisa, F. Alrowais, N. Negm, N. Almalki, M. Khalid, R. Marzouk, et al., Henry gas solubility optimization with deep learning based facial emotion recognition for human computer interface, IEEE Access, 11 (2023), 62233–62241. https://doi.org/10.1109/ACCESS.2023.3284457 doi: 10.1109/ACCESS.2023.3284457
|
| [36] |
S. Benisha, T. T. Mirnalinee, Human facial emotion recognition using deep neural networks, Int. Arab J. Inf. Technol., 20 (2023), 303–309. https://doi.org/10.34028/iajit/20/3/2 doi: 10.34028/iajit/20/3/2
|
| [37] |
A. J. Obaid, H. K. Alrammahi, An intelligent facial expression recognition system using a hybrid deep convolutional neural network for multimedia applications, Appl. Sci., 13 (2023), 12049. https://doi.org/10.3390/app132112049 doi: 10.3390/app132112049
|
| [38] |
Y. Yaddaden, An efficient facial expression recognition system with appearance-based fused descriptors, Intell. Syst. Appl., 17 (2023), 200166. https://doi.org/10.1016/j.iswa.2022.200166 doi: 10.1016/j.iswa.2022.200166
|
| [39] |
A. Barman, P. Dutta, Facial expression recognition using distance and shape signature features, Pattern Recognit. Lett., 145 (2021), 254–261. https://doi.org/10.1016/j.patrec.2017.06.018 doi: 10.1016/j.patrec.2017.06.018
|
| [40] |
S. Hossain, S. Umer, R. K. Rout, M. Tanveer, Fine-grained image analysis for facial expression recognition using deep convolutional neural networks with bilinear pooling, Appl. Soft Comput., 134 (2023), 109997. https://doi.org/10.1016/j.asoc.2023.109997 doi: 10.1016/j.asoc.2023.109997
|
| [41] |
M. Parimala, R. M. S. Priya, M. P. K. Reddy, C. L. Chowdhary, R. K. Poluru, S. Khan, Spatiotemporal‐based sentiment analysis on tweets for risk assessment of event using deep learning approach, Softw.: Pract. Exper., 51 (2021), 550–570. https://doi.org/10.1002/spe.2851 doi: 10.1002/spe.2851
|
| [42] | P. Babajee, G. Suddul, S. Armoogum, R. Foogooa, Identifying human emotions from facial expressions with deep learning, in 2020 Zooming Innovation in Consumer Technologies Conference (ZINC), (2020), 36–39. https://doi.org/10.1109/ZINC50678.2020.9161445 |
| [43] | Y. Tai, Y. Tan, W. Gong, H. Huang, Bayesian convolutional neural networks for seven basic facial expression classifications, preprint, arXiv: 2107.04834. |
| [44] |
N. K. Benamara, M. Val-Calvo, J. R. Alvarez-Sanchez, A. Diaz-Morcillo, J. M. Ferrandez-Vicente, E. Fernandez-Jover, et al., Real-time facial expression recognition using smoothed deep neural network ensemble, Integr. Comput.-Aided Eng., 28 (2021), 97–111. https://doi.org/10.3233/ICA-200643 doi: 10.3233/ICA-200643
|
| [45] |
Y. Said, M. Barr, Human emotion recognition based on facial expressions via deep learning on high-resolution images, Multimedia Tools Appl., 80 (2021), 25241–25253. https://doi.org/10.1007/s11042-021-10918-9 doi: 10.1007/s11042-021-10918-9
|
| [46] |
S. Gupta, P. Kumar, R. K. Tekchandani, Facial emotion recognition based real-time learner engagement detection system in online learning context using deep learning models, Multimedia Tools Appl., 82 (2023), 11365–11394. https://doi.org/10.1007/s11042-022-13558-9 doi: 10.1007/s11042-022-13558-9
|
| [47] |
G. Castellano, B. De Carolis, N. Macchiarulo, Automatic facial emotion recognition at the COVID-19 pandemic time, Multimedia Tools Appl., 82 (2023), 12751–12769. https://doi.org/10.1007/s11042-022-14050-0 doi: 10.1007/s11042-022-14050-0
|








Figures(9) / Tables(6)

C Willson Joseph, G. Jaspher Willsie Kathrine, Shanmuganathan Vimal, S Sumathi., Danilo Pelusi, Xiomara Patricia Blanco Valencia, Elena Verdú. Improved optimizer with deep learning model for emotion detection and classification[J]. Mathematical Biosciences and Engineering, 2024, 21(7): 6631-6657. doi: 10.3934/mbe.2024290







 DownLoad:
DownLoad: