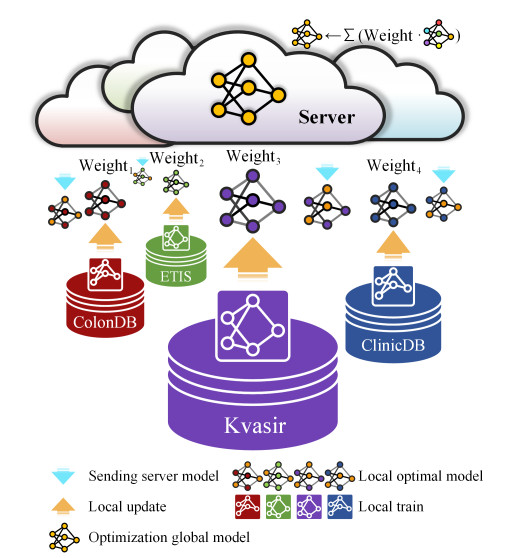
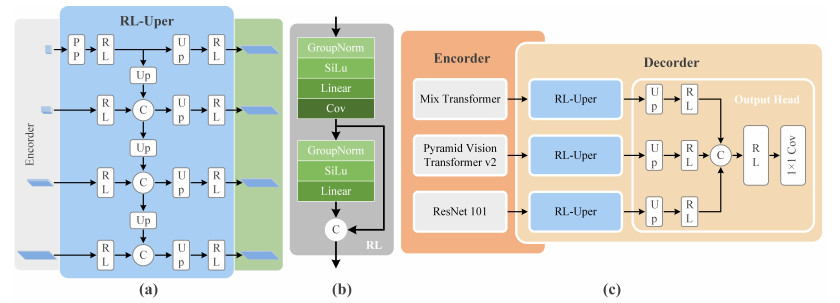
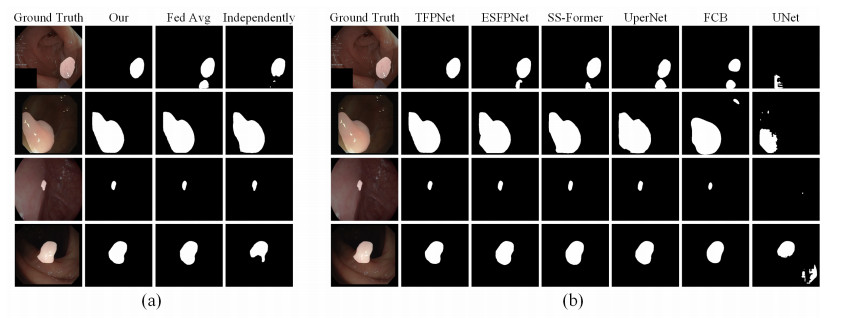
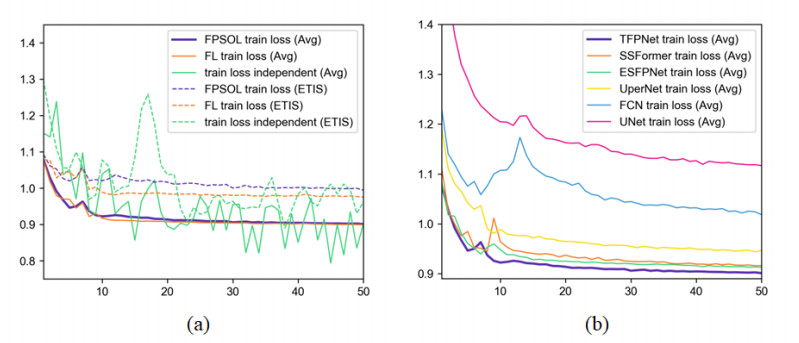
Deep learning technology has shown considerable potential in various domains. However, due to privacy issues associated with medical data, legal and ethical constraints often result in smaller datasets. The limitations of smaller datasets hinder the applicability of deep learning technology in the field of medical image processing. To address this challenge, we proposed the Federated Particle Swarm Optimization algorithm, which is designed to increase the efficiency of decentralized data utilization in federated learning and to protect privacy in model training. To stabilize the federated learning process, we introduced Tri-branch feature pyramid network (TFPNet), a multi-branch structure model. TFPNet mitigates instability during the aggregation model deployment and ensures fast convergence through its multi-branch structure. We conducted experiments on four different public datasets$ \colon $ CVC-ClinicDB, Kvasir, CVC-ColonDB and ETIS-LaribPolypDB. The experimental results show that the Federated Particle Swarm Optimization algorithm outperforms single dataset training and the Federated Averaging algorithm when using independent scattered data, and TFPNet converges faster and achieves superior segmentation accuracy compared to other models.
Citation: Kefeng Fan, Cun Xu, Xuguang Cao, Kaijie Jiao, Wei Mo. Tri-branch feature pyramid network based on federated particle swarm optimization for polyp segmentation[J]. Mathematical Biosciences and Engineering, 2024, 21(1): 1610-1624. doi: 10.3934/mbe.2024070
Deep learning technology has shown considerable potential in various domains. However, due to privacy issues associated with medical data, legal and ethical constraints often result in smaller datasets. The limitations of smaller datasets hinder the applicability of deep learning technology in the field of medical image processing. To address this challenge, we proposed the Federated Particle Swarm Optimization algorithm, which is designed to increase the efficiency of decentralized data utilization in federated learning and to protect privacy in model training. To stabilize the federated learning process, we introduced Tri-branch feature pyramid network (TFPNet), a multi-branch structure model. TFPNet mitigates instability during the aggregation model deployment and ensures fast convergence through its multi-branch structure. We conducted experiments on four different public datasets$ \colon $ CVC-ClinicDB, Kvasir, CVC-ColonDB and ETIS-LaribPolypDB. The experimental results show that the Federated Particle Swarm Optimization algorithm outperforms single dataset training and the Federated Averaging algorithm when using independent scattered data, and TFPNet converges faster and achieves superior segmentation accuracy compared to other models.

| [1] |
J. Silva, A. Histace, O. Romain, X. Dray, B. Granado, Toward embedded detection of polyps in WCE images for early diagnosis of colorectal cancer, Int. J. Comput. Assisted Radiol. Surg., 9 (2013), 283–293. https://doi.org/10.1007/s11548-013-0926-3 doi: 10.1007/s11548-013-0926-3

|
| [2] |
E. Salmo, N. Haboubi, Adenoma and malignant colorectal polyp: pathological considerations and clinical applications, Gastroenterology, 7 (2018), 92–102. https://doi.org/10.33590/emjgastroenterol/10313443 doi: 10.33590/emjgastroenterol/10313443
|
| [3] |
J. H. Bond, Polyp guideline: diagnosis, treatment, and surveillance for patients with colorectal polyps, Off. J. Am. Coll. Gastroenterol., 95 (2000), 3053–3063. https://doi.org/10.7326/0003-4819-119-8-199310150-00010 doi: 10.7326/0003-4819-119-8-199310150-00010
|
| [4] | K. Wallace, H. M. Brandt, J. D. Bearden, Race and prevalence of large bowel polyps among the low-income and uninsured in South Carolina, Dig. Dis. Sci., 61 (2016), 265–272. |
| [5] | M. Akbari, M. Mohrekesh, E. Nasr-Esfahani, S. M. Reza Soroushmehr, N. Karimi, S. Samavi, et al., Polyp segmentation in colonoscopy images using fully convolutional network, in 2018 40th Annual International Conference of the IEEE Engineering in Medicine and Biology Society, 2018. https://doi.org/10.1109/embc.2018.8512197 |
| [6] |
R. Bezen, Y. Edan, I. Halachmi, Computer vision system for measuring individual cow feed intake using RGB-D camera and deep learning algorithms, Comput. Electron. Agric., 172 (2020), 105345. https://doi.org/10.1016/j.compag.2020.105345 doi: 10.1016/j.compag.2020.105345
|
| [7] | Y. Chen, X. Sun, Y. Jin, Communication-efficient federated deep learning with layerwise asynchronous model update and temporally weighted aggregation, IEEE Trans. Neural Netw. Learn. Syst., 30 (2019), 4229–4238. |
| [8] | L. Li, Y. Fan, M. Tse, K. Y. Lin A review of applications in federated learning, Comput. Industr. Eng., 149 (2020), 106854. |
| [9] |
T. Wang, Y. Du, Y. Gong, K. R. Choo, Y. Guo, Applications of federated learning in mobile health: scoping review, J. Med. Int. Res., 25 (2023), e43006. https://doi.org/10.2196/43006 doi: 10.2196/43006
|
| [10] | Q. Yang, Y. Liu, T. Chen, Y. Tong, Federated machine learning: concept and applications, ACM Trans. Intell. Syst. Technol., 10 (2019), 1–19. |
| [11] |
S. Feng, B. Li, H. Yu, Y. Liu, Q. Yang, Semi-supervised federated heterogeneous transfer learning, Knowl. Based Syst., 252 (2022), 109384. https://doi.org/10.1016/j.knosys.2022.109384 doi: 10.1016/j.knosys.2022.109384
|
| [12] |
X. Yin, Y. Zhu, J. Hu, A comprehensive survey of privacy-preserving federated learning: A taxonomy, review, and future directions, ACM Comput. Surv., 54 (2021), 1–36. https://doi.org/10.1145/3460427 doi: 10.1145/3460427
|
| [13] |
Y. Zhang, Y. Hu, X. Gao, D. Gong, Y. Guo, An embedded vertical‐federated feature selection algorithm based on particle swarm optimisation, CAAI Trans. Intell. Technol., 8 (2023), 734–754. https://doi.org/10.1049/cit2.12122 doi: 10.1049/cit2.12122
|
| [14] |
X. Wang, W. Chen, J. Xia, Z. Wen, R. Zhu, T. Schreck, HetVis: A visual analysis approach for identifying data heterogeneity in horizontal federated learning, IEEE Trans. Visual. Comput. Graph., 29 (2022), 310–319. https://doi.org/10.1109/tvcg.2022.3209347 doi: 10.1109/tvcg.2022.3209347
|
| [15] |
X. You, X. Liu, X. Lin, J. Cai, S. Chen, Accuracy degrading: toward participation-fair federated learning, IEEE Int. Things J., 10 (2023) 10291–10306. https://doi.org/10.1109/jiot.2023.3238038 doi: 10.1109/jiot.2023.3238038
|
| [16] |
Y. Li, Y. Chen, K. Zhu, C. Bai, J. Zhang, An effective federated learning verification strategy and its applications for fault diagnosis in industrial IoT systems, IEEE Int. Things J., 9 (2022), 16835–16849. https://doi.org/10.1109/jiot.2022.3153343 doi: 10.1109/jiot.2022.3153343
|
| [17] |
Q. Abbas, K. M. Malik, A. K. J. Saudagar, M. B. Khan, Context-aggregator: An approach of loss-and class imbalance-aware aggregation in federated learning, Comput. Biol. Med., 163 (2023), 107167. https://doi.org/10.1016/j.compbiomed.2023.107167 doi: 10.1016/j.compbiomed.2023.107167
|
| [18] |
H. Ye, L. Liang, G. Y. Li, Decentralized federated learning with unreliable communications, IEEE J. Selected Topics Signal Process., 16 (2022), 487–500. https://doi.org/10.1109/jstsp.2022.3152445 doi: 10.1109/jstsp.2022.3152445
|
| [19] |
X. Yu, L. Li, X. He, S. Chen, L. Jiang, Federated learning optimization algorithm for automatic weight optimal, Comput. Intell. Neurosci., 2022 (2022), 19. https://doi.org/10.1155/2022/8342638 doi: 10.1155/2022/8342638
|
| [20] |
L. Liu, K. Fan, M. Yang, Federated learning: a deep learning model based on resnet18 dual path for lung nodule detection, Multim. Tools Appl., 82 (2023), 17437–17450. https://doi.org/10.1007/s11042-022-14107-0 doi: 10.1007/s11042-022-14107-0
|
| [21] |
Y. Hu, Y. Zhang, D. Gong, X. Sun, Multiparticipant federated feature selection algorithm with particle swarm optimization for imbalanced data under privacy protection, IEEE Trans. Artif. Intell., 4 (2023), 1002–1016. https://doi.org/10.1109/TAI.2022.3145333 doi: 10.1109/TAI.2022.3145333
|
| [22] |
K. Hu, W. Chen, Y. Z. Sun, X. Hu, Q. Zhou, Z. Zheng, PPNet: pyramid pooling based network for polyp segmentation, Comput. Biol. Med., 160 (2023), 107028. https://doi.org/10.1016/j.compbiomed.2023.107028 doi: 10.1016/j.compbiomed.2023.107028
|
| [23] | G. Liu, M. Zhao, L. Bai, Z. Guo, Cooperation of boundary attention and negative matrix L1 regularization loss function for polyp segmentation, in 26th International Conference on Pattern Recognition, (2022), 82–88. https://doi.org/10.1109/ICPR56361.2022.9956700 |
| [24] | D. Wang, S. Chen, X. Sun, Q. Chen, AFP-Mask: anchor-free polyp instance segmentation in colonoscopy, IEEE J. Biomed. Health Inform., 26 (2022), 2995–3006. |
| [25] | L Shi, Z Li, J Li, Y Wang, H Wang, Y Guo, AGCNet: a Precise adaptive global context network for real-time colonoscopy, IEEE Access, 11 (2023), 59002–59015. |
| [26] | T. Shen, X. Li, Automatic polyp image segmentation and cancer prediction based on deep learning, Frontiers Oncol., 12 (2023), 1087438. |
| [27] | P. Sharma, A. Gautam, P. Maji, Li-SegPNet: encoder-decoder mode lightweight segmentation network for colorectal polyps analysis, IEEE Trans. Biomed. Eng., 70 (2022), 1330–1339. |
| [28] | J. Wang, Q. Huang, F. Tang, J. Meng, J. Su, S. Song, Stepwise feature fusion: local guides global, in International Conference on Medical Image Computing and Computer-Assisted Intervention, (2022), 110–120. https://doi.org/10.1007/978-3-031-16437-8_11 |
| [29] |
Q. Chang, D. Ahmad, J. Toth, R. Bascom, W. E. Higgins, ESFPNet: efficient deep learning architecture for real-time lesion segmentation in autofluorescence bronchoscopic video, Med. Imaging 2023, 12468 (2023), 1246803. https://doi.org/10.1117/12.2647897 doi: 10.1117/12.2647897
|
| [30] | B. McMahan, E. Moore, D. Ramage, S. Hampson, B. A. Y. Arcas, Communication-efficient learning of deep networks from decentralized data, Artif. Intell. Stat., (2017), 1273–1282. |
| [31] |
E. H. Houssein, A. Sayed, Boosted federated learning based on improved particle swarm optimization for healthcare IoT devices, Comput. Biol. Med., 163 (2023), 107195. https://doi.org/10.1016/j.compbiomed.2023.107195 doi: 10.1016/j.compbiomed.2023.107195
|
| [32] | J. Kennedy, R. Eberhart, Particle swarm optimization, in Proceedings of ICNN'95-international conference on neural networks., 4 (1995), 1942–1948. |
| [33] |
L. Xu, H. Sun, H. Zhao, W. Zhang, H. Ning, H. Guan, Accurate and efficient federated-learning-based edge intelligence for effective video analysis, IEEE Int. Things J., 10 (2023), 12169–12177. https://doi.org/10.1109/jiot.2023.3241039 doi: 10.1109/jiot.2023.3241039
|
| [34] | T. Xiao, Y. Liu, B. Zhou, Y. Jiang, J. Sun, Unified perceptual parsing for scene understanding, in Proceedings of the European conference on computer vision, (2018), 418–434. |
| [35] |
W. Wang, E. Xie, X. Li, D. P. Fan, K. Song, D. Liang, et al., PVTv2: improved baselines with pyramid vision transformer, Comput. Visual Media, 8 (2022), 415–424. https://doi.org/10.1007/s41095-022-0274-8 doi: 10.1007/s41095-022-0274-8
|
| [36] | Q. Chen, Q. Wu, J. Wang, Q. Hu, T. Hu, E. Ding, et al., MixFormer: mixing features across windows and dimensions, in 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition, (2022), 5249–5259. https://doi.org/10.1109/cvpr52688.2022.00518 |
| [37] | K. He, X. Zhang, S. Ren, J. Sun, Deep residual learning for image recognition, in 2016 IEEE Conference on Computer Vision and Pattern Recognition, (2016), 770–778. https://doi.org/10.1109/cvpr.2016.90 |
| [38] |
J. Bernal, F. J. Sánchez, G. Fernández-Esparrach, D. Gil, C. Rodríguez, F. Vilariño, WM-DOVA maps for accurate polyp highlighting in colonoscopy: validation vs. saliency maps from physicians, Comput. Med. Imaging Graph., 43 (2015), 99–111. https://doi.org/10.1016/j.compmedimag.2015.02.007 doi: 10.1016/j.compmedimag.2015.02.007
|
| [39] |
N. Tajbakhsh, S. R. Gurudu, J. Liang, Automated polyp detection in colonoscopy videos using shape and context information, IEEE Transactions on Medical Imaging., 35 (2015), 630–644. https://doi.org/10.1109/tmi.2015.2487997 doi: 10.1109/tmi.2015.2487997
|
| [40] |
D. Jha, P. H. Smedsrud, M. A. Riegler, P. Halvorsen, T. D. Lange, D. Johansen, et al., Kvasir-SEG: a segmented polyp dataset, MultiMedia Modeling, (2020), 451–462. https://doi.org/10.1007/978-3-030-37734-2_37 doi: 10.1007/978-3-030-37734-2_37
|
| [41] | J. Long, E. Shelhamer, T. Darrell, Fully convolutional networks for semantic segmentation, in Proceedings of the IEEE conference on computer vision and pattern recognition, (2015), 3431–3440. https://doi.org/10.1109/TPAMI.2016.2572683 |
| [42] | O. Ronneberger, P. Fischer, T. Brox, U-net: convolutional networks for biomedical image segmentation, in Medical Image Computing and Computer-Assisted Intervention – MICCAI 2015, (2015), 234–241. https://doi.org/10.1007/978-3-319-24574-4_28 |
Figures(4) / Tables(3)

Kefeng Fan, Cun Xu, Xuguang Cao, Kaijie Jiao, Wei Mo. Tri-branch feature pyramid network based on federated particle swarm optimization for polyp segmentation[J]. Mathematical Biosciences and Engineering, 2024, 21(1): 1610-1624. doi: 10.3934/mbe.2024070







 DownLoad:
DownLoad: